
- **TL;DR**
- Why Is Job Data Suddenly So Important For Workforce AI?
- Want to see what AI-ready job data looks like?
- How Does Job Data Actually Become AI Training Data?
- What Turns Raw Job Feeds Into Model-Ready Datasets?
- Why Do Workforce AI Models Break Without Consistent Schemas?
- What Problems Does Schema Design Actually Solve For Workforce AI?
- Want to see what AI-ready job data looks like?
- Which Workforce AI Models Benefit Most From Clean Job Data?
- What Should an Effective AI Data Schema Contain?
- How JobsPikr Structures Job Data for Workforce AI Readiness
- Want to see what AI-ready job data looks like?
- What’s Next for Workforce AI and Job Data?
- Where This Leaves Your Workforce AI Strategy
- Want to see what AI-ready job data looks like?
- FAQs:
**TL;DR**
Most people talk about “AI strategy.” Very few talk about the training data underneath it. For workforce AI, that training data is usually job data: titles, skills, locations, levels, salaries, and requirements. If that layer is messy, your models will be too.
The fix is not another model. It is an intentional data schema. When you decide how roles, skills, and locations are structured before you train anything, your ai training data becomes consistent instead of chaotic. The result is simple: workforce ai models that can recognize real roles, track real skills, and make recommendations that sound less like buzzwords and more like decisions you can defend in a meeting.
Why Is Job Data Suddenly So Important For Workforce AI?

Image Source: Gartner
If you look at how companies work today, almost every “people decision” has a job artifact behind it. A posting. A JD template. A role profile. A skills matrix someone once built and then forgot to update.
That same job data is now being reused as ai training data.
When your CHRO says, “We want a workforce AI that can tell us which roles are at risk, what skills we need, and where to hire,” the system has to learn from somewhere. It cannot guess. It learns from the only live feed it has: job data from your own systems and from the wider market.
Think about what sits inside job data for a moment:
- How work is described: responsibilities, projects, tools, stakeholders
- Which skills are “must have” vs “nice to have”
- Where roles sit: country, city, remote, hub locations
- How quickly demand shifts: posting volume, new titles, hybrid roles
This is exactly the kind of signal you want to feed workforce ai models. It tells them “what work looks like in the real world,” not just in your org chart from three years ago.
At the same time, the external side is changing fast. Major reports keep pointing to the same pattern: skills are rotating out and in much faster than job architectures are updated. That is why relying only on internal HR tables feels stale. External job data fills that gap and gives your ai models a live view of what roles, skills, and pay look like across markets.
But here’s the catch: raw job data is not yet ai training data.
The version in your ATS exports and scraped feeds is usually full of duplicates, inconsistent titles, and tiny differences in spelling and formatting that completely confuse a model. “Sr. Data Eng,” “Senior Data Engineer,” and “Data Engineering Specialist” may all refer to the same core job, but an unstructured model will happily treat them as three worlds apart.
That is where schema comes in.
Before you train workforce ai models, you have to decide how this job data will be structured:
- What is a “role family”?
- How do you store skills? As loose text, or as a consistent list?
- How do you represent locations: free text, or country → region → city?
- What does “level” mean, and how is it encoded?
When you answer those questions, you are designing your ai data schema. You are deciding the shapes your data is allowed to take. That structure is the difference between “we have a lot of data somewhere” and “we can train models that actually see patterns in how work is evolving.”
If your team is exploring workforce ai right now, this is the shift in thinking:
Don’t start with “Which model should we use?” Start with “What should our job data look like before we even open a notebook?”
That is what the rest of this article is about: how job data becomes ai training data, why schema design quietly controls model quality, and what good structure looks like when you are building workforce ai models that you can trust.
Want to see what AI-ready job data looks like?
Find out how structured job data feeds workforce intelligence, from schema design all the way to real decisions on roles and skills. Book a Demo
How Does Job Data Actually Become AI Training Data?
