
- **TL;DR**
- Why Does Job Data Feel So Messy Today?
- What Is Data Normalization and Why Does Workforce Data Depend on It?
- Why Is Data Normalization So Hard at Scale?
- Ready for Clean, Consistent Job Data?
- How You Turn Millions of Job Posts into One Standard Format
- Ready for Clean, Consistent Job Data?
- What Good Normalized Job Data Unlocks for You
- How Large Workforce Teams Use Normalized Job Data in the Real World
- How Data Deduplication Fits into the Normalization Pipeline
- Ready for Clean, Consistent Job Data?
- What Technical Managers Should Look for in a Normalized Job Dataset
- Why Normalization Turns Job Data into a Real Strategic Asset
- Ready for Clean, Consistent Job Data?
- FAQs
**TL;DR**
Most teams underestimate how much chaos hides inside “simple” job data. The same role appears under ten different titles, skills are described in every possible way, locations are formatted inconsistently, and duplicate job posts flood your feeds from multiple sources. Without solid data normalization and data deduplication, your dashboards are basically stitched-together guesses.
What data normalization does is surprisingly straightforward: it takes all those different formats and expressions and forces them into one clean standard. “Sr. Software Eng – Backend,” “Senior Backend Engineer,” and “Software Engineer (Back End)” stop being three separate signals and become one normalized role with one set of skills, one location format, and one company view. You keep the richness of the original job posts, but you stop treating them like three different jobs.
Once you have that level of data consistency, everything else starts to work properly. Market maps stop counting the same openings again. Skill demand trends become believable instead of “directionally correct.” Your AI models train on clear, structured inputs instead of noisy text. And when you plug normalized job data into your internal tools, your team spends time on analysis and decisions, not on cleaning CSVs or arguing over whose numbers are “right.”
Why Does Job Data Feel So Messy Today?
If you’ve ever tried to work with raw job data, you know the feeling. You download a big file from a job board, or you plug in a new feed, and within five minutes, you’re staring at chaos. Titles aren’t just different, they’re all over the place. Skills show up as paragraphs instead of fields. Locations jump between full addresses, city-only, state abbreviations, and sometimes vague phrases like “Remote (US)” or “Flexible.” And the same job can appear on four or five different sites, each phrased slightly differently, which turns one opening into five competing signals.
You’re not imagining it. This is what happens when every company, every ATS, and every job board decides to structure things their own way. One employer lists “Data Analyst,” another writes “Analyst – Data,” and a third calls it “Business Insights Specialist,” even though all three require the same SQL/Python stack. They’re describing the same thing, just not in the same language.
And when you multiply that variability across millions of job posts each month, the picture gets blurry fast. Any analyst who tries to run workforce insights on top of this data hits the same wall: the numbers don’t line up, the categories feel inconsistent, and nothing feels reliable enough to automate or scale.
This is exactly why data normalization matters. Not because it’s a “nice backend clean-up task,” but because without it, your job data never becomes a single source of truth; it stays a patchwork of interpretations.
What Is Data Normalization and Why Does Workforce Data Depend on It?
If you strip away the jargon, data normalization is just the process of making messy things consistent. It is the difference between trying to compare ten different versions of the same job and finally seeing one clean, standardized version that reflects reality. Most job data problems start because every employer, job board, and applicant tracking system speaks its own language. Normalization brings all of that into one shared structure.
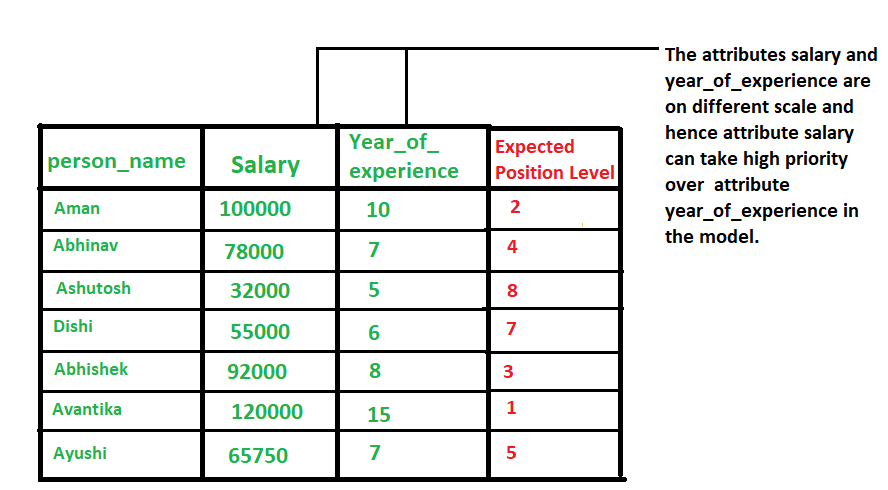
Image Source: geeksforgeeks
How do different job sources create inconsistent job data?
