
- **TL;DR**
- Why Does “AI-Ready Data” Matter So Much for Job Intelligence Today?
- What Does “AI-Ready Job Data” Mean and How Do You Build It?
- Turn Your Labor Data into a Competitive Edge
- Why Is Job Data So Hard to Make AI-Ready in the First Place?
- What Does the Anatomy of an AI-Ready Job Dataset Look Like (and How Do You Know Yours Is Ready)?
- Turn Your Labor Data into a Competitive Edge
- How Does AI-Ready Job Data Power Real-World AI in HR and Workforce Planning?
- Why Do Most Job Datasets Still Fail AI-Readiness Tests (and How Can You Fix Them)?
- Making Job Data AI-Ready: A Practical Framework You Can Actually Implement
- The Business Advantage of AI-Ready Job Data (and Why It Pays Off Fast)
- Turning Job Data Chaos into AI-Driven Clarity
- Turn Your Labor Data into a Competitive Edge
- FAQs:
**TL;DR**
If you want reliable AI outcomes from labor market data, start with the basics: ai ready data is structured, well-labeled, de-duplicated, fresh, and governed against bias. Most “job data for AI” fails because titles, skills, locations, and compensation fields are inconsistent across sources, records are incomplete, and provenance isn’t tracked. When you normalize job titles, map skills to a common taxonomy, add consistent location and compensation fields, and run bias and quality checks, your models stop guessing and start learning. The payoff is simple: cleaner inputs, faster experiments, and decisions you can defend.
What this article covers: how to define ai ready job data, why typical labor market datasets miss the mark, a practical framework to fix it (schema, labeling, governance, bias control, freshness), and where this unlocks value in talent intelligence, compensation, and workforce planning.
Who it’s for: HR analytics leads, research analysts, and business leaders who want to make job data usable by AI systems without months of cleanup.
Why Does “AI-Ready Data” Matter So Much for Job Intelligence Today?
Let’s be honest, when people talk about AI, they usually skip the boring part: the data. But that “boring” part is exactly where most AI projects fail.
AI doesn’t think in intuition. It learns from examples, millions of them. And if those examples are inconsistent, incomplete, or biased, no amount of clever modeling can save the outcome.
Take job data. Every day, thousands of companies post openings using their own formats and vocabularies. One firm says Software Ninja, another says Senior Developer, and a third says Backend Engineer (Python). To a human, the overlap is obvious. To an algorithm, they’re completely different signals.
That’s the problem. Most labor market datasets are built for humans to read, not for machines to learn from. They’re full of irregular titles, inconsistent skill labels, missing salary fields, and regional naming quirks that confuse pattern-finding models.
AI-ready job data fixes that. It’s data that’s structured, labeled, bias-checked, and continuously refreshed so machines can actually interpret relationships between roles, skills, industries, and geographies.
When your job data is already normalized and mapped to a shared taxonomy, everything changes. Skill-demand forecasting becomes faster. Compensation analytics get sharper. Candidate-matching models stop guessing.
What Does “AI-Ready Job Data” Mean and How Do You Build It?
When someone says AI-ready data, it sounds impressive, but what does it really mean in practice? It’s not a buzzword for “clean data.” It’s a way of saying your data can talk to machines clearly enough that they don’t misinterpret the story.
For job data, that story includes millions of signals: job titles, company names, industries, skills, seniority levels, compensation, and geographies. The problem is that most of these signals are written by humans, for humans, full of nuance, shortcuts, and cultural context that algorithms simply don’t get.
So let’s unpack what ai ready job data actually looks like.
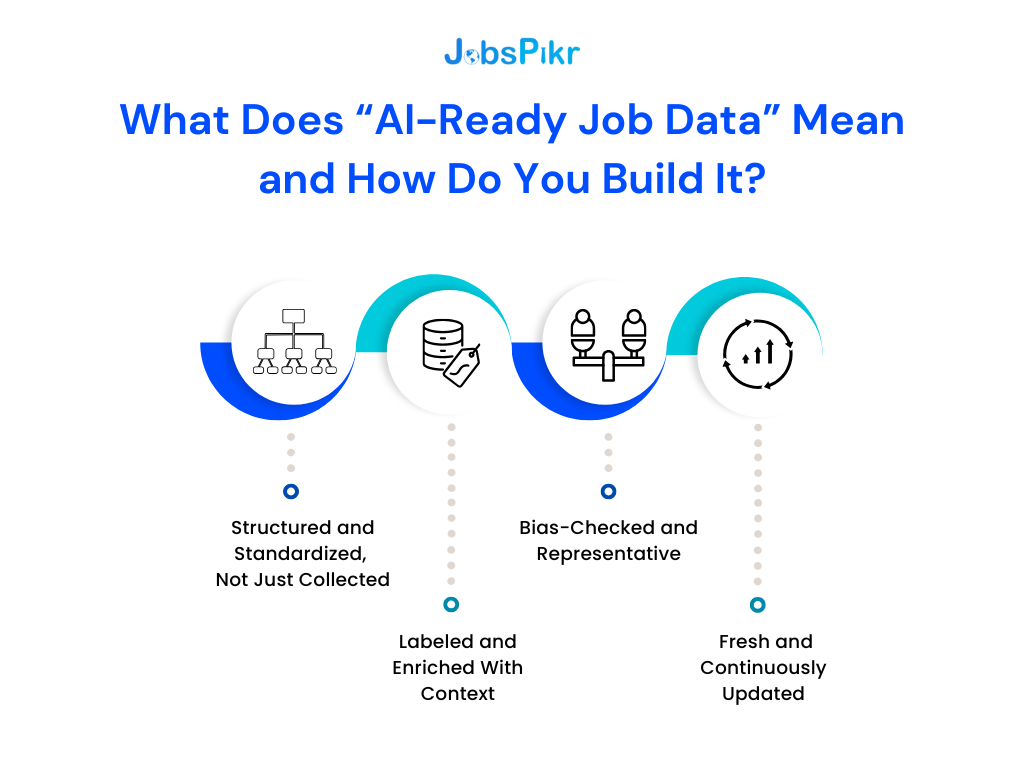
1. Structured and Standardized, Not Just Collected
AI-ready data starts with structure. Each field (title, location, skills, salary, posting date, etc.) needs to exist in a consistent schema, meaning every row follows the same rules.
