
- **TL;DR**
- Why Job Market Data Is Useless Without Normalization
- See How Clean Job Data Changes the Conversation
- What Is Data Normalization in Job Intelligence?
- Why Skills Taxonomy Is the Backbone of Job Data Normalization
- See How Clean Job Data Changes the Conversation
- Turning Millions of Wild Job Posts into One Clean Standard
- Why Normalization Matters for AI Models, Hiring Teams, and L&D Leaders
- Real World Example: From 2 Million Raw Posts to a Clean Skills Taxonomy
- Implementation Guide: How Companies Build a Normalized Job Dataset
- The Strategic Impact: Why Normalization Is Now a Competitive Advantage
- Clean Job Data Isn’t a Luxury Anymore
- See How Clean Job Data Changes the Conversation
- FAQs
**TL;DR**
Most people think the power of job data comes from scale, millions of postings, thousands of companies, and endless skills. But the real power kicks in only after you normalize it. Normalization takes all those messy titles, inconsistent skills, and uneven job descriptions and turns them into one clean, comparable standard.
When you do that, patterns suddenly become visible. Emerging roles stop hiding behind creative job titles. Skills become measurable instead of subjective. Workforce trends stop contradicting themselves. In other words, normalization gives job intelligence the structure it needs to be trustworthy: for AI models, for L&D teams, and for any company trying to make sense of the labor market.
If you’ve ever wondered why job data feels chaotic, repetitive, or impossible to analyze at scale, the answer is simple: you’re looking at unnormalized data. Clean it, standardize it, and map it to a consistent skills taxonomy, and the entire picture changes.
Why Job Market Data Is Useless Without Normalization
Before we get into schemas, taxonomies, or any of the jargon, let’s talk about something anyone who has ever pulled job data has felt: the mess. The overwhelming, contradictory, impossible-to-align mess.
Pull ten job posts for the same role from ten companies and you’ll see it immediately. One company says, “Data Scientist,” another says “ML Specialist,” a third wants a “Quantitative Analyst,” and a fourth is quietly describing the same job but calling it “BI Engineer.” The roles overlap, the skills overlap, but the language does not. And that language gap is exactly where most workforce analytics fall apart.
The irony is that the data itself isn’t the problem. We have more job data than ever. Job boards, career sites, ATS systems, they’re all publishing millions of postings every month. But volume doesn’t translate to intelligence unless everything speaks the same structural language. That’s where normalization comes in.
Without normalization, you’re not comparing roles. You’re comparing wording.
And wording is unreliable at best, misleading at worst.
A CFO might look at a dashboard and think: “Why did demand for AI Engineers double this quarter?”
When half the companies simply switched from calling them “ML Engineers” to “Applied Scientists.” Same function, different label. No trend at all, just semantics.
That’s the danger. Unnormalized job data creates artificial trends, hides real skills shifts, and makes market signals look like noise. Even AI models struggle with this. They can identify patterns, but if the patterns themselves aren’t standardized, the insights you get are only as good as the inconsistencies underneath them.
Normalization changes the game because it forces all that disorganized input into a single shape. Once everything speaks the same schema, you can finally see what’s happening in the labor market, not just how companies choose to describe it.
If you want to see what normalized job data looks like in practice, you can schedule a quick walkthrough with the JobsPikr team and explore sample datasets, schema structures, and real role mappings.
See How Clean Job Data Changes the Conversation
A quick walkthrough will show you how clean schemas and a real skills taxonomy change the way you read the labor market.
What Is Data Normalization in Job Intelligence?

Image Source: knack
Let’s break this down without drifting into textbook territory, because normalization is one of those concepts everyone nods along to… until they try working with raw job data.
At its core, data normalization is the process of taking thousands of different ways companies describe work and turning them into one consistent structure. Not a perfect structure. Not a rigid one. But a shared one where “Software Engineer,” “Backend Developer,” and “Platform Engineer II” all sit under the same standard role so you can compare them meaningfully.
Think of it like translating dozens of dialects into one common language.
The original meaning stays the same, but now everyone can understand it.
When you normalize a job post, you don’t just clean the text. You break the job down into components that can be measured, tracked, and compared across thousands of companies. This is where things start becoming useful for hiring teams, L&D, and, increasingly, AI systems.
How does a normalized job schema make workforce analytics reliable?
A “job schema” is simply the template your system uses to interpret every posting.
Without one, each post is a free-floating paragraph. With one, every post becomes structured data.
