
Data scientists help companies make solid data-backed decisions. Its also a relatively new career, residing at the intersection of social science, statistics, computer science and design fields. This job also happens to be the fastest-growing job in the United States, according to LinkedIn. Data science skills and job role has witnessed a growth of 6.5 times from 2012 and there are more than 6,000 data scientists jobs currently listed on LinkedIn. Apart from that Data Science job role also commands a lucrative median salary of $113,000 among other fast-growing career paths.
While the job market continues to grow, the demand for data scientists directly results from the shortage of workers. As per a report by McKinsey, we might soon see a shortage of up to 250,000 data scientists. Hence, it would be very interesting to look at the type of skills that someone needs to master in order to become a data scientist.
The skills required for a data scientist are as follows. They must have good knowledge of data visualization and data processing. Cloud computing is a must and they must be flexible to work with different types of cloud-based systems. Understanding the problem and easy problem-solving solutions is a plus.
Since JobsPikr extracts job data from some of the popular job boards, we selected the job listings posted in March 2018 on Dice.com. The next step involved segregating the job ads with the job title as “Data Scientist skills”. Finally, we got a data set of close to 8,000 job listings for data scientists in the US region.
In order to analyze the skills required for this role, we found out the terms present in the “job requirement” section of the job ad. Here is a sample job ad for a better perspective:
Then, we moved to the count of terms of various skills and calculated the percentage of occurrence of these skills in the total number of job listings. Given below is the chart that shows the key skills found in the job ads for data scientists.
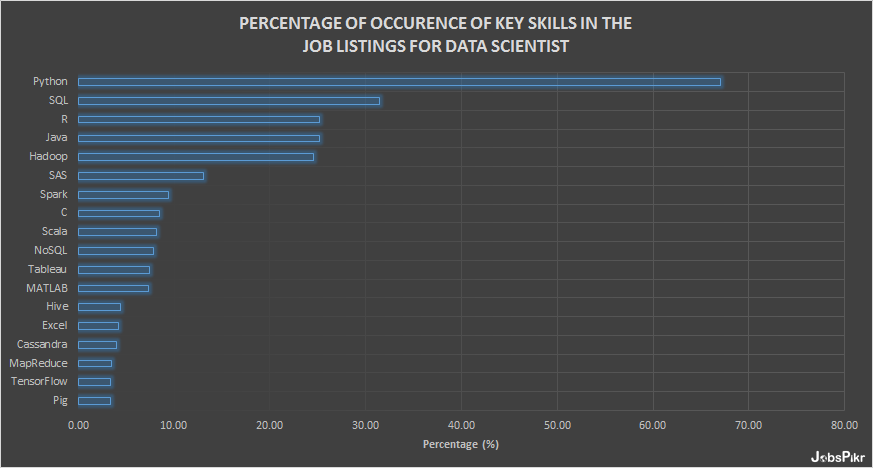
Let’s now go through these skills individually:
Data Science Skills – A Detailed Look
1. Python
Python has amassed a lot of interest recently as a choice of language for data scientists. Here the factors that make it popular in the data science field:
- Open Source a free to install
- Rich community
- Lower learning curve
- Powerful libraries for data analytics
- Easier integration with databases
For example, scikit-learnis used for machine learning algorithms, PyBrainfor building Neural Networks, matplotlibfor plotting and iPython notebooks to present the analyses.
2. SQL
Structured Query Language (SQL) is essential for data scientists as it is the standard language to communicate with relational database management systems (RDBMS). As a data scientist one has to write both simple and complex queries to select data from tables apart from an understanding of different data formats for data management and filtering.
3. R
R is a powerful language developed in the early 90s; currently, it is used widely for data science, analysis and statistical computing. Its popularity can be largely attributed to the following:
- Wide range of libraries
- Strong online community
- Open-source
- Lower learning curve
4. Java
Since Java is a very old programming language and popular among data scientists in the operational analytics space. It is quite evident that many enterprises already have systems developed with this language. Hence, the models are written in Java as it will be easier to integrate. Apart from that leading Big Data frameworks/tools like Spark, Hive, and Hadoop are written in Java. It is also a great choice when it comes to scalability and speed.
5. Hadoop
As a framework, Hadoop has gained massive popularity and has become the de-facto open-source software for reliable, scalable, distributed computing involving big data analytics.
6. SAS
This tool is a leader in the commercial analytics space. It has a huge set of in-built statistical functions, good UI (Enterprise Guide & Miner) for any user to quickly learn and delivers superior technical support. However, it is expensive and its certification programs can also cost a lot.
7. Spark
Apache Spark is an open source and it has the ability to keep data resident in memory, which can lead to faster iterative machine learning workloads. In addition to this, what makes it adoption stronger in the data science community is its base on Scala and in-built machine-learning library, MLlib.
8. C
Similar to Java, C/C++ is also used write models, and it is critical for writing the algorithmic extensions for R and Python.
9. Scala
Any data scientist looking to work on large data sets in a JVM-centric stack will be using Scala. Many of the high performance data science frameworks are written using Scala owing to its amazing concurrency support.
10. NoSQL
Unlike SQL, NoSQL offers an architectural approach with lesser constraints. In general, it is easier to break down NoSQL data stores but more complicated to query them for complex results.
For data scientists, NoSQL can be somewhat tricky — although the technology makes it absolutely easy to rapidly accumulate massive data sets and rapidly scale data stores to meet demand, it requires de-normalization of data.
11. Tableau
VizQL (Visual Query Language) is Tableau’s database visualization language which queries relational databases, cubes, cloud databases, and spreadsheets, and then generates a wide range of graphs and chart. These graphs can be combined into dashboards and shared via web. This application is particularly useful for data exploration and interactive analysis.
12. Data Science Skills – MATLAB
Although MATLAB is not as popular as R or Python in the data science space, it still has a lot of traction in academia. Also, it is a commercial app with the high cost and good customer support.
13. Hive
This is a popular data warehouse software in the Hadoop ecosystem that helps data scientists in data transformation and analysis. It provides an SQL-like interface to query data stored in various databases and file systems that integrate with Hadoop.
14. Excel
Microsoft Excel can be considered as a bridge application for very quick filtering and data analysis using in-built statistical methods. However, it becomes powerful when combined with Visual Basic. Check out the examples for building your own Excel-based neural network and Monte Carlo simulations.
15. Cassandra
Apache Cassandra is an open-source distributed NoSQL database management system designed to handle large amounts of data across many commodity servers. As this database was developed for Facebook, where millions of reads and writes happen at each given second, its performance is far superior.
16. MapReduce
It is a programming model that allows for massive scalability across hundreds or thousands of servers in a Hadoop cluster. Simply going by the name, MapReduce consists of two steps: Mapping and Reducing the data:
- Mapping sorts and filters a data set
- Reducing it allows a certain calculation on the resulting information
17. TensorFlow
This is the open-source framework developed by Google Brain Team for machine learning and deep neural networks research. Definitely, aspiring data science skills looking to work on neural networks must give preference to this framework.
18. Pig
It is a high-level scripting language used for operating on large data sets inside Hadoop. It primarily used to apply schema and transform data.
Data Science Skills – In Conclusion
This sums up the overview of the important skills a data science skills must acquire for better opportunities in career. If you would add any other skill or the reason behind learning a particular skill, do share with us via comments.