For instance, “New York, NY” and “NYC” must be recognized as the same location. “Software Engineer III” and “Senior Software Engineer” must map to the same role family.
When your schema isn’t standardized, every query, every aggregation, and every model outcome starts to drift. That’s why schema design is the silent backbone of all AI-driven analytics.
In the case of job data for AI, this means aligning your taxonomy with frameworks like ESCO or ONET, so machines can link job titles and skills to shared concepts instead of guessing their relationships.
2. Labeled and Enriched With Context
Raw data is just text. Labeled data is intelligence.
An AI-ready job dataset attaches meaning to each element, tagging roles with skill clusters, experience levels, and job functions. When “Data Engineer” is tagged with “ETL,” “Python,” “AWS,” and “SQL,” your model understands what that job is, not just what it’s called.
Context labeling also helps when you’re training large models to understand job trends. Instead of feeding a plain-text dump, you give them structured inputs that connect skills, industries, and hiring intent, the difference between noise and signal.
3. Bias-Checked and Representative
Job data reflects the labor market, and the labor market has bias baked in. An AI-ready dataset acknowledges that reality and then corrects for it.
It means identifying whether your dataset over-represents certain industries, geographies, or gender-coded language. (Remember the well-publicized Amazon AI recruiting model that downgraded female applicants because historical data skewed male? That’s what uncorrected bias looks like in practice.)
Modern labor-market data tools use linguistic analysis, normalization, and sampling to ensure balance before the data ever hits a model.
4. Fresh and Continuously Updated
AI models learn from patterns, but those patterns evolve. Skills like prompt engineering didn’t exist a few years ago. That’s why freshness is non-negotiable.
Static datasets can’t reflect how job markets shift weekly. In contrast, ai ready data pipelines are dynamic: they scrape, clean, and validate job postings daily, keeping your training data aligned with the real economy.
When you plug a model into outdated labor market datasets, you’re training it on yesterday’s job world and asking it to predict tomorrow’s.
Turn Your Labor Data into a Competitive Edge
JobsPikr delivers enterprise-grade, AI-ready job datasets trusted by HR analytics teams, researchers, and business strategists across 100+ countries.
Why Is Job Data So Hard to Make AI-Ready in the First Place?
On paper, job data looks structured: job title, company name, location, description, salary. But feed it into a machine, and you quickly realize it’s chaos dressed up in CSV.
The truth is, job data wasn’t designed for algorithms. It was designed for people. And that difference, human-first vs. machine-first, is what makes AI readiness such an uphill battle.
Let’s look at the core issues that keep most labor-market datasets from ever becoming ai ready job data.
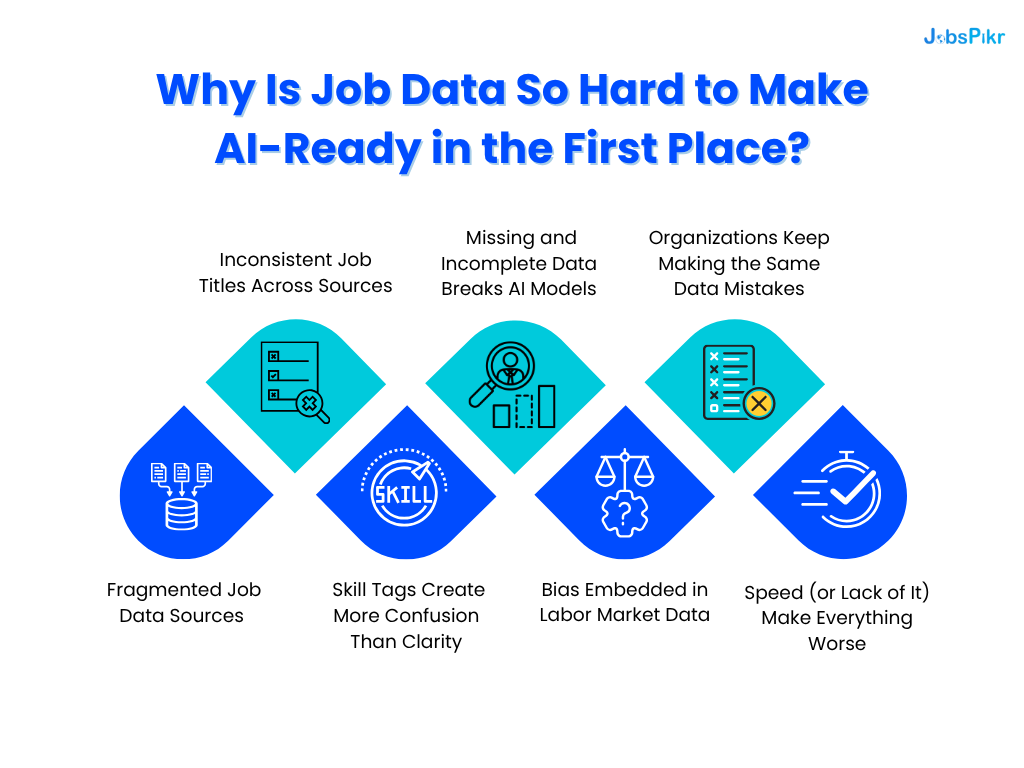
1. Fragmented Job Data Sources
There’s no single place where job data lives. It’s spread across thousands of sources, global job boards, niche recruiters, company career sites, government databases, LinkedIn feeds, and even startup portals.