If you’ve ever looked at a raw export of job postings, you already know it’s not model-ready. It’s a mix of long paragraphs, inconsistent job titles, repeated skills written in twenty different ways, locations spelled differently for the same city, and outdated posts that should’ve been removed months ago.
Yet this is the exact material most teams hand over to their data scientists and say, “Can you train a model on this?”
That’s how workforce AI projects go off the rails.
For job data to become reliable ai training data, it needs to move through a pipeline that gives it consistency, structure, and context. Not polish. Not “clean-up for cosmetics.” Actual structure that teaches a model how work is organized in the real world.
The process looks simple on paper, but the quality of each step determines whether the model ends up being a strategic asset or a fancy autocomplete.
What Turns Raw Job Feeds Into Model-Ready Datasets?
The transformation starts long before a model ever sees the data.
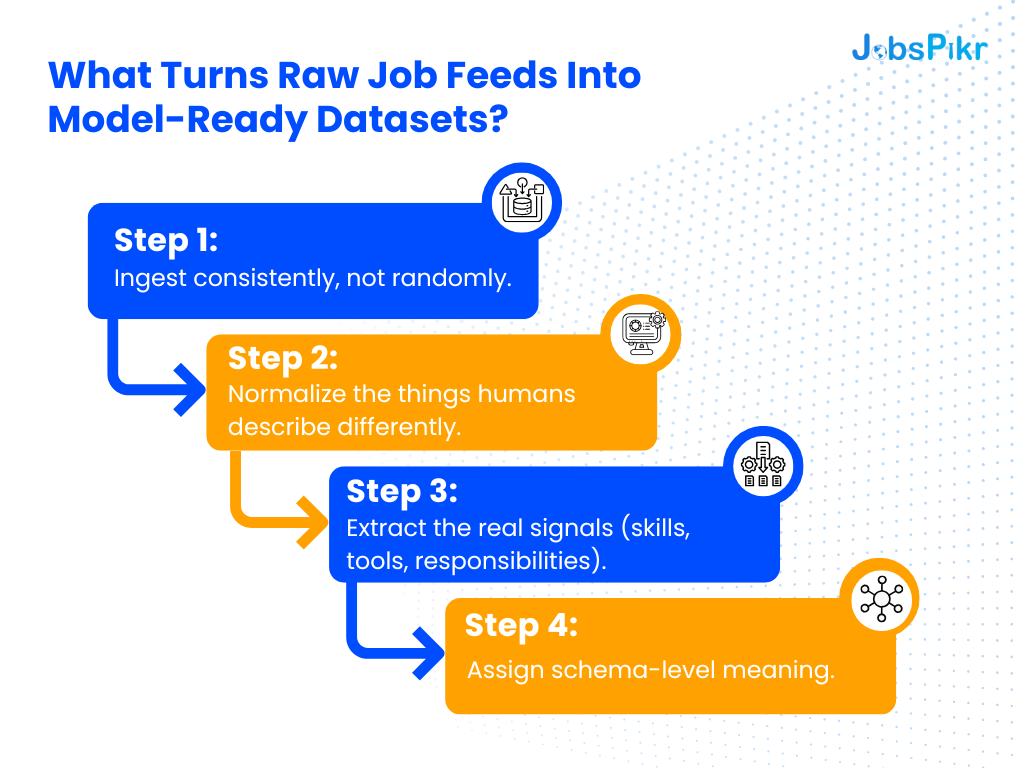
Step 1: Ingest consistently, not randomly.
Most teams collect job data from wherever they can find it. The problem is inconsistency. A posting scraped from an employer site looks different from the one found on a job board. A posting collected today may differ from the one collected yesterday for the exact same role. Consistent ingestion means:
- standardized fields
- timestamped versions
- deduplication logic
- source-level metadata
This early structure prevents the model from learning noise as if it were a real pattern.
Step 2: Normalize the things humans describe differently.
Job titles are the biggest offenders.
“ML Engineer,” “Machine Learning Engineer II,” and “Applied Scientist (ML)” often refer to the same underlying role.