A normalized job schema usually includes things like:
- standardized job title
- mapped job family and sub-family
- seniority level
- core responsibilities
- required vs. preferred skills
- tools, platforms, or certifications
- experience and education indicators
None of these elements are new. What is new is treating them as consistent fields rather than inconsistent text fragments scattered across job boards.
Once job posts are converted into the same schema, you start seeing the world differently:
- You can tell which companies are truly hiring for AI-heavy roles versus those just adding “GenAI” into the job description.
- You can measure how often certain skills appear in real hiring requirements, not just in survey responses or assumptions.
- You can run honest apples-to-apples comparisons across industries and geographies.
In other words, the schema becomes the foundation for every analysis that follows.
What does a normalized skills taxonomy look like in practice?
This is where normalization gets deeper. Standardizing job titles is one thing. Standardizing skills is another.
A skills taxonomy acts like the backbone of your dataset. It defines what each skill means, how skills relate to one another, and where each skill sits in the broader ecosystem of work.
But companies don’t make this easy. One company asks for “Python scripting,” another says, “Python programming,” a third wants “Python automation,” and the fourth just writes “Python.” All valid. All different. Without a taxonomy, you end up treating these as separate signals. With a taxonomy, they collapse into one concept, Python, with variations mapped underneath.
When you combine a normalized job schema with a normalized skills taxonomy, something important happens:
You stop guessing what roles require. You start knowing.
This is the moment when messy job market data turns into something you can build strategy on.
If you want to see how this works inside a real dataset, including the schema, the taxonomy, and the role mappings, you can always request a sample from the JobsPikr team and explore it firsthand.
Why Skills Taxonomy Is the Backbone of Job Data Normalization
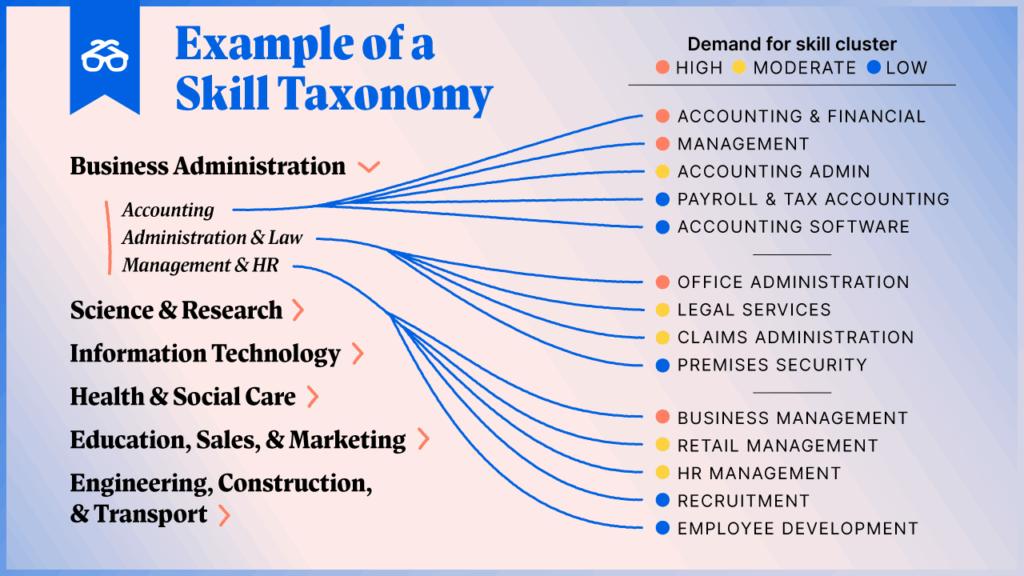
Image Source: signalhire
If normalization is the engine, the skills taxonomy is the fuel that keeps everything running clean. Titles can be misleading, responsibilities can be vague, and job families differ from one company to another. But skills? Skills cut through the noise. They describe the actual work being done, regardless of how creatively a company names the role.
When organizations talk about being “skills-first,” this is what they mean: stop relying on what people call the job, and start relying on what people do in the job.
A well-designed skills taxonomy becomes the anchor that keeps your entire dataset honest and comparable, whether you’re analyzing 50 job posts or 5 million.
What is a skills taxonomy and why do HR teams rely on it?
At a basic level, a skills taxonomy is a structured list of skills but don’t let the simplicity fool you. The real value is in how those skills are categorized, related, and contextualized.