Each source has its own way of labeling roles, formatting skills, or tagging industries. Some don’t even use structured fields; they just dump everything into HTML.
When you try to combine all of that, you’re merging apples, oranges, and a few random spreadsheets. The result? Duplicate records, inconsistent fields, and partial overlaps that no model can interpret without deep normalization.
2. Inconsistent Job Titles Across Sources
Job titles sound simple, until you compare them side by side. “Sales Executive,” “Account Associate,” “Growth Partner,” and “Business Development Specialist” might all mean the same thing, yet your model treats them as different entities.
Multiply that across industries and geographies, and you get exponential variation. That’s why AI systems trained on unstandardized data struggle to connect related roles, over- or under-counting demand trends in unpredictable ways.
AI-ready job data solves this through title normalization, mapping every variation to a canonical form using taxonomies like ESCO, O*NET, or JobsPikr’s internal ontology.
3. Skill Tags Create More Confusion Than Clarity
Skills are even messier than titles. Different employers describe the same skill in wildly different terms: “data storytelling,” “dashboarding,” “Power BI reports,” “visual analytics.” Unless you unify them into a single entity, your AI model can’t detect patterns or emerging trends accurately.
Even worse, many postings mix technical and soft skills with no hierarchy, making it hard to know which ones are core, complementary, or nice-to-have. AI-ready pipelines handle this with skill clustering, grouping related skills, ranking them by frequency, and linking them to standardized taxonomies.
4. Missing and Incomplete Data Breaks AI Models
Not all job postings are complete. Some lack salary ranges. Others skip experience levels or omit skill lists altogether.
That missing context creates data sparsity gaps that cause your model to misclassify, misweight, or ignore critical relationships. If 30% of postings in your dataset have blank salary fields, your compensation forecasting model isn’t “learning”, it’s guessing.
AI-ready job data fixes this through imputation (filling gaps using correlated data), field validation, and mandatory schema enforcement so every record meets a baseline completeness threshold.
5. Bias Embedded in Labor Market Data
Bias doesn’t just come from algorithms; it starts in the data itself. Job descriptions often contain gender-coded or culturally loaded language. For example, “ninja,” “rockstar,” or “dominant leader” skew male-coded, while words like “supportive” or “collaborative” skew female-coded.
If you don’t detect and neutralize that, your AI inherits and amplifies it. That’s exactly what happened with Amazon’s early AI recruiting model, which learned to prefer male résumés because historical data favored them.
AI-ready job datasets apply bias audits, linguistic scoring, and balanced sampling to prevent those distortions from being learned as “truth.”
6. Organizations Keep Making the Same Data Mistakes
Because they think cleaning once is enough. Most teams approach job data readiness as a one-time project instead of a continuous process.
The reality is: data drifts. New job titles appear, taxonomies evolve, and scraping sources change their HTML layouts. Without ongoing monitoring and schema refreshes, even the cleanest dataset decays in weeks.
That’s why ai ready data isn’t static; it’s operational. It requires automated quality checks, retry logic, and schema versioning built into your data pipeline.
7. Speed (or Lack of It) Make Everything Worse
Job data ages fast. A posting that’s valid today could expire or update tomorrow. So by the time you finish cleaning your dataset manually, half your inputs might already be outdated.
That’s why freshness or data velocity is now a key dimension of AI readiness. Real-time crawling and scheduled refreshes ensure your model learns from the current labor market, not last quarter’s. Without this, even a perfectly structured dataset becomes irrelevant within weeks.
What Does the Anatomy of an AI-Ready Job Dataset Look Like (and How Do You Know Yours Is Ready)?
So, let’s say you’ve collected millions of job postings. They’re sitting in a database, clean enough to browse, maybe even dashboard-ready. But are they AI-ready? Not yet. Because “clean” and “AI-ready” aren’t the same thing.
Clean data means it’s formatted neatly for human consumption. AI-ready data means it’s structured, consistent, bias-audited, and traceable enough for a model to learn from without guesswork.