Without normalization, a model treats them as unrelated.
Same issue with skills: “Python,” “Proficient in Python,” “Strong Python background,” and “Python 3.x” should all map to one canonical identifier.
A structured data schema is what forces that consistency.
Step 3: Extract the real signals (skills, tools, responsibilities).
This is where enrichment begins. Models need clear signals, not a wall of text. That means pulling structured elements out of the description:
- skills
- tools
- certifications
- seniority indicators
- responsibilities
- industry context
This turns unstructured language into machine-readable building blocks.
Step 4: Assign schema-level meaning.
This is the quiet unlock. Schema is where you define:
- what counts as a job family
- how levels are represented
- what metadata belongs with each posting
- how roles relate to each other
This is the layer that turns “a lot of job data” into “ai training data that a model can learn from.”
Once your dataset matches a consistent structured data schema, the model finally gets a stable environment to learn patterns in how work is designed, how skills cluster, and how roles evolve across markets.
Why Do Workforce AI Models Break Without Consistent Schemas?
Without a solid schema, your model is basically learning inside a moving room. Titles change shape. Skills appear in different formats. Locations jump between levels of granularity. The result?
1. The model learns the wrong things.
It mistakes formatting differences for job changes.
It treats synonyms like separate concepts.
It overweights whatever is most common, not what is most meaningful.
2. The model can’t compare roles across markets.
If “Senior Data Analyst” in the US is encoded differently from the UK version, your model never builds a unified view.
3. Skill predictions drift over time.
A model might begin associating the wrong skills with a role simply because they appeared frequently in messy text. That’s how you get those bizarre, irrelevant skill recommendations that erode trust immediately.
4. Internal mobility models break completely.
If your schema doesn’t consistently track:
- level
- role family
- skill clusters
- location or region
you cannot compute similarity between a current employee’s role and an open job.
The model just guesses.
Clear structure is what prevents these issues. It’s what lets the model learn “this is a job,” “these are skills,” “this is seniority,” “this is context.”
Get that wrong, and no amount of fine-tuning will fix it.
What Problems Does Schema Design Actually Solve For Workforce AI?
Most conversations about workforce AI jump straight to algorithms: embeddings, vector spaces, transformers, retrieval models. But the real bottleneck happens earlier, at the schema layer. A model can only learn patterns that your structure allows it to see. If your data schema is weak, every downstream model inherits that weakness.
This is why workforce AI often feels “smart in the demo, confused in practice.”
The structure underneath was never built for machine reasoning.
Schema design solves problems you can’t fix later with tuning, prompts, or more compute.
How Does a Structured Data Schema Improve Skill Extraction Accuracy?
Skills are the currency of workforce AI, but they’re also the messiest part of job data.
Even in a small sample of postings, you’ll find:
- Skills buried inside long paragraphs
- Skills broken into partial phrases
- Vendor-specific terms that mean the same thing
- Overlapping tool names
- Misspellings and shorthands
Without schema guidance, models don’t know what to treat as a single skill versus a noisy fragment.
A structured data schema solves this by defining:
- What counts as a skill
- How skills should be stored
- How synonyms should be handled
- How multi-word skills are preserved
- How skills relate to families or domains
Once skills follow a consistent pattern, models can begin to understand relationships:
- which skills co-occur
- how they cluster
- which ones differentiate seniority
- which ones appear first when a new role emerges
That is what powers usable skill inference, not just accuracy on a benchmark.
Can Thoughtful Schema Design Reduce Bias in Workforce AI Models?
It can, and it often does, because bias doesn’t only come from people. It comes from the structure of the data itself.
Here’s a simple example: “Head of Data,” “Director of Data Science,” and “Principal Data Scientist” may all represent similar levels of seniority, but the titles differ wildly across companies.
If your schema lacks a standardized level field, the model starts making “prestige-based” judgments. It overweights certain titles simply because they appear fancier or more common in your dataset.
