
Indeed is one of the most popular job websites in the market today. It is a job aggregating website available in 60+ countries and covers multiple job boards, staffing firms, and company career pages. Scraping Indeed job data can help you access the latest job data, analyze job trends, and automate job boards. Indeed allows you to search job-based on location and keywords. These keywords can be a job title, skills, or any search term in the job listing. We will be using these two search boxes along with the number of pages of search results to crawl Indeed and extract the data.
Scraping Indeed Jobs Explained
First, you need to have the requirements installed to begin the scraping Indeed job data. These are Python3.7 or higher, BeautifulSoup, and a code editor. Once that is done you can save the code below to a file with the “.py “ extension and run it. But before we go into running the code, let us first understand the code itself.
It is the “main” method, where the execution starts. We take three inputs from the user – name of the city for which he or she wants job listings, keyword, and the number of pages of search results that are desired. Once we have these data points, we create the URL that needs to be hit for getting the search results. The “scrape_data” function is called next, which loops over the number of pages of search results that we want and calls the “get_data_from_webpage” function to extract job data from Indeed’s webpages.
In the “get_data_from_webpage” function, we extract the data for all job posts on a single webpage by looping over all the job posts on a single webpage of search results. We also strip the job post content to just the first 100 characters. You can change that piece of code so that you can get the required data at hand. In turn, the “extract_data_points” function called for every job post on a single page. It captures various data points by going into the specific job post links on Indeed. It captured the HTML data and converts it into a BeautifulSoup object, which is then parsed.
In simple terms, there are three levels of scraping Indeed job data for job posts:
- We loop through the n pages of search results
- Then we loop through all the job posts in a single web page
- We scrape the data for a single webpage by going to its link


Once the code runs on the number of pages we selected, we get an array of dicts where each dict contains the data of a single job post. We tested this code using these following values that you can see below-
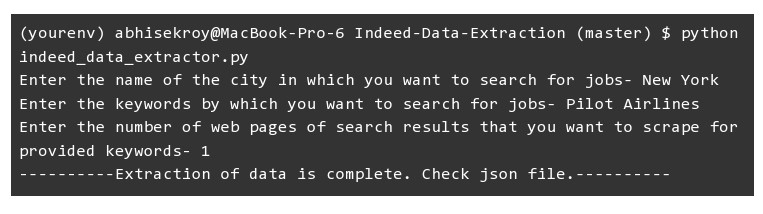
The Output of Scraping Indeed Jobs
For the input data that we showed above – The below JSON is what was received as a result by scraping indeed. You can see that there are just three job posts. But that is because we truncated the list to fit the blog. In reality, we scraped around seven job posts for the given search terms on page 1 of the search results. The data points that we captured for each job post are:
- Job Title
- Summary
- Location
- Name of the Company
- The Date posted
- Details
- Job URL
All the data points are self-explanatory. We specifically captured these because we believe these are most important for job applicants and job analysts.
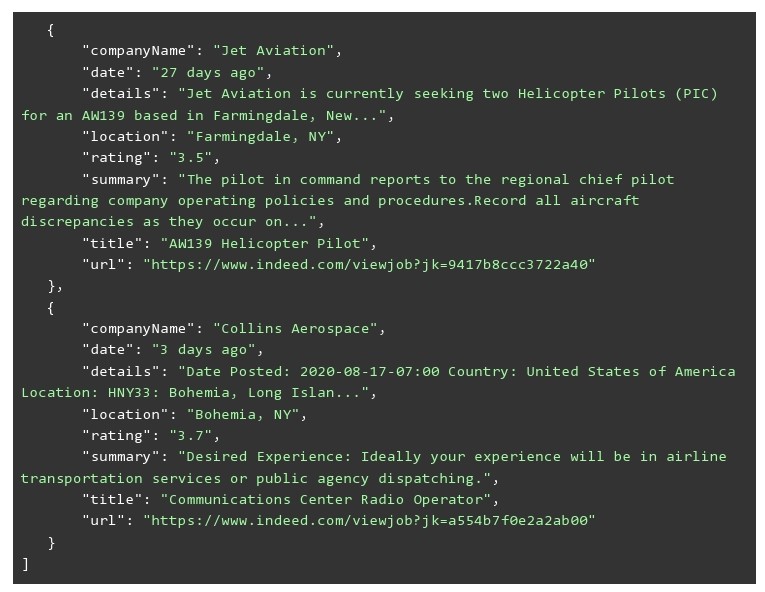
Certain data points like salaries may seem to be missing. The reason is that a large number of companies did not have the salary in the job posts and those who have it, it is in their job details itself.
Can This Work at An Enterprise Level?
This is a DIY code and cannot run at an enterprise level, it needs scraping Indeed and the job data scraped 24×7. The site will block you, the code is likely to break at some job listing with a different format, and more issues that can plague your production system.
For enterprise requirements, we have a professional job scraping solution in JobsPikr. We can automate job scraping Indeed job data and delivery to help you in your efforts at building a job board or in conducting research using job data.
FAQs
Is it Allowed to Scrape Indeed?
Indeed permits scraping Iindeed only when it adheres to their terms of service, which mainly restrict unapproved access and data extraction from their platform. Indeed utilizes mechanisms to identify and halt scraping activities, and engaging in such acts may result in legal consequences along with discontinuation of their services.
While scraping Indeed ensure compliance with Indeed’s terms of service prior to initiating any scraping tasks. As an alternative, consider employing Indeed’s API or data feed options, enabling lawful and authorized access to job data.
How Can I Scrape Indeed?
Job listings and additional data acquisition from Indeed through automated tools define scraping Indeed. Generally, this necessitates programming abilities in languages including Python alongside libraries such as BeautifulSoup or Scrapy.
Implement scripts to dispatch HTTP requests, decode HTML material, and retrieve targeted details; nonetheless, since scraping Indeed infringes upon their terms of service and might lead to legal complications, seeking alternative techniques, such as utilizing Indeed’s API or other external data sources, ensures legitimate and moral access to job data.
Is Data Scraping Illegal?
Legality of data extractions hinges on numerous aspects, comprising the target website’s terms of service, type of harvested data, and applicable regional statutes. Instances involving breach of specific websites’ restrictions, such as Indeed, could trigger judicial action according to anti-hacking policies or proprietary rights legislations. Therefore, respect the usage conditions of websites, obtain professional legal advice regarding data scraping ramifications to evade prospective litigation hazards.
What Does It Mean to Scrape Jobs?
Retrieval of job postings from employment bulletin boards like Indeed by deploying automated instruments represents job scraping. Information gathered includes positions, summaries, corporate identities, and geographical locators. Although beneficial for establishing a career hub or executing industry research, ensuring conformity with targeted website stipulations and pertinent jurisdictional rules becomes critical owing to ethical and juridical concerns. Utilizing APIs or affiliations provides dependable and compliant approaches to securely source job data instead.