Think about how companies write job titles. One team prefers “Marketing Manager”. Another writes “Manager Marketing”. Someone else calls it “Marketing Lead”. A startup might write “Growth and Brand Manager”. None of them is wrong, but these variations make it impossible to compare roles across companies without cleaning the data first.
The same problem shows up in skill descriptions. Some employers paste long paragraphs into the requirements section. Others use bullet points. Some mention skills once; some repeat them four times. Without normalization, skills become a tangled list of duplicates instead of a clear view of what the market is asking for.
Location formats cause another layer of confusion. A single location might appear as “San Jose, CA”, “San Jose California”, “SJ CA”, or “Hybrid Bay Area”. These variations look harmless until you try to run regional analytics, and suddenly, your dashboards show five different versions of the same place.
This inconsistency is why raw job data feels unreliable. It is also why normalization is not optional for any team working with large datasets.
What does a normalized job record look like?
A normalized record looks almost boring. That is the point. Every field is formatted the same way. Titles are mapped to a standard taxonomy. Skills are extracted and listed as structured entities instead of long text. Locations follow one clean format. Company names match a unified directory instead of dozens of misspellings or alternate spellings.
You keep the original job post, but the normalized version becomes the version your systems use for analysis and AI models. When everything follows the same schema, you stop wasting time on manual cleanup and start getting insights you can trust.
Normalization does not oversimplify the data. It brings structure to the noise so you can finally see patterns that were buried under inconsistent labels and formatting.
Why Is Data Normalization So Hard at Scale?
On paper, data normalization sounds simple. Clean the text, standardize the fields, push everything into one schema. Anyone who has worked with real job data knows it is never that easy. Normalization becomes difficult the moment volume, variation, and vague job language collide. And they collide every single day in workforce data.
The sheer volume of job posts multiplies inconsistencies
Most job ecosystems move faster than any manual cleanup process can handle. Large job boards can publish hundreds of thousands of listings in a single day. Aggregators source from dozens of websites. Employers update openings, repost them, or rewrite them midweek.
When that kind of volume hits your pipelines, even small inconsistencies start to create real distortion. A title written in five different ways becomes a thousand variations once you spread it across different sources. A location format with three slight differences becomes twenty. Volume does not just make the work heavier. It chips away at the reliability of your entire dataset.
Job titles and skills follow no shared standard
Every employer has its own naming philosophy. Some stick to traditional titles like “Marketing Manager”. Others adjust seniority labels, add internal jargon, or write quirky titles because it makes the job sound more exciting. The same logic applies to skills. One employer writes tightly structured bullet points. Another writes three paragraphs. Some list tools, others list broad categories.
The result is a skill map that reflects writing styles instead of real market demand. Without normalization, you end up comparing text patterns, not the skills employers need.
Taxonomies create structure where none exists
A taxonomy brings order to this chaos. It provides a consistent way to classify roles, families, functions, and skills. Instead of guessing which version of “Software Engineer” belongs where, the taxonomy does the heavy lifting. It groups variations, aligns synonyms, and keeps everything tied to one standardized framework.
At scale, this structure becomes essential. It is the only way to manage thousands of job titles, tens of thousands of skill variations, and millions of raw listings that shift and evolve every week. Without a taxonomy anchoring the process, normalization turns into a never-ending cleanup loop.
Ready for Clean, Consistent Job Data?
Get a walkthrough of the pipeline that powers JobsPikr’s normalized datasets.
How You Turn Millions of Job Posts into One Standard Format
Once you accept that raw job data will always be messy, the real question is what you do with it. At scale, data normalization looks less like a single script and more like a pipeline. Data flows through a series of steps, and each step has a clear responsibility. Extract, structure, standardize, deduplicate, then enrich. If any of those stages is weak, the whole thing starts to wobble.

Image Source: JobsPikr
Extracting raw job data into a workable structure
Everything starts with extraction. Jobs come in from job boards, career sites, aggregators, ATS feeds, and sometimes custom sources. Each one has its own HTML layout, field naming, and habits. Some include salary in a structured field. Others bury it in a long description.
The first task is to pull all that content into a common container without trying to normalize too early. At this stage, you want to preserve as much of the original text as possible. Titles, descriptions, locations, company names, salary hints, skill mentions, all of it. Once you have this raw layer, you can start to layer logic on top instead of fighting formats one by one.