Schema design prevents this by enforcing:
- standardized seniority
- normalized job titles
- consistent level markers
- region-aware role mapping
- unified job families
This does not remove human bias entirely, but it prevents structural bias from creeping into workforce ai models. It stops the model from learning skewed patterns simply because the raw text had a particular flavor.
You’re not just cleaning data. You’re shaping how the AI understands the world of work.
The Quiet Advantage: Schema Makes Models Transferable
This is something most teams only realize after deployment.
If you train a model on unstructured job data, it’s essentially “memorizing” your version of the world. When you try to apply it to new markets, new role families, or new skill clusters, performance collapses.
But with a strong ai data schema:
- new countries can be added
- new role families can be merged smoothly
- new skills can be slotted into taxonomies
- new job formats (e.g., hybrid roles) don’t break anything
Schema design creates durability. It gives you a foundation that scales with the market rather than fighting it.
And in a world where roles and skills evolve faster than org charts, that durability is everything.
Want to see what AI-ready job data looks like?
Find out how structured job data feeds workforce intelligence, from schema design all the way to real decisions on roles and skills. Book a Demo
Which Workforce AI Models Benefit Most From Clean Job Data?
If you strip away all the branding around “workforce AI,” most teams want the same four capabilities:
- A model that understands what roles mean
- A model that understands what skills actually map to those roles
- A model that can compare roles across markets or job families
- A model that can predict where roles are going next
Every single one of these depends on structured job data.
When the schema is weak, these models hallucinate. They make connections that look clever in a slide deck but fall apart the moment a leader asks, “Explain how it arrived at that recommendation.”
Strong schemas fix that. They give each model a stable learning environment.
How Do Skill Inference and Role Matching Models Use Clean Job Data?
Skill inference is often the first “wow” demo companies build.
You upload a job description.
The system returns the right skills, even skills that weren’t explicitly mentioned.
It looks magical.
But behind the scenes, the only reason it works is because the schema already knows:
- what counts as a skill
- how skills are categorized
- which skills signal seniority
- which skills tend to co-occur
- how skills relate to job families
If your skill structure is messy, inference becomes guesswork.
And matching models? They rely even more on schema.
When you compare a person’s current role with an open job, the model needs to understand:
- both roles’ levels
- both roles’ skill clusters
- the distance between the two skill sets
- whether titles are comparable across companies
Without schema alignment, the model is comparing apples to a basket of unrelated fruit.
That’s how organizations end up with recommendation engines that say things like:
“Your Financial Analyst could be a great fit for Senior Cloud Engineer!”
Technically possible? Maybe. Operationally useful? No.
A good schema prevents nonsense like that from ever reaching a user.
How Do Compensation and Demand Forecasting Models Depend on Schema?
These models look at job data through a market lens.
They try to understand:
- where demand is rising
- where salaries are shifting
- which skills are market-defining
- how job families evolve over time
But here’s the problem: Market signals are incredibly noisy until you add structure.
Example: If a dataset contains “Data Engineer,” “DE,” “Data Engineering Specialist,” and “Big Data Engineer” as four distinct titles, your model will misread market demand. It will think demand is more fragmented than it actually is.
Schema solves that. It merges variants into a consistent role identity, so the model sees the trend clearly.
Compensation models have the same issue. You can’t compare pay across three titles if the model thinks they represent unrelated work.
Once titles, skills, and levels flow through a structured data schema, forecasting becomes noticeably sharper:
- real demand curves
- real salary ranges
- real emerging skill patterns
- real workforce mobility paths
Without schema, these models behave like they’re looking at the job market through frosted glass.
Skill inference, role matching, job similarity scoring, internal mobility algorithms, market forecasting, compensation prediction—every one of these models becomes more accurate, more stable, and more explainable when the data underneath them follows a consistent structure.
Schema design doesn’t just support workforce AI. It decides whether workforce AI works at all.
What Should an Effective AI Data Schema Contain?