Here’s what the anatomy of truly ai ready job data looks like and how to spot the difference between cosmetic cleanup and genuine readiness.
1. Does Your Dataset Have a Defined Schema?
Every AI-ready dataset starts with a schema, a consistent skeleton that defines how every record should look. For job data, that schema typically includes:
- Core fields: job ID, title, company, location, posting date, and source
- Descriptive fields: job type, category, experience level, salary range, and education requirement
- Relational fields: standardized skills, mapped industries, role families, and function categories
A proper schema ensures your models know where to look for the same type of information every time. Without it, even simple queries like “show me AI engineer roles in Europe” turn into chaos.
2. Are Titles and Skills Normalized Across Sources?
The second layer of anatomy is semantic normalization, making sure titles and skills mean the same thing everywhere. Your dataset should know that “ML Engineer” and “Machine Learning Engineer” represent one role, not two.
JobsPikr, for instance, applies multi-stage entity resolution to align job titles and skill names with standardized taxonomies (O*NET, ESCO, and proprietary ontologies). This alignment allows models to understand equivalence, the foundation for accurate skill clustering, market sizing, and trend prediction.
3. How Complete and Enriched Are Your Records?
AI can’t learn what isn’t there. A posting missing salary data or experience level might look harmless, but those blanks multiply. When thousands of them exist, your predictions lose context and accuracy.
AI-ready job data uses enrichment methods like salary inference (based on similar roles in the same market), inferred experience levels, and inferred company size tiers. This doesn’t mean “made up” data it means statistically grounded imputation backed by real patterns across the dataset.
4. Is Your Data Bias-Audited and Representative?
Bias is subtle but dangerous. If 80% of your postings come from tech companies in North America, your model learns that “jobs” = “tech in the US.” That’s not intelligence, that’s tunnel vision.
An AI-ready dataset includes bias reports: region balance, industry diversity, gendered language checks, and sampling weights that prevent dominance by one cluster. Think of it as quality assurance for fairness.
5. Can You Trace Every Record Back to Its Source?
Transparency builds trust. Every AI-ready dataset must include data lineage metadata that shows where each record came from, when it was scraped, and how it was transformed.
This provenance data makes your output auditable and compliant with emerging AI regulations (like the EU AI Act). When you can’t explain your data’s origin, you can’t explain your model’s behavior.
6. How Fresh and Version-Controlled Is It?
Job data changes faster than almost any other dataset. Roles evolve monthly; titles and skills mutate weekly. An AI-ready pipeline isn’t a one-time export, it’s a living stream.
JobsPikr, for instance, updates its labor-market dataset daily, version-tagging every refresh so clients can track drift over time. That means you can train on “Q4 2024 labor signals” today and compare them with “Q1 2025 shifts” tomorrow, reproducibility built in.
7. Does It Pass the “Machine-Readability” Test?
Finally, the simplest test: if you feed your dataset to a model, can it recognize field relationships without human prompts?
If your schema, normalization, enrichment, and bias layers are aligned, the answer is yes. If not, your model spends 90% of its time decoding inconsistencies before it even starts learning.
AI-readiness is about making that 90% unnecessary.
How Is an AI-Ready Job Dataset Different from a Typical “Clean” (Non-AI-Ready) Dataset?
| Dimension | AI-Ready Job Dataset | Non AI-Ready Job Dataset |
| Schema | Strict, documented schema with required fields (ID, title, company, location, posting date, job type, skills, seniority, salary, industry). | Loose column definitions; optional fields vary by source; missing data tolerated. |
| Title Normalization | Titles mapped to canonical role families (e.g., ESCO/O*NET or proprietary ontology). | Raw titles left as-is; “ML Engineer” ≠ “Machine Learning Engineer.” |
| Skill Normalization | Skills deduped and clustered; synonyms resolved; hard vs soft skills ranked. | Free-text skills; acronyms, synonyms, and vendor terms treated as different items. |
| Completeness & Imputation | Mandatory fields enforced; statistical imputation for salary/seniority where evidence supports it. | Many blanks; no principled gap-filling; models learn from sparse, biased slices. |
| Deduplication | Multi-signal dedupe (title+company+location+fingerprint) to remove reposts/aggregator clones. | Duplicates common; same job counted multiple times across sources. |
| Bias & Representativeness | Linguistic bias checks; geographic/industry balance reports; sampling weights applied. | Over-representation of certain regions/industries; gender-coded language unchecked. |
| Freshness & Drift Control | Scheduled recrawls; daily/weekly refresh; drift metrics tracked over time. | Periodic exports; stale records; no visibility into shifting skills/titles. |
| Provenance & Lineage | Source URL, crawl date, parser version, and transform steps logged per record. | Little to no lineage; hard to audit or reproduce results. |
| Versioning | Dataset versions tagged (e.g., 2025-Q4-v3); reproducible training runs. | Overwritten snapshots; “last updated” only. |
| Governance & QA | Automated tests (schema, consistency, range checks); human QA on edge cases. | Ad-hoc checks; errors discovered during model training. |
| Interoperability | Exports aligned to downstream needs (Parquet/JSONL), with clear data contracts. | CSVs with inconsistent encodings and nested blobs in text fields. |
| Compliance Readiness | Documentation for audits (EU AI Act readiness: purpose, data sources, known limits). | Minimal documentation; hard to defend decisions. |
| Performance Impact | Faster training, less feature engineering, better generalization and fairness. | Long clean-up cycles; brittle models; unpredictable bias and error. |
Quick checkpoint for your team
If you can’t answer “yes” to at least schema, normalization (titles + skills), bias audits, freshness, and lineage, your dataset is not AI-ready yet.