Parsing job fields into a consistent schema
The next step is to turn unstructured or semi-structured text into clear fields. This is where you define your schema for job data normalization. For example, you might decide that every job record should have specific fields such as standardized title, original title, company, location, employment type, skills, salary range, seniority, and a few other signals.
To get there, you rely on a mix of rules and models. Regular expressions help with simple patterns like salary ranges or currency formats. NLP models help detect skills, seniority hints, or employment type inside free text. The goal is not perfection on day one. The goal is to get the data into a consistent shape that your team can iterate on.
Applying standardization rules for true data normalization
Once the schema is in place, you can start real data normalization. This is where you map original values to a standard set. Titles are mapped to a controlled vocabulary. Locations are resolved to a consistent format, often with country, region, and city split across separate fields. Skills are linked to a master skill dictionary instead of staying as free text.
This is where you see the payoff from your taxonomy work. All those variations of “Senior Backend Engineer”, “Backend Software Engineer II”, or “Sr Software Eng Backend” roll up into one normalized title. You keep the raw version for transparency, but the standardized one is what drives your analytics, your dashboards, and your AI models. Data consistency stops being an aspiration and becomes something you can prove.
Using data deduplication to keep the signal clean
Even the best normalization will not help if the same job appears fifteen times in your dataset. Data deduplication is the layer that keeps your signal clean. It spots jobs that are effectively the same posting, even if there are small changes in wording, and collapses them into a single canonical record.
This is not as simple as matching job titles. A good deduplication strategy uses a combination of title, company, location, posting date, and sometimes unique tracking IDs or deep text similarity. It accepts that two posts rarely match character for character but still represent the same opening. When deduplication is done well, hiring trends become sharp and believable instead of being inflated by clones and reposts.
Letting models learn and improve normalization over time
The last important piece is feedback. Your normalization rules should not be frozen. As new roles appear, new skills gain popularity, and companies invent fresh titles, your system must adapt. This is where machine learning earns its place.
Models can learn from historical decisions, human corrections, and downstream signals. If your team repeatedly remaps a specific title to a different standardized role, the system should start doing that on its own. If new skills appear often enough, they should be promoted into the main skill dictionary instead of living as one off tokens. Over time, the normalization engine becomes smarter, and your manual workload drops.
Ready for Clean, Consistent Job Data?
Get a walkthrough of the pipeline that powers JobsPikr’s normalized datasets.
What Good Normalized Job Data Unlocks for You
Once your job data is fully normalized and deduplicated, you start to see something you rarely get from raw feeds: clarity. Patterns that felt fuzzy suddenly become obvious. Trends that looked suspicious finally make sense. And the numbers you present to leadership no longer come with long disclaimers about “variations in source formats” or “possible duplicates.”
Normalized job data is not just cleaner. It is more useful. It gives your team the confidence to make decisions based on facts instead of stitched-together approximations.
Market analysis becomes noticeably more accurate
When every title follows the same structure and every skill is classified the same way, your market maps stop wobbling. You can compare similar roles across industries without worrying that title variations are inflating or distorting your counts. A spike in “Data Engineer” roles is a real spike, not a byproduct of ten different title variations clustering inconsistently.
This matters a lot when your leadership teams use job data to understand what the market is building toward. For example, LinkedIn’s Workforce Report shows how hiring trends shift quickly across US metros. If your internal job data is not normalized, your own view of those shifts becomes a blurred version of the truth.
Skill demand trends become easier to trust
Raw skill data is messy. Employers reuse old templates, list outdated tools, or use inconsistent skill terminology. With normalization, skill entities get mapped to a consistent dictionary. The noise drops, and the real trends rise to the surface.
Your dashboards start showing which skills are genuinely rising, which are stabilizing, and which are fading. This helps workforce planners decide where to invest training budgets, what roles to prioritize, and how to design internal mobility programs based on real market signals.
AI models perform better with structured data
Large language models and predictive systems depend heavily on structured inputs. They need clear titles, clean skill entities, consistent location formats, and deduplicated records. When you feed raw job text into AI systems, you often get hallucinations, strange clusters, or incoherent predictions.
Normalized data gives AI something it can learn from. Instead of guessing, it recognizes stable patterns. Instead of mixing thirty variations of a job title into thirty separate categories, it learns from one unified structure. This is how you build AI readiness into your data pipelines without rewriting everything from scratch.
Teams spend less time cleaning data and more time creating value
This might be the biggest benefit. Clean job data reduces internal friction. Analysts avoid repetitive cleanup tasks. Integration teams stop dealing with inconsistent fields. Leadership gets consistent reporting. Models get stable training data.