A strong skills taxonomy defines:
- foundational skills (communication, problem-solving)
- technical and domain-specific skills (SQL, machining, risk modeling)
- emerging skills (LLM fine-tuning, prompt engineering)
- tools and technologies (Power BI, Kubernetes, Figma)
- adjacent or complementary skills that naturally cluster
HR teams, L&D strategists, and workforce intelligence builders rely on this because it solves three big problems:
- Skills language is inconsistent: Different companies, teams, and even managers use different words for the same capability. A taxonomy cleans that up.
- Skills change faster than roles: You can’t rebuild job architecture every six months, but you can keep your skills taxonomy updated to reflect market shifts.
- Skills reveal patterns that titles hide: A role that looks new might just be a remix of familiar skills. A taxonomy helps you see that immediately.
Without this backbone, job data analysis becomes guesswork.
Skills taxonomy vs skills ontology: What’s the difference and why does it matter?
People often use these words interchangeably, but they’re not the same thing.
- A skills taxonomy is hierarchical.
It organizes skills into categories, sub-categories, and families. Think of it as the clean, structured outline of the skills landscape. - A skills ontology is relational.
It goes beyond categories and maps how skills connect, reinforce each other, or appear together in real job contexts.
Here’s why the distinction matters:
A taxonomy helps you organize skills.
An ontology helps you understand them.
For example, “SQL” and “Python” often appear together in data roles. A taxonomy would list them under “technical skills.” An ontology would show that SQL frequently co-occurs with Python, and that both connect strongly to analytics and ML tasks.
This relational insight becomes powerful when you’re trying to predict emerging roles, redesign job descriptions, or build AI models that understand workforce signals.
How do you build a skills taxonomy for global job roles?
There’s no magic button for this and anyone who says otherwise hasn’t built one.
A real-world taxonomy is built the long, honest way:
- Start with raw job signals: You look at the skills employers request, not just what internal frameworks recommend. Real postings reveal the real work.
- Cluster related skills: Not everything employers list deserves to stand alone. Sometimes ten terms collapse into one canonical skill. Other times one overly broad term needs to be split.
- Validate across industries and regions: A skill that means one thing in the US could mean something slightly different in the EU or Asia. Global taxonomies need global calibration.
- Map skill relationships: This is where the ontology layer comes in. You don’t just capture skills you capture how they behave with other skills in real job contexts.
- Iterate continuously: Skills evolve faster than roles. Faster than job families. Faster than org design. The taxonomy isn’t a finished product it’s a living system.
When you structure job data around a taxonomy like this, your normalization suddenly gains depth. You’re not just matching titles. You’re interpreting the actual capabilities behind them.
If you want to see how a skills taxonomy and ontology play out inside a normalized dataset, you can request a demo and the JobsPikr team will walk you through real mappings, real co-occurrence networks, and real market signals.
See How Clean Job Data Changes the Conversation
A quick walkthrough will show you how clean schemas and a real skills taxonomy change the way you read the labor market.
Turning Millions of Wild Job Posts into One Clean Standard
If you’ve ever scraped job data at scale, you know the first feeling that hits you: disbelief. Not because the data is bad, but because every employer seems to be inventing their own version of reality. Ten million postings don’t behave like a dataset. They behave like a crowd — loud, inconsistent, emotional, and rarely aligned.
Normalization is the moment the crowd quiets down enough for you to hear what’s actually going on.
Let’s walk through how that happens.
How does JobsPikr normalize messy job titles?
Job titles are the most misleading part of any job post. They look standardized — until you actually read them. Here’s a simple example.
Three companies post three roles:
- “Customer Insights Strategist”
- “Marketing Analytics Manager”
- “Consumer Data Specialist”
Three different titles. One underlying function.
Without normalization, your dashboards think these are three separate jobs.
With normalization, all three align under a single canonical role — something like Marketing Analyst (Mid-Level) — and the variations get mapped as aliases.
This matters because titles can’t be trusted on their own. Some companies inflate titles for employer branding. Some compress levels. Some add creative labels that sound exciting but mean nothing operationally. Normalization removes the theatrics and leaves the actual job behind.
The title the company writes is the wrapper.
The normalized title is the truth.
How does skills extraction improve role mapping for AI and analytics?
Titles tell one story. Skills tell the real one.
When you extract skills from job descriptions — and then map them into a normalized skills taxonomy — odd things happen in a good way. Jobs that look completely different suddenly connect through shared capabilities. Jobs that look identical fall apart because the underlying skills don’t match.