Turn Your Labor Data into a Competitive Edge
JobsPikr delivers enterprise-grade, AI-ready job datasets trusted by HR analytics teams, researchers, and business strategists across 100+ countries.
How Does AI-Ready Job Data Power Real-World AI in HR and Workforce Planning?
It’s easy to think of “AI-ready” as a technical goal, but its real impact shows up in business outcomes. Once job data is cleaned, labeled, and bias-controlled, it stops being just an archive of postings; it becomes a predictive engine for workforce decisions.
Let’s look at how organizations are already using ai ready job data to gain an edge.
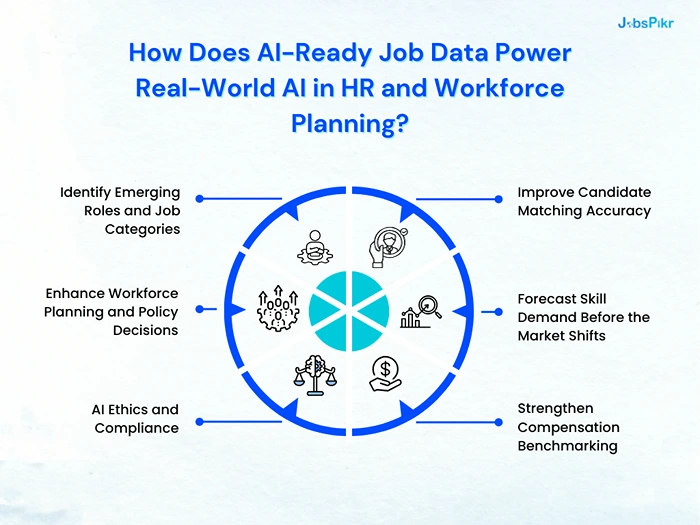
1. Improve Candidate Matching Accuracy
Every recruiter has faced this: hundreds of applications, few true fits. AI-ready datasets fix that by aligning job descriptions and candidate profiles through shared taxonomies.
When titles, skills, and experience levels are standardized, models can match “Data Analyst – Finance” with candidates tagged under “Business Intelligence” or “Reporting Analyst.” That’s the power of structure, finding relevance beyond exact words.
Result: reduced screening time, higher short-list accuracy, and more inclusive hiring decisions.
2. Forecast Skill Demand Before the Market Shifts
AI-ready job data acts as a real-time labor-market barometer. By tracking emerging keywords and new role families, organizations can see tomorrow’s demand today.
For example, by 2027, WEF noted a 44-45% change in core skill sets across all jobs. With structured datasets, AI can spot those pivots early, helping HR teams upskill before shortages hit.
When your models train on normalized, time-stamped job data, they don’t just describe the market; they predict its next move.
3. Strengthen Compensation Benchmarking
Salary intelligence depends on one thing: context. Raw job listings rarely include complete or comparable pay ranges. AI-ready data fills those gaps by inferring missing values from similar roles, regions, and company sizes, building a statistically sound picture of market pay.
That means no more outdated survey PDFs or generic “average salary” estimates.
Instead, HR leaders can adjust compensation models dynamically based on real-time data.
4. Identify Emerging Roles and Job Categories
New titles appear every month: “Prompt Engineer,” “AI Ethics Officer,” “Carbon Data Analyst.”
AI-ready datasets can cluster similar postings and detect when new roles cross a statistical visibility threshold.
That insight helps enterprises design future org charts, adapt training programs, and update talent acquisition plans before the competition does.
5. Enhance Workforce Planning and Policy Decisions
Governments, research institutions, and enterprises all rely on labor-market signals for planning. AI-ready job data enables them to model employment trends, map reskilling needs, and even forecast labor shortages by geography or industry.
OECD research shows that economies using structured, interoperable labor data achieve 20–25% faster policy response times during market disruptions. That speed comes from readiness, not just access.
6. AI Ethics and Compliance
Under frameworks like the EU AI Act, organizations will soon have to prove the traceability and fairness of training data. AI-ready datasets already include lineage metadata, recording where each posting came from, when it was collected, and how it was processed.
That’s the difference between “usable” and “defensible” data. You can’t just train responsibly; you have to show it.
Why Do Most Job Datasets Still Fail AI-Readiness Tests (and How Can You Fix Them)?
Here’s the uncomfortable truth: most job datasets fail before they even reach the model stage.
Not because teams don’t have enough data, but because the data they do have isn’t designed for machines to learn from.
AI isn’t allergic to small datasets; it’s allergic to messy ones. And the mess shows up in subtle but consistent ways.
Let’s unpack why so many organizations struggle to get their job data for AI truly model-ready and what to do differently.
1. Why Do Teams Mistake “Volume” for “Readiness”?
The first mistake is assuming scale equals quality. Collecting millions of job postings sounds impressive until you realize 40% of them are duplicates, outdated, or incomplete.