You remove the friction that slows everything down. Suddenly, your team can focus on strategy instead of elbow-deep cleanup work.
How Large Workforce Teams Use Normalized Job Data in the Real World
You can usually tell when a team is working with normalized job data because their insights feel steady. Their dashboards line up with what is happening in the market. Their forecasts make sense. And their reports stop bouncing around month to month just because job boards changed formatting or employers rewrote old descriptions. This stability comes from treating normalization as a core data infrastructure layer, not an afterthought.
A before-and-after view of normalization in practice
Here is what raw job data looks like when a talent intelligence team first receives it. You see five variations of the same job title. You see skills wrapped inside long descriptions. You see location fields that switch between abbreviations, full state names, and hybrid tags. And you see the same job repeated across three or four different sources.
Once normalization is applied, everything settles. All the title variations collapse into a single standardized label. Skills break into clean, structured entities linked to the same dictionary. Duplicate jobs merge into a single canonical posting. The result is a dataset that behaves the same way every time you run analysis on it.
This one change lets teams build job families more easily, detect skill gaps more accurately, and deliver reporting that survives scrutiny.
Deduplication keeps hiring trends honest
One of the most overlooked issues in workforce analytics is duplication. When the same job appears across multiple sources, your dashboards suddenly show artificial spikes. It looks like hiring has doubled when nothing has changed.
Deduplication stops this from happening. It compresses identical or near-identical jobs into a single record, so your trend lines reflect real behaviour. This is especially important when analysing skill shortages, regional hiring shifts, or competitive hiring activity. If you do not remove duplicates, you end up reacting to illusions instead of actual demand.
Clean data supports real strategic planning
When a dataset is normalized and deduplicated, teams can work more confidently. They can compare roles across companies without worrying that title quirks are skewing the data. They can track emerging skills without manually cleaning each data pull. They can measure how quickly a competitor is hiring for a certain function without second-guessing the numbers.
A clean, consistent dataset turns job data into a strategic asset instead of a weekly cleanup project. It makes everything downstream more reliable: market intelligence, compensation benchmarking, internal mobility work, and even long-term workforce planning.
How Data Deduplication Fits into the Normalization Pipeline
Normalization gets most of the attention because it shapes the structure of your job data, but deduplication is what protects the accuracy of that structure. Without it, even the best standardized dataset becomes distorted. You end up doing all the hard work of cleaning and mapping, only for the final numbers to get inflated by repeated versions of the same role.
Duplicate job posts appear more often than people think
Most companies publish the same job across multiple channels. They post on their career site, they push the listing to job boards, and some boards redistribute those listings to partner sites. Even when the content looks slightly different, the job itself is the same opening.
Large employers, staffing agencies, and RPO firms amplify this effect. When they manage hiring for multiple clients, they often publish identical roles with minimal variation. Raw feeds do not know that these listings come from the same source. To a machine, they are separate signals, which creates an inflated sense of market demand.
This is why deduplication matters. It restores the true count of available roles instead of letting distribution patterns skew your analytics.
Deduplication relies on matching patterns, not exact strings
You cannot rely on exact text matching to find duplicates because job posts rarely match word-for-word. Companies tweak titles, edit descriptions, and update details over time. Good deduplication uses deeper signals. It looks at combinations of fields such as company name, job title, location, posting date, and text similarity. When several of those align, the listings are treated as versions of one job instead of separate openings.
This approach keeps your dataset grounded. It ensures one opening counts as one opening, even if it appears across ten sources with small changes.
Clean, deduplicated data improves every trend you track
Skill demand becomes more realistic. Hiring volume stops jumping unexpectedly. Regional comparisons stop getting inflated by syndicated posts. Workforce planning stops reacting to noise.
Deduplication does not change the richness of your dataset. It filters out repetition, so the signals reflect actual employer intent, not the distribution habits of job boards.
Ready for Clean, Consistent Job Data?
Get a walkthrough of the pipeline that powers JobsPikr’s normalized datasets.
What Technical Managers Should Look for in a Normalized Job Dataset
Once teams understand how normalization and deduplication work, the next step is figuring out whether a dataset is actually ready for production use. Not every provider applies the same quality standards. Some normalize lightly, some deduplicate aggressively, and some skip core steps entirely. Technical managers and integration teams need a clear way to evaluate whether a dataset can support long-term analysis, AI modeling, and operational workflows.