If you ask ten teams what their “job data schema” looks like, you’ll usually get ten different answers; mostly spreadsheets, ad-hoc fields, and structures that grew organically rather than intentionally. But an AI model is far less forgiving than a human. It won’t infer context. It won’t “just know” that a role is senior or that two titles describe the same job family.
A good ai data schema removes guesswork. It gives your workforce ai models a stable foundation so they can learn patterns in roles, skills, and markets without being misled by formatting quirks or legacy terminology.
Here’s what an effective schema actually needs to hold together.
Which Core Fields Turn Job Data Into Reliable AI Training Data?
A schema is not “fields you happen to have.”
It’s fields your AI needs to understand the world of work.
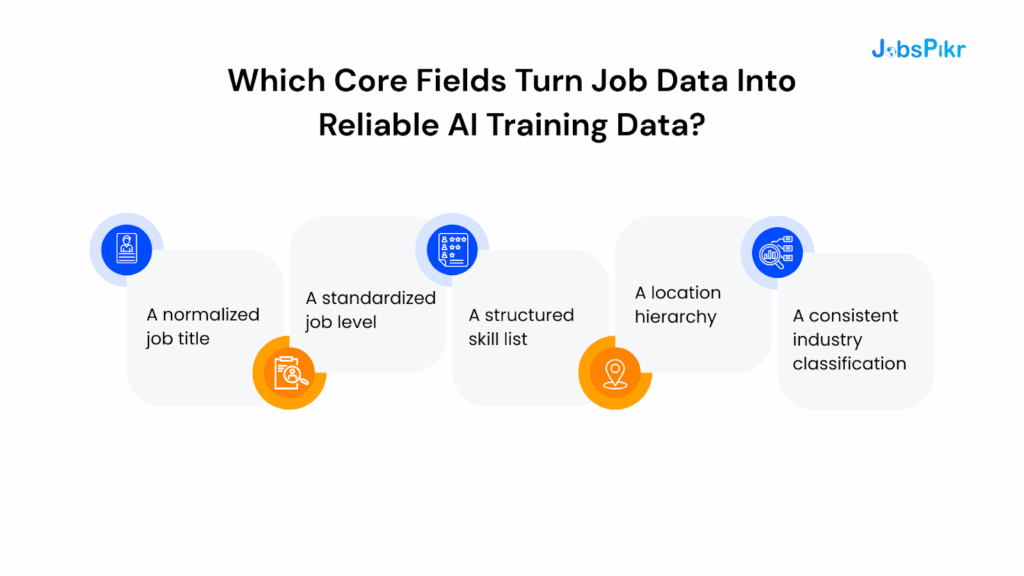
The fundamentals include:
1. A normalized job title
Not the marketing version. Not the quirky startup version. The canonical version.
This lets the model treat “Data Engineer,” “Sr. Data Eng,” and “Data Engineering Specialist” as variations of one role instead of three separate careers.
2. A standardized job level
Titles lie. Levels don’t—if you enforce them consistently. A strong schema explicitly defines levels (Entry, Mid, Senior, Lead, Manager, Director, VP).
This stops a model from assuming “Head of X” is more senior than “Director of Y” just because the wording looks grander.
3. A structured skill list
Skills should be encoded the same way every time.
- No multi-word fragmentation.
- No duplicates.
- No “Proficient in Python” stored differently from “Python.”
The model needs clean signals to learn from.
4. A location hierarchy
Free-text location fields are the fastest way to corrupt a dataset.
A schema should store:
- Country
- Region/State
- City
- Metro area
- Remote/Hybrid flags
Models rely heavily on location to understand labor markets, salary patterns, and mobility.
5. A consistent industry classification
Industry shapes everything—from required skills to pay to typical role structures. Without a consistent industry field, models misinterpret context entirely.
If your schema captures these core fields well, you’ve already removed most of the noise that trips up workforce AI.
How Should an AI Data Schema Handle Emerging Skills and New Roles?
Skills change faster than org structures. New roles appear out of thin air. Your schema has to accommodate that without breaking.