AI doesn’t care how much data you have, it cares how reliable that data is. More records with inconsistent schemas just multiply your error rate.
Fix: Prioritize coverage after consistency. Build your schema, test normalization logic, and only then scale the crawl. Data without structure is noise at scale.
2. Why Is “Cleaning Once” a Trap?
Many teams treat data readiness like spring cleaning: do it once, and you’re done. But job data ages faster than almost any dataset out there. Titles evolve, skills emerge, and salary norms shift within weeks.
Without automated validation and scheduled recrawls, even a perfect dataset decays. You’re effectively training tomorrow’s model on last month’s labor market.
Fix: Turn cleaning into a continuous operation. Automate schema checks, deduplication, and drift monitoring. Data readiness isn’t an event; it’s a pipeline.
3. Why Does Bias Slip Through Even “Clean” Data?
Bias doesn’t always show up as missing fields. It hides in subtle patterns: overrepresentation of certain industries, gender-coded phrases, or regional skew in sources.
A dataset that looks balanced in quantity can still reinforce bias in quality.
Fix: Run periodic bias audits. Use linguistic models to detect gendered language, geography weighting to balance representation, and human QA to verify ambiguous cases. True ai ready data isn’t just accurate, it’s equitable.
4. Why Does Over-Aggregation Hurt Model Learning?
Some teams overcorrect by oversimplifying. They roll everything into broad buckets: “Tech Jobs,” “Finance Roles,” “Healthcare Careers.”
That may look tidy in a dashboard, but it strips the nuance AI models need to detect skill adjacency or emerging job families. By grouping too early, you erase valuable distinctions.
Fix: Aggregate only after entity resolution. Keep granular features (skills, certifications, seniority, tools) intact. Let the model find patterns before you summarize them.
5. Why Do Metadata and Lineage Get Ignored?
Metadata is like a user manual for your dataset; it tells you where everything came from. Yet most teams skip it because it doesn’t feel urgent. Until regulators or auditors ask for proof.
Without lineage, you can’t reproduce your model’s training environment or defend it when challenged.
Fix: Track provenance from day one. Every record should have a source URL, crawl date, parser version, and normalization step ID. Future you (and your compliance officer) will thank you.
6. Why Do Many Teams Miss the ROI of Readiness?
Because readiness feels like “extra work.” But the ROI is measurable.
According to McKinsey, companies with mature data-governance frameworks are 3x more likely to report revenue growth from AI initiatives.
Readiness isn’t overhead, it’s acceleration. It reduces model debugging time, shortens deployment cycles, and prevents retraining from scratch when something breaks.
Fix: Treat readiness as infrastructure, not admin. The time saved downstream easily outweighs the investment upfront.
Making Job Data AI-Ready: A Practical Framework You Can Actually Implement
Knowing what “AI-ready” means is one thing. Building it consistently is another. Most teams don’t fail because they lack tools; they fail because they skip the order of operations. You can’t normalize before you define the schema, or fix bias before you understand your coverage.
Below is a step-by-step framework that moves you from raw job feeds to ai ready job data, built for scale, fairness, and reproducibility.
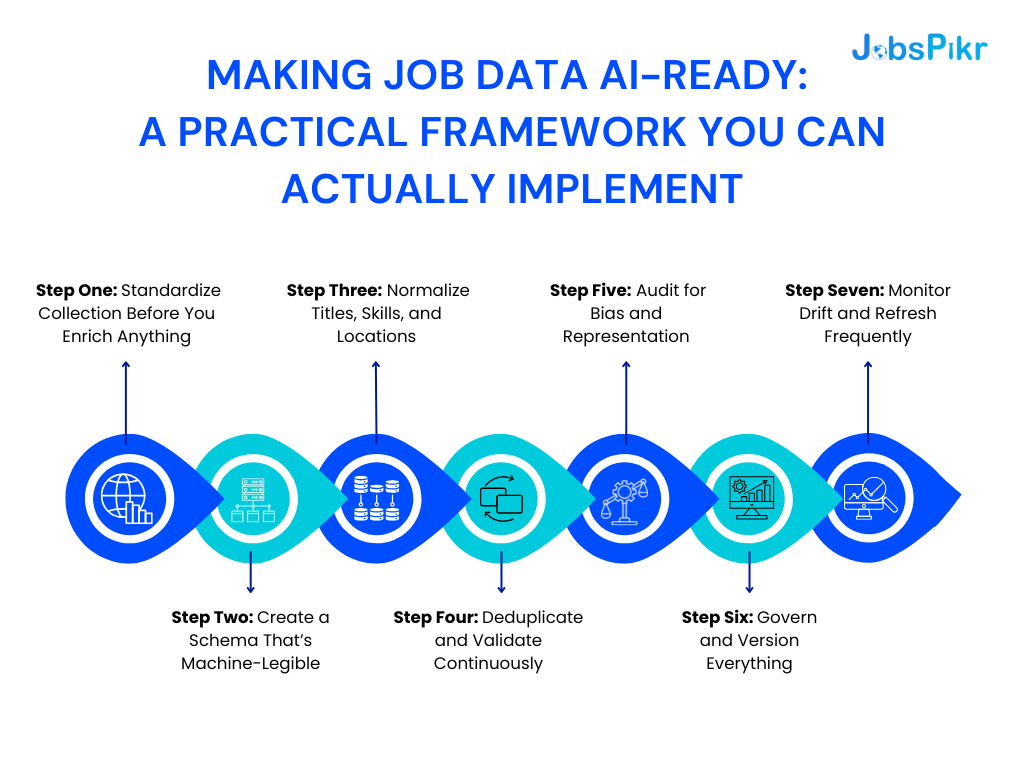
1. Step One: Standardize Collection Before You Enrich Anything
The foundation of every AI-ready pipeline is consistent input. Start by defining which sources matter: global job boards, corporate sites, government feeds, staffing APIs, and stick to them. Don’t add new ones midstream without mapping their fields.