For example:
A “Product Manager” role at a cloud startup and a “Product Manager” role at a retail company share almost nothing except the label.
But a “Product Manager” at a cloud startup and a “Technical Program Manager” at a cloud enterprise often share 70–80% of their skills.
This is why role mapping works best when you follow the skills, not the title. Once skills are standardized, your model can understand what the job actually requires, not what the job titles pretend to signal.
Skills become the connective tissue.
Titles are just the outer layer.
What happens when you don’t normalize job data?
This is where things break — quietly, and sometimes expensively.
Without normalization:
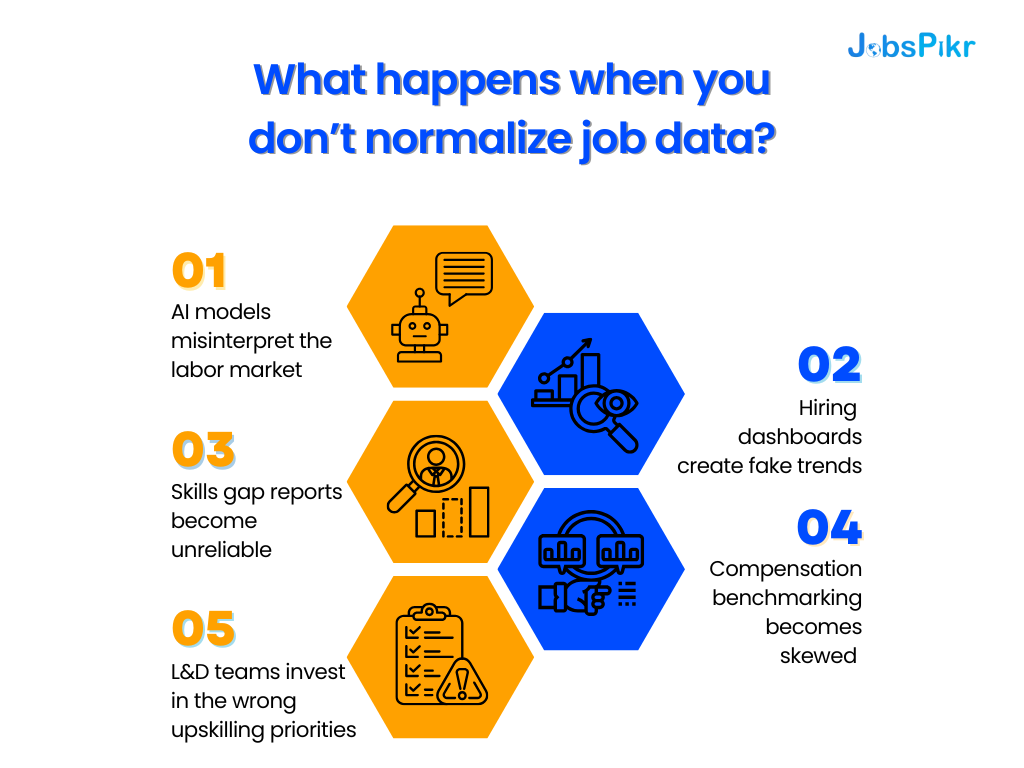
- AI models misinterpret the labor market because they’re learning from unstructured noise.
- Hiring dashboards create fake trends because title-based comparisons hide skill evolution.
- Skills gap reports become unreliable because synonyms and variants get counted as separate requirements.
- Compensation benchmarking becomes skewed because “Engineer II” could mean anything from a trainee to a staff-level role, depending on the company.
- L&D teams invest in the wrong upskilling priorities because skill clusters are invisible in raw data.
This isn’t hypothetical. Even large labor market datasets warn that relying on unnormalized titles can lead to incorrect conclusions, especially when analyzing emerging tech roles or comparing markets across countries.
Normalization doesn’t make the data perfect. It makes the data honest, which is the only way to build analytics you can trust.
If you want to see a sample of how normalization transforms messy job posts into a clean dataset you can analyze, you can book a short walkthrough and preview a real JobsPikr schema in action.
Why Normalization Matters for AI Models, Hiring Teams, and L&D Leaders
Normalization sounds like an engineering concern, but the people who feel its impact most are not sitting in data teams. They’re the ones trying to build AI products on top of job data, run hiring plans in new markets, or design learning strategies that actually match what the market is asking for.