A future-proof schema needs:
1. A skill taxonomy that evolves
It should allow new skills to be added without rewriting the entire schema. It should group related skills so the model understands their relationships.
2. Version control
Skills need timestamps—
- When did a skill first appear?
- When did a role start requiring it?
This helps models track the evolution of work over time.
3. Role family extensions
“AI Engineer,” “LLM Engineer,” and “Foundation Model Engineer” didn’t even exist a few years ago. A schema must allow new families to emerge instead of forcing them into old buckets.
If your schema freezes the world in time, your models will freeze with it.
How Do You Keep Your Structured Data Schema Maintainable Over Time?
Schema design is one thing; schema governance is another.
Most teams build a schema once and never touch it again. This is how drift happens—new titles appear, new skills take over, and your once-clean structure starts to decay.
To keep your schema healthy:
1. Run automated validation checks
These detect malformed titles, missing fields, new patterns, or emerging synonyms.
2. Keep a record of “known exceptions”
Some companies use truly unusual titles. Flag them; don’t force-fit them.
3. Refresh your skill dictionary quarterly
The market evolves faster than internal playbooks.
4. Revisit level mappings as new role structures emerge
Especially in fast-growing domains like data, cloud, and specialized engineering.
With minimal governance, your schema stays stable while still adapting to the market—exactly what workforce ai models need.
How JobsPikr Structures Job Data for Workforce AI Readiness
If you’ve ever tried to build your own job data pipeline, you already know the unglamorous truth: most of the work is not “AI.” Most of the work is data plumbing. JobsPikr exists because teams were spending months trying to structure data before they could even begin model development. Our dataset is built to remove that overhead, so your AI doesn’t start its life learning from chaos.
The goal isn’t to make job data pretty.
The goal is to make job data predictable, so workforce AI models can learn from it without fighting noise at every step.
Here’s what that looks like in practice.
Ingestion at Scale: Collecting the World of Work Without the Mess
Job data comes from thousands of sources and follows no global standard. Titles vary by region. Skills vary by company. Formatting varies by job board. And because companies update postings frequently, the same role can appear in multiple versions within a week.
JobsPikr’s ingestion pipeline is built specifically for this kind of variation:
- multiple vetted sources
- automated deduplication
- daily or weekly refresh cycles
- version tracking so you know how a role evolves
- consistent field capture across geographies
This ensures that three postings for the same job don’t turn into three separate “facts” inside your model.
Normalization: Turning Human Language Into a Stable Structure
This is the part that makes or breaks workforce AI.
A model doesn’t know that “Sr. ML Eng” and “Machine Learning Engineer II” might describe similar levels of work. It only knows what you teach it. JobsPikr’s schema does that teaching.
We normalize:
- job titles into canonical forms
- seniority into consistent levels
- locations into hierarchical structures (country → state → city → metro)
- industries into NAICS-aligned categories
- company names into unified identities where possible
This normalizes away the noise and exposes the actual patterns in the labor market so your models can learn from reality instead of formatting quirks.
Skill Extraction and Enrichment: Where the Real Signal Lives
Every workforce ai model depends on skill signals. Without strong skill extraction, models cannot infer roles, map similarities, predict mobility, or forecast demand shifts.
JobsPikr applies:
- domain-trained NLP models
- skill taxonomies aligned to global standards
- multi-word skill recognition
- synonym and variant merging
- emerging-skill detection through frequency and co-occurrence patterns
This is how “Python,” “Python 3.x,” “Experience building Python pipelines,” and “Strong Python background” collapse into one clean skill identity instead of four noisy text fragments.
Better signals mean better models. It’s that simple.
Schema Consistency: The Reason Workforce AI Actually Works
A dataset is only as useful as the structure behind it.
JobsPikr’s schema defines:
- what a job family is
- how levels relate to each other
- how skills are stored
- how related roles cluster
- how location context is encoded
- how industry context is applied
This contiguity is what makes the dataset model ready. You can train skill inference models, similarity engines, career path models, salary prediction systems, and workforce planning models without reinventing your own schema each time.