Use automated crawlers or managed scraping services that capture identical fields across all sources: job ID, title, company, location, posting date, and full description. This gives you a consistent raw layer before you even think about analysis.
Pro tip: Tag every record with its source URL and timestamp at ingestion. This single habit will make audit trails effortless later.
2. Step Two: Create a Schema That’s Machine-Legible
You can’t normalize what you haven’t defined. A strong schema tells your systems exactly where every attribute lives and what format it follows. It should include:
- Core fields (title, company, location, date, job type)
- Descriptive fields (experience level, education, compensation)
- Relational fields (skills, industry, role family, seniority tier)
Lock that schema early, enforce it automatically, and reject records that don’t conform. This step alone filters out most downstream noise.
3. Step Three: Normalize Titles, Skills, and Locations
Normalization is where job data for AI becomes structured intelligence. Use rule-based mappers or machine-learning classifiers to align titles and skills with canonical frameworks like O*NET, ESCO, or your own industry taxonomy.
Normalize geographic data to standard codes (ISO-2 for countries, NUTS for EU regions, FIPS for US states). Once normalized, “AI Engineer,” “ML Engineer,” and “Machine-Learning Developer” all point to the same entity, so your model doesn’t treat them as strangers.
4. Step Four: Deduplicate and Validate Continuously
Duplicate postings are the silent killers of AI accuracy. The same job often appears across multiple sites with minor edits. Use multi-signal deduplication (title + company + location + fingerprint).
Then layer in validation rules:
- Minimum description length
- Valid salary range (exclude “$0” or “Negotiable”)
- Detect expired postings through 404 or status checks
This ensures your dataset isn’t inflated by ghosts or clones.
5. Step Five: Audit for Bias and Representation
Even clean data can be biased. Run linguistic audits to detect gendered or exclusionary phrasing, and assess the regional/industry balance of your dataset. A balanced dataset doesn’t just look fair; it trains fairer models.
JobsPikr’s own bias-control layer scores datasets for representation and diversity before releasing them to clients, ensuring equity becomes a design feature, not an afterthought.
6. Step Six: Govern and Version Everything
AI-readiness isn’t only about quality, it’s about accountability. Every change, schema update, or re-crawl should be versioned. Maintain lineage logs: what was added, what was cleaned, what was dropped.
This matters for compliance. Under frameworks like the EU AI Act, you’ll need to prove your data’s origin and transformation steps. Proper governance turns “trust us” into “verify us.”
7. Step Seven: Monitor Drift and Refresh Frequently
Labor-market data decays fast. Roles evolve, titles mutate, salaries fluctuate. Set automated refresh cycles, weekly or daily, depending on your use case. Track field drift: when the same title suddenly appears with new skill tags, it’s a sign the market has shifted.
Keeping your pipelines live ensures your ai ready data doesn’t age out of relevance.
The Business Advantage of AI-Ready Job Data (and Why It Pays Off Fast)
At this point, the concept of AI-ready data might sound like a technical ideal, the kind of thing only data teams get excited about. But here’s the shift: in companies that rely on job or labor market data, AI-readiness isn’t a data project anymore. It’s a revenue strategy.
When your job data is clean, consistent, and bias-controlled, it directly affects hiring efficiency, forecasting accuracy, and strategic agility. Let’s look at how that translates to real-world business value.
1. AI-Ready Data Cuts Time-to-Insight
Every AI model has two costs: the time it takes to train and the time it takes to trust the output. Unstructured data slows both.
When you start with ai ready job data, your models can plug in immediately, no month-long cleanup phase, no trial-and-error normalization. That means faster cycles from ingestion to insight.
In practice, that often cuts model development time by 30–50%, freeing data teams to focus on innovation instead of data wrangling.
2. Lowers Total Cost of Ownership (TCO)
Most organizations underestimate how expensive “bad data” is. Every re-crawl, every retraining, every round of debugging adds invisible cost.
A 2023 MIT Sloan study estimated that poor data quality costs the average enterprise 15–25% of annual revenue in lost efficiency and misinformed decisions. AI-ready datasets change that dynamic: fewer pipeline breaks, less rework, and dramatically lower compute costs.
The long-term ROI compounds, because clean data stays reusable across multiple projects, from compensation analytics to workforce forecasting.
3. Strengthens Compliance and Audit Readiness
In a world where AI accountability is tightening, transparency has become a currency. When regulators or clients ask, “Where did your data come from?” you need an answer, not a shrug.
AI-ready datasets include lineage, versioning, and metadata baked in. That’s not just documentation; it’s protection. It lets you demonstrate ethical sourcing, compliance with frameworks like the EU AI Act, and control over how decisions are generated.