When job data is unnormalized, everyone is working off a slightly different version of reality. Titles don’t line up. Skills aren’t defined. Levels are fuzzy. Each team compensates in its own way, with manual mapping, local spreadsheets, or “gut feel.” It works for a while. Then it stops scaling.
Normalization is what turns all of that improvisation into a shared, stable view of the labor market.
AI Models Need Structured Job Schemas
AI models are great at patterns, but they are terrible at fixing vague thinking. If you feed a model millions of raw job posts with inconsistent titles, overlapping skills, and no clear schema, it will still find patterns. The problem is that you won’t always like what it learns.
A normalized job schema gives the model a backbone. Instead of guessing whether “ML Engineer,” “AI Engineer,” and “Applied Scientist” are similar, you explicitly map them into a consistent structure with shared attributes. The model can then learn from role behavior, not just from language style.
This is especially important if you are building:
- recommendation systems (jobs to candidates, candidates to jobs)
- AI copilots for recruiters or HR teams
- workforce planning tools that forecast demand for roles and skills
When the underlying job schema is normalized, the model’s outputs become less “clever guess” and more “consistent signal.” You reduce weird edge cases, odd groupings, and contradictory insights that come purely from messy input.
Hiring Teams Need Comparable Roles Across Markets
On the hiring side, normalization quietly removes a lot of friction.
If you are hiring across multiple markets, you have probably seen this: the same role is benchmarked differently in each region because everyone is using local titles as the source of truth. HR Business Partners in India, the US, and Europe end up arguing less about compensation and more about whether roles are even comparable.
With normalized roles and a standard job schema, comparisons become much cleaner:
- You can see how one normalized role behaves across geographies, industries, or company sizes.
- You can strip away creative titles and focus on the actual content of the job.
- You can benchmark demand, compensation, and time-to-fill against a stable definition, not a moving target.
This doesn’t just help with external hiring. Internal mobility starts to benefit as well. When internal roles are aligned to the same schema used for external data, candidates inside the company finally see clear, honest pathways: what counts as a lateral move, what is a step up, and which skills actually bridge the gaps.
L&D Leaders Need a Stable View of Skills
For L&D and talent development, normalization is the difference between a noisy wish list and a grounded roadmap.
Most L&D teams hear some version of the same message:
“Everyone needs to learn AI.”
“We need more data skills.”
“We should upskill people into product roles.”
Good intentions. Not actionable.
Once job data is normalized and mapped to a consistent skills taxonomy and skills ontology, those vague demands turn into something much more specific:
- which skills show up consistently in critical roles
- which skills are emerging but still underrepresented internally
- which clusters of skills tend to move together when people change roles
Now, L&D is not just responding to leadership’s intuition. They are designing programs that track directly to how the market defines work. A “data literacy” initiative becomes a clear sequence of skills drawn from real job requirements, not a generic training bundle.
Normalization Creates a Shared Language Between Data, HR, and the Business
Maybe the most underrated benefit of normalization is cultural, not technical.
Without a normalized job schema and skills taxonomy, each team builds its own vocabulary. Data teams talk in variables and entities. HR talks in grades and families. Business leaders talk in headcount and budgets. Everyone is right in their own frame, and slightly misaligned with everyone else.
Once you normalize, you force everything through the same lens:
- one standard way to define a role
- one standard set of skills attached to that role
- one standard mapping from job data to business questions
Suddenly, when someone says “we need more senior data talent in EMEA,” there is a clear analytic object behind it. You can pull all normalized roles that match, their skills, their compensation ranges, and their hiring trends, without inventing a new definition every time.
That is the real payoff: fewer semantic arguments, more decisions grounded in the same dataset.
If you want to see how this looks when it’s fully wired into a job data pipeline, you can book a short demo with JobsPikr and walk through a normalized job schema, skills taxonomy, and role mapping inside a real environment instead of a slide deck.
Real World Example: From 2 Million Raw Posts to a Clean Skills Taxonomy
Nothing explains normalization better than seeing what actually happens when you take a huge, messy dataset and force it into a clean structure. So let’s walk through a real-world scenario. No client names. No proprietary details. Just the kind of transformation that happens when you process millions of job posts through a normalized schema and a skills taxonomy that holds up under pressure.
This is the kind of dataset most teams think they want — until they see the raw version.