Consistency across titles, skills, and locations
A dependable normalized dataset keeps the structure steady across every record. Titles follow a shared vocabulary. Skills use one unified dictionary instead of random tokens. Location fields follow a consistent format that works across regions and countries.
If a dataset still shows unpredictable title variations or inconsistent location strings, that is a sign that the normalization layer is thin. Good data should feel predictable. You should be able to build queries, pipelines, and dashboards without constantly adjusting for edge cases.
Transparency in how normalization decisions are made
Normalization does not work in the dark. Teams need to see how titles map to standardized categories, how skills are extracted, and how locations are resolved. A trustworthy provider should share documentation, field definitions, and mapping logic. They should also keep a record of the original text so you can audit any decision when needed.
This transparency matters most when you want to build AI models on top of the data. If you cannot trace how a field was created, you cannot troubleshoot or reproduce results later.
Strong deduplication logic that handles partial matches
Deduplication is more than removing exact duplicates. It should collapse near duplicates that differ only in formatting, minor text edits, or reposting patterns. This requires a combination of rule-based checks and similarity scoring.
If duplicate jobs slip through, your market trends start to drift. If deduplication is too aggressive, you lose real data. The best systems strike a balance and continually refine their matching logic based on new patterns in the job ecosystem.
Clear taxonomy alignment that keeps the dataset stable
A well-designed taxonomy is the backbone of normalized job data. Everything flows from it. If the taxonomy is inconsistent or poorly maintained, the normalized dataset becomes unstable over time. Job families should remain consistent. Seniority structures should follow clear logic. Skill clusters should map cleanly to real-world usage.
Teams should look for providers that treat taxonomy as a living system rather than a one-time setup. Job titles evolve. Skills expand. Taxonomy requires ongoing care.
Why Normalization Turns Job Data into a Real Strategic Asset
When teams talk about job data, they usually jump straight to the insights. What roles are trending? Which skills are heating up? Where demand is shifting. But none of those insights mean anything if the underlying data is inconsistent. Normalization is the step that makes every downstream activity possible. It converts a chaotic stream of titles, skills, and locations into something stable enough to analyze and automate.
When your dataset is fully normalized and deduplicated, everything becomes easier. Your dashboards behave the same way every week. Your AI models stop tripping over noisy text. Your team stops debating which version of the data is “correct.” And leadership finally gets a view of the market that feels dependable instead of reactive.
This is what separates teams that dabble in job data from teams that leverage it. The difference is not volume. It is structured. If you want job data to support forecasting, compensation planning, competitive intelligence, or long-term workforce strategy, normalization is the foundation you build on, not the afterthought you fix later.
Ready for Clean, Consistent Job Data?
Get a walkthrough of the pipeline that powers JobsPikr’s normalized datasets.
FAQs
What is data normalization in job data?
When people talk about data normalization in job data, they simply mean “making everything follow the same rules.” You take job titles, skills, locations, companies, and all the other fields, and you clean them up so they fit into one standard structure. The original wording stays in the background, but what you work with is a normalized version that is easier to search, compare, and plug into your analytics or AI models.
Why is raw job data so inconsistent across platforms?
Raw job data feels messy because nobody on the employer side is thinking about your database. Each company writes a job title in its own style. Job boards layer on their own formats. Some add structured salary fields. Others leave everything inside a long description. By the time this reaches you, the same role can look completely different across platforms. Data normalization is the step that smooths out those differences, so your system sees one coherent version instead of five slightly different ones.
How does data deduplication improve workforce analytics?
Data deduplication solves a very specific problem. One job gets posted in many places and your system thinks it is seeing many jobs. If you do not deduplicate, your charts tell you hiring has exploded when all that really happened is redistribution. When you apply good deduplication, those near-identical listings are treated as one job. Your trend lines start to reflect real hiring behaviour instead of the way postings are syndicated.
Why does normalized job data matter for AI and machine learning models?
AI models learn from whatever you feed them. If titles, skills, and locations are all over the place, the model spends most of its effort trying to guess what they are. When you give it normalized job data, the hard work is already done. The model sees one consistent way of representing roles and skills, which makes it easier to spot patterns, cluster similar jobs, and make reliable predictions. In short, data normalization gives AI a cleaner starting point.
How do large organizations maintain data consistency at scale?
Large teams usually do not rely on one-off scripts or manual cleanup. They set up a proper job data normalization pipeline. New jobs come in, fields are extracted, mapped against a shared taxonomy, and then deduplicated before anyone builds dashboards or trains models. As new job titles and skills appear, the pipeline and dictionaries are updated. That ongoing loop is what keeps data consistency intact even when the job market keeps shifting.