The organizations that invest in data readiness now won’t just comply later, they’ll lead with trust.
4. Improves Predictive Accuracy
Structured job data allows AI models to see connections humans miss. For example, an unnormalized dataset might treat “AI Specialist” and “ML Engineer” as unrelated roles. An AI-ready dataset knows they share overlapping skills, letting your system forecast true demand shifts.
That translates into sharper predictions, fewer false positives, and more reliable labor market models. If your decisions rely on skill forecasts or compensation trends, accuracy isn’t optional; it’s the business itself.
5. Scales Without Rebuilding
The ultimate advantage of readiness is scalability. Once your job data is structured and governed, you can plug it into multiple use cases: skill intelligence, pay benchmarking, diversity analytics, or even LLM fine-tuning.
The same AI-ready base powers all of them. No new scrapers, no manual mapping, no reinvention every quarter.
That’s what separates data-driven organizations from AI-first ones: they don’t start from scratch every time.
Turning Job Data Chaos into AI-Driven Clarity
Most companies already have access to oceans of job data; they just can’t make sense of it fast enough. And that’s not a failure of technology; it’s a failure of structure.
AI doesn’t fix bad data. It amplifies it. That’s why the smartest organizations aren’t asking How do we collect more data? They’re asking how to make the data we already have ready for AI?
When your dataset is structured, bias-audited, and consistently refreshed, your machine learning models stop reacting and start anticipating. They pick up on patterns: skills that are about to surge, pay trends before they spike, roles that didn’t exist last quarter but will define the next one.
That’s what ai ready job data enables: clarity in motion.
It’s what lets a company turn millions of unstructured postings into signals, signals that guide hiring, reskilling, and strategy before the competition even sees the shift coming.
AI isn’t magic. It’s math that depends on good inputs. And in the world of labor market intelligence, those inputs need to be clean, complete, current, and governed, not someday, but from day one.
That’s why data readiness isn’t an IT exercise anymore. It’s a business discipline. Because the difference between reactive analytics and predictive intelligence starts where your data pipeline begins.
So, the next time you hear “we’re building an AI solution,” ask the question that actually matters: Is your data AI-ready?
Turn Your Labor Data into a Competitive Edge
JobsPikr delivers enterprise-grade, AI-ready job datasets trusted by HR analytics teams, researchers, and business strategists across 100+ countries.
FAQs:
1. What are the six principles of AI-ready data?
Think of them as the basics your dataset must pass before it ever touches a model:
Complete: Each record has the essentials (title, company, location, posting date, skills; salary or seniority if available). No key fields left blank.
Consistent: Same meanings and formats everywhere. “NYC” and “New York, NY” resolve to one location; “ML Engineer” and “Machine Learning Engineer” map to the same role.
Accurate: Duplicates removed, obvious errors fixed, ranges validated (no $0–$1,000,000 salaries).
Fresh: Regularly updated. Labor market signals drift fast; yesterday’s snapshot goes stale.
Traceable: You can point to the source URL, crawl date, and the steps used to transform each record.
Fair: Language and source mix are checked for bias. One region or industry doesn’t drown out the rest.
If your job data clears these six, you’re in “ai ready data” territory.
2. What is AI-ready data?
It’s data that a machine can learn from without a human sitting beside it to explain context.
For job data, that means standardized titles and skills, a clear schema, recent updates, and a paper trail for every record. In practice: the model understands that “Senior Data Analyst” in Berlin and “BI Analyst III” in Munich are close cousins, not strangers. That’s ai ready job data—structured, labeled, bias-checked, and current.
3. How to make AI-ready data?
Work in this order (skipping steps is why projects stall):
Lock the schema. Decide required fields and formats up front.
Normalize text. Map titles and skills to shared taxonomies (O*NET/ESCO or your own), standardize locations.
Deduplicate. Merge reposts and aggregator clones using multi-signal matching.
Fill sensible gaps. Impute salary or seniority only when patterns support it; mark what’s inferred.
Audit bias. Scan for gender-coded language and over-represented regions/industries; rebalance where needed.
Add lineage and versions. Record source, time, parser, and transformation steps; tag dataset versions.
Do this continuously, not once. Job data changes weekly; your pipeline should too.
4. What is the meaning of AI-ready?
Ready for models, not just dashboards. “Clean” data is tidy for humans. AI-ready data is machine-legible, consistent across sources, explainable (with lineage), and kept fresh so the patterns it teaches are still true. If you can drop it into a matching model, a salary model, or a skills forecast without a month of prep, it’s AI-ready.
5. Why do AI-ready job datasets matter for HR and workforce planning?
Because they turn hiring from reactive guesswork into repeatable decisions. With standardized titles and skills, you get sharper matching and shorter time-to-fill. With fresh, well-labeled data, you can see skill demand rising before it hits your requisitions and adjust headcount or training plans accordingly. Clean compensation fields make pay bands comparable by market and level, not just rough averages. And with lineage and bias checks, you can defend how models arrived at a shortlist or a forecast—useful for audits, vendor reviews, and stakeholder trust. In short: AI-ready job data cuts noise, reduces risk, and gives HR a planning advantage you can measure.