The Messy Reality of Raw Job Data
Imagine pulling in two million job posts from dozens of sources over a few months. At first glance, it’s exciting. It feels like insight waiting to be unlocked. But when you actually open the dataset, you see what’s really going on:
- Titles describing the same job in ten different ways
- Skills that appear differently depending on the writer (“SQL scripting,” “SQL developer experience,” “hands-on SQL,” “SQL proficiency”)
- Responsibilities that range from poetic to vague to outright contradictory
- Tools and technologies buried inside long paragraphs with inconsistent formatting
You also notice something surprising: the same company describes the same role differently across different departments. What looks like inconsistency at the market level also exists inside individual organizations.
Before normalization, you don’t have a dataset.
You have a collage.
Hiring teams can’t use it.
AI models misread it.
L&D teams can’t extract skill signals from it.
It’s volume without structure, which is another way of saying noise.
The Clean Outcome After Normalization
Now here’s what happens when that same dataset goes through a disciplined normalization pipeline — one that applies a unified job schema, a global skills taxonomy, and an ontology-driven skill relationship model.
Suddenly, everything snaps into place.
- Thousands of original job titles collapse into a few hundred standardized roles.
- Skills that appeared under dozens of labels get mapped to a smaller, cleaner set of canonical skills.
- Responsibilities begin to form visible patterns across industries and levels.
- Overlapping terms merge into unified concepts (for example, “data storytelling,” “insights communication,” and “presentation skills” become one structured skill).
Even more interesting: Emerging skills that looked rare in raw text become much more visible once synonyms are merged. Instead of seeing five mentions of “LLM fine-tuning,” you now see the full picture — including all the other ways companies described the same capability.
The dataset goes from chaotic to coherent — from text to intelligence.
This is where insights become honest:
- You can see which roles are actually growing in demand
- You can measure skill clusters that predict career pathways
- You can spot emerging capabilities before they hit mainstream adoption
- You can compare markets and industries without worrying that terminology differences are skewing the analysis
At this stage, you finally understand the job market, not just the words companies use to describe it.
The Business Impact of Clean, Normalized Job Data
When this level of structure is applied, teams stop arguing about definitions and start making decisions.
- For a workforce planning team, the normalized dataset becomes the foundation for forecasting demand or redesigning job architecture.
- For hiring teams, it becomes a reliable way to benchmark compensation and refine job descriptions.
- For L&D teams, it becomes the blueprint for building skill-based learning paths grounded in actual market signals.
- For AI teams, it becomes trainable, stable input — not an unpredictable text dump.
Normalization doesn’t just clean data. It stabilizes decision-making.
And in markets where skills evolve faster than roles, that stability is a competitive advantage.
If you want to see this transformation in action — from messy job posts to structured, analytics-ready datasets — you can always schedule a walkthrough with JobsPikr and examine real normalized data, real schemas, and real skill maps instead of imagined examples.
Implementation Guide: How Companies Build a Normalized Job Dataset
Most teams underestimate what it takes to turn raw job posts into something clean, comparable, and useful. They imagine a simple pipeline — scrape, clean, analyze — and wonder why their dashboards never match what they expected. The truth is that normalization isn’t a single step. It’s a sequence. And each step carries its own logic, guardrails, and tradeoffs.
Here’s how companies that take job intelligence seriously actually do it.
Collecting Raw Job Posts from Trusted Sources
Everything begins with the intake layer. If you start with inconsistent or low-quality sources, no amount of normalization downstream will rescue the dataset. Teams that do this well pull from multiple job boards, company career sites, government feeds, and aggregator APIs — but with strict filters around duplication, missing fields, or outdated listings.
The goal here isn’t “as much data as possible.”
It’s “as much usable data as possible.”
When the intake is clean, every other step becomes easier and more reliable.
Applying a Unified Job Schema
Once posts are collected, the next layer is structure. Every job post — no matter how it is written, formatted, or labeled — gets mapped to the same schema. This is where titles, responsibilities, levels, industries, and role metadata are parsed and converted into a standard form.
This is the point where creativity in job titles stops being a problem.
The schema quietly absorbs the variation.
What used to be a text blob becomes a structured record with predictable fields. And that predictability is what makes analytics, benchmarking, and comparison possible across millions of listings.
Mapping Roles to a Skills Taxonomy
After the schema comes the skills layer — the heart of a normalized dataset. Skills are extracted from job descriptions and then reconciled against a canonical taxonomy. Variations merge. Synonyms collapse. Emerging skills get layered in properly instead of being treated as throwaway terms.