Most importantly, you get explainability.
You can trace why the model recommended something because the underlying structure is intentional, not accidental.
Historical Context: Learning How Work Evolves Over Time
One of the most underrated advantages of having a stable, structured dataset is history. Jobs change fast. Skills spike and fade. Roles merge and split. Without historical snapshots, a model only gets a static picture of the world.
JobsPikr stores:
- longitudinal trend data
- first-seen skill dates
- demand spikes
- geography-specific shifts
- industry movement
This lets your workforce ai models study changes, not just patterns.
If you want your AI to make forward-looking recommendations, history is essential. Trends, not point-in-time data, are what make predictions trustworthy.
Why This Matters for Your Workforce AI Projects
By the time most AI teams “clean” job data enough for experimentation, budgets are burned and timelines have slipped. JobsPikr collapses that time by giving you data that’s already aligned to a schema built for AI—from ingestion to normalization to enrichment.
You don’t start at chaos. You start at consistency. Which means you can build workforce AI, not fight your dataset for six months.
Want to see what AI-ready job data looks like?
Find out how structured job data feeds workforce intelligence, from schema design all the way to real decisions on roles and skills. Book a Demo
What’s Next for Workforce AI and Job Data?
If you ask most companies what they expect from workforce AI over the next few years, the answers usually sound like a wishlist: better skill predictions, better mobility insights, better understanding of emerging roles, better alignment with business strategy. But none of that becomes real unless the job data underneath keeps up with how work itself is evolving.
The future of workforce AI is going to depend less on bigger models and more on better signals. And the most reliable signals are already coming from job data—just not in the raw form most teams collect.
Here’s what’s heading our way.
The Pace of Skills Change Will Outrun Traditional Job Architecture
Internal job frameworks were designed for stability, not speed. But the market no longer works that way. Large research bodies like the World Economic Forum have been pointing to the same trend for years: a massive share of job skills are shifting inside a five-year window.
That kind of velocity means internal role definitions age quickly.
Workforce AI models will have to rely on job data to stay current, because job data captures the first signs of change:
- a new tool showing up in a niche role
- a skill becoming a requirement instead of a “nice to have”
- a job family breaking into something new
Organizations that depend solely on internal HR definitions will always be trailing the market.
AI-Native Roles Will Push Schema Design Even Harder
Roles like “Prompt Engineer” and “AI Product Lead” barely existed a few years ago. Now they appear across sectors. The same pattern is coming for dozens of new hybrid roles roles that blend machine learning, workflow design, data governance, domain expertise, and automation oversight.
The challenge? New roles break old schemas.
If your schema isn’t flexible, these roles land as unstructured blobs. Your model learns nothing meaningful.
If your schema is built with adaptability in mind, extensible skill taxonomies, evolving role families, versioned mappings, your model can incorporate these roles the moment they enter the market.
This is where most teams will fall behind.
AI-native roles won’t fit into yesterday’s job architecture.
External Job Signals Will Become the “Early Warning System” for Talent Strategy
Think about how companies used to forecast talent needs: annual workforce planning cycles, internal headcount tables, static job definitions. That pace won’t cut it anymore.
Job data provides something that internal systems cannot: real-time visibility into how work shifts across companies, markets, and geographies.
As hiring volatility increases, this matters more:
- sudden demand for niche technical skills
- new hubs emerging in unexpected geographies
- salary ranges adjusting faster than compensation bands
- competitor job families restructuring
- remote roles expanding or contracting geographically
These are all signals that show up in job data long before they show up in internal dashboards.
Workforce AI models trained on these external signals will help companies adjust proactively instead of reacting months later.
Schema Will Become a Competitive Advantage (Not an Internal Project)
Right now, schema work is usually treated like a technical chore or a one-time cleanup. Over the next few years, it becomes something else entirely: a talent strategy asset.