This step is crucial because it turns unstructured language about work into measurable signals. The taxonomy becomes the anchor point that makes the entire dataset multilingual, consistent, and future-proof.
Enriching the Dataset with Global Labor Market Signals
Once you have a normalized record of each job post, enrichment adds the context that raw data can’t provide on its own. This might include industry classification, location normalization, experience level estimation, or mapping the role against wider market trends. Enrichment makes each standardized job post more informative and more comparable — across time, geography, and sectors.
This is what allows insights to scale beyond “what did this job post say?”
and into “what does this job post mean in the broader labor market?”
Creating Reusable, Analytics-Ready Datasets
The final step is where everything comes together. Clean, normalized, enriched job records are packaged into datasets that hiring teams, analysts, L&D leaders, and AI developers can use without additional cleanup.
At this point:
- workforce planning teams can run trend analyses
- hiring teams can benchmark roles
- L&D teams can map skills pathways
- AI models can train on clean, structured data
- leadership can see consistent signals instead of contradictory patterns
A normalized dataset stops being a technical asset and becomes a strategic one. It feeds dashboards, forecasting models, salary comparisons, and skill gap analyses without the noise that makes raw data misleading.
If you’d like to see what a fully normalized dataset looks like — schema, taxonomy, ontology relationships, and enrichment — you can book a walkthrough with the JobsPikr team and explore a live sample instead of relying on static slides.
The Strategic Impact: Why Normalization Is Now a Competitive Advantage
Most companies still treat normalization as a backstage technical chore — something the data team quietly handles while everyone else focuses on dashboards, reports, and quarterly insights. But the companies that are pulling ahead in hiring, talent development, and AI-readiness have realized something different: normalization isn’t a backend task. It’s the competitive moat.
When you normalize job data well, you get a head start in three places that matter right now: AI performance, workforce planning accuracy, and skills-based decision-making. Let’s break down why.
AI Search and AI Models Reward Structured, Normalized Data
Large language models are powerful, but they’re not magicians. If you feed them inconsistent job data, they’ll generate inconsistent conclusions. That’s why teams building AI copilots, job-matching engines, search features, or workforce prediction models quietly depend on clean schemas and taxonomies.
Models trained on normalized data behave differently:
- Their recommendations stop oscillating between unrelated roles.
- Their skill extraction becomes more precise because the underlying taxonomy provides structure.
- Their embeddings become more semantically aligned because normalized fields reinforce meaning.
- Their outputs become more explainable because the model isn’t learning from noise.
And this matters for you even if you’re not building your own models. AI search tools — ChatGPT, Perplexity, Claude, and others — already prioritize structured, well-labeled, consistently organized information. When the underlying data is normalized, AI search retrieves it more accurately and positions your insights higher.
In other words, normalization makes your content and intelligence AI-discoverable.
Normalization Strengthens Workforce and Hiring Decisions
Workforce planning is built on comparisons. But comparisons only work if the underlying objects actually match. When job titles vary, skill definitions drift, and responsibilities are written in different styles, strategic planning turns into educated guessing.
Normalization brings order to that chaos:
- A role defined one way in Europe can be compared cleanly to the same role in India or the US.
- Salary benchmarking becomes more honest because you’re comparing standardized roles, not creative job titles.
- Hiring funnels stop producing contradictory trend lines because the dataset stops contradicting itself.
- Geographic demand signals become clearer because markets are mapped against the same schema.
This is how leadership teams shift from “we think…” to “the data shows…”.
Not because the dashboards changed — but because the language of work became consistent.
Standardized Skills Data Unlocks Reskilling, Mobility, and L&D Strategy
Skills are where most organizations struggle. Not because they don’t understand the skills they need, but because they can’t align three things at once: job requirements, internal capabilities, and market signals.
A standardized skills taxonomy removes that bottleneck.
When skills are normalized:
- L&D programs can be built directly from market requirements instead of assumptions.
- Skill gaps can be measured with confidence because the taxonomy creates comparability.
- Internal mobility becomes transparent because roles share a common structure.
- Career pathways become clearer because skills cluster into predictable transitions.
Suddenly, upskilling stops being a general ambition and becomes a practical roadmap.
This is where normalized datasets start paying off beyond analytics. They reshape how organizations think about capability building, promotions, and internal opportunity design.
Normalized Data Enables Predictive Insights Instead of Backward-Looking Reports
The real value of normalization emerges over time. Once you build a clean and consistent dataset, each new month of job postings enriches the history. And with history comes prediction.
Normalized job data enables:
- early detection of emerging roles
- forecasting of skills that are rising or declining
- identification of market saturation points
- mapping of which industries shift first and which follow
- understanding of how skill combinations evolve before job titles change
This is the kind of intelligence companies pay millions for through consultants — and it becomes possible only because the normalized dataset eliminates the distortions and blind spots that raw job posts create.
If you want to see how normalized datasets power real-time signals and predictive insights, the JobsPikr team can walk you through live trend graphs and role evolution timelines built entirely on structured job data.
Clean Job Data Isn’t a Luxury Anymore
There was a time when having access to job postings felt like an advantage in itself. If you could gather enough data, you felt ahead of the curve. But that edge is gone. Everyone has access to job posts now — job boards, aggregators, AI tools, enterprise HR systems. The real difference comes from how well you structure what everyone else is simply collecting.
Clean, normalized job data is no longer a “nice to have.” It’s the baseline for every serious decision involving talent. Whether you’re trying to understand new roles, forecast hiring needs, build internal career paths, or train AI models, you won’t get far if your dataset is still arguing with itself.
Normalization doesn’t fix everything, but it fixes the part that matters most: it creates consistency in a world where every company uses its own language to describe work. Once that consistency is in place, everything downstream — insights, predictions, strategy — becomes clearer and more defensible.
This is the shift happening across the industry: organizations are moving from collecting job posts to building job intelligence. And normalization is the turning point.
If you want to see how normalized job data behaves in a real environment, you can schedule a walkthrough with the JobsPikr team and explore a sample dataset, the underlying schema, and a live skills taxonomy instead of relying on assumptions.
See How Clean Job Data Changes the Conversation
A quick walkthrough will show you how clean schemas and a real skills taxonomy change the way you read the labor market.
FAQs
What are skills taxonomies?
A skills taxonomy is basically a tidy way of keeping track of the skills people use at work. Instead of hundreds of scattered terms floating around, a taxonomy groups them in a way that actually makes sense. Think of it as the difference between having random notes on your desk versus having everything filed in the right drawer. Companies use it so hiring managers, L&D teams, and analysts aren’t all talking about skills in completely different ways.
How to build a skill taxonomy?
You build a skill taxonomy the same way you build anything meaningful: by starting with the real world. You gather skills from actual job descriptions, talk to people who know the work, and pull signals from the market. Then you clean the list — combine terms that mean the same thing, remove fluff, and organize what’s left into groups that feel natural. After that, you test it. You see if it reflects how work is truly done. And you keep adjusting it as new skills show up or old ones fade.
What is the skills taxonomy structure?
A skills taxonomy usually has a simple shape. At the top, you have broad buckets — things like technical skills or leadership skills. Under each bucket, you break it down into smaller groups, and inside those groups you list the specific skills. It’s not meant to be rigid or academic. The structure just helps you make sense of how skills relate to each other so you’re not treating every term like its own universe.
What are the 4 steps of taxonomy?
When people talk about “steps,” they’re really talking about the natural workflow behind organizing skills. First, you gather the skills. Next, you clean the list so it’s not bloated with duplicates or vague wording. After that, you group the skills in a way that reflects how they’re used. And finally, you check your work — with real roles, real teams, and real feedback — and refine it over time. That’s it. Nothing mystical. Just a thoughtful way of getting to clarity.
Why is a skills taxonomy important for workforce planning?
Workforce planning falls apart quickly if every team uses its own language to describe skills. A taxonomy prevents that. It gives everyone the same reference point, so when someone says “we need stronger data capabilities,” you can actually see what that means — which roles, which skills, and which gaps. It removes the ambiguity that usually slows planning down.
How does a skills taxonomy support internal mobility?
Internal mobility becomes a lot easier when roles are described through the same set of skills. Employees can see which roles they’re already close to, managers can spot people who are ready for a stretch role, and L&D teams can build programs that directly map to real opportunities. Instead of guessing whether someone can move from Role A to Role B, you can just compare the skills and see what’s missing.
Is a skills taxonomy the same as a competency framework?
No, they’re different. A skills taxonomy tells you what someone needs to know or be able to do — the actual capabilities. A competency framework is more about how someone behaves or performs on the job. Skills are the building blocks of the work itself. Competencies describe the approach or style. Both matter, but they don’t replace each other.