If your data schema makes job data machine-readable at scale, your workforce ai models can do things your competitors simply can’t:
- predict emerging skill gaps before they show up internally
- identify mobility paths you didn’t know existed
- compare your job architecture to the market in minutes
- model compensation ranges based on real-world demand
- spot role fragmentation early and reorganize accordingly
Companies that lack schema discipline will end up with models that look impressive on the surface but offer shallow insights under pressure.
The divide between “toy model” and “org-level AI” will come down to structure, not algorithms.
The Future in One Line
As workforce AI matures, the companies that win will be the ones whose data is structured well enough for the AI to see what’s happening in the world of work, not just what’s already documented internally.
Where This Leaves Your Workforce AI Strategy
If you strip away the hype around workforce AI, you’re left with something very simple: the model can only be as good as the data beneath it. Not big data. Not more data. Structured data. That’s what turns job postings, role descriptions, and skills text into ai training data a model can learn from.
You’ve seen this in every chapter of the article so far.
- When titles mean different things in different places, the model gets confused.
- When skills appear in five formats, the model dilutes the signal.
- When levels aren’t standardized, mobility recommendations fall apart.
- When locations aren’t defined cleanly, market forecasts get blurry.
The structure, your schema, is what separates noise from knowledge.
Internal HR datasets alone rarely capture how fast work evolves. They tell you what your organization looked like yesterday. Job data shows you what the market is becoming next. When both are aligned to a clear ai data schema, you gain something most companies don’t have: a model that can read the labor market as it shifts, not after it has shifted.
That’s what talent intelligence teams, HR analytics leads, and AI researchers actually need. Not a chatbot sitting on top of an ATS. Not a dashboard full of lagging indicators. They need models that can understand work at the level of roles, skills, families, geography, and change over time.
You don’t get that from a model-first approach. You get it from a structure-first approach.
Once the schema is right, everything else—similarity scoring, skill inference, job clustering, career-path modeling, compensation prediction, workforce planning—stops being fragile. The insights feel grounded, not generic. The recommendations sound thoughtful, not templated. And the model becomes something you can rely on during planning conversations rather than something you keep explaining away. Workforce AI is not a “model problem.” It’s a data structure problem. Solve that layer, and everything else becomes significantly easier.
Want to see what AI-ready job data looks like?
Find out how structured job data feeds workforce intelligence, from schema design all the way to real decisions on roles and skills. Book a Demo
FAQs:
1. What is training data in AI?
Training data is the information a model learns from before it ever makes a prediction or recommendation. In workforce AI, this usually means job data, skills, levels, locations, responsibilities, and historical patterns of how roles evolve. The cleaner and more structured that data is, the more accurate and reliable the model becomes.
2. What is an example of AI training data?
If you’re building a workforce intelligence model, a single job posting is a perfect example of training data. It contains titles, responsibilities, tools, required skills, seniority signals, and sometimes even pay ranges. When that job data is mapped to a clear schema—normalized titles, structured skills, consistent level definitions—it becomes high-quality training material instead of just text.
3. Where do you get data to train an AI?
It depends on the use case, but for workforce AI, the strongest signals come from a mix of internal and external sources. Internal HRIS and ATS systems show how your organization is structured today. External job data shows how the market is shifting—new roles, new skills, new expectations. Most companies combine both, because internal data alone rarely captures the pace of market change.
4. What role does labor market job data play as AI training material?
Labor market job data acts as a real-time lens into how work is changing across industries and geographies. Workforce AI models use this data to learn which skills are emerging, how roles cluster, which job families are expanding, and where demand is rising. If this data is structured well—clean titles, mapped skills, consistent locations—it becomes a powerful training foundation for models that need to stay aligned with the market, not just internal job architecture.
5. What makes an AI training dataset effective for workforce intelligence?
It’s not volume; it’s structure. An effective training dataset for workforce AI has normalized titles, standardized levels, clean skill extraction, location hierarchy, industry mapping, and historical context. Without this schema, a dataset is just text. With it, the same data becomes a reliable signal source that models can use to infer roles, predict mobility, and track market shifts with clarity.




