
- **TL;DR**
- Why Your Labor Market Insights Keep Changing Even When Hiring Demand Did Not
- What “Dataset Accuracy” Should Mean When You Are Choosing A Talent Intelligence Platform
- Turn Job Postings Into Decision-Grade Workforce Intelligence
- How JobsPikr Turns Raw Postings Into Reliable Insights, Not Just “More Job Data”
- The Biggest Reason Accurate Job Data Fails Is Duplication And Identity Confusion, And How JobsPikr Fixes It
- Turn Job Postings Into Decision-Grade Workforce Intelligence
- Why Your Skill And Role Trends Go Wrong Without Normalization, And What JobsPikr Standardizes
- Bias Removal That Leaders Can Trust, Without Flattening The Market Signal
- Turn Job Postings Into Decision-Grade Workforce Intelligence
- What Data Quality Looks Like In Production, And What JobsPikr Monitors Continuously
- JobsPikr, The Intelligence Layer That Makes Job Data Usable for Decisions
- Turn Job Postings Into Decision-Grade Workforce Intelligence
- FAQs:
**TL;DR**
If you are using job posting data to make workforce decisions, the risk is not volume. It is reliability. Without strong data validation, duplicates, stale listings, and inconsistent labels make insights change because the dataset changed, not because the market did.
Key takeaways
- Poor data quality is costly. Gartner estimates it costs organizations at least $12.9M per year on average.
- Most “demand spikes” are often data issues. Without data validation, duplicates and repost loops can inflate hiring signals and benchmarks.
- Dataset accuracy needs proof. IBM cites research showing >25% of organizations estimate losses above $5M annually from poor data quality, and 7% report $25M+.
- Bias removal is part of trust. The EEOC warns automated hiring tools can create discriminatory outcomes and raise compliance risk, which is why bias removal and controlling ai bias matter when insights inform hiring decisions.
This article explains how JobsPikr applies data validation, normalization, and bias controls to deliver accurate job data you can defend.
Why Your Labor Market Insights Keep Changing Even When Hiring Demand Did Not
If you have ever pulled the same report two weeks later and got a different story, you have already felt the real problem. It is not that the market cannot change fast. It is that job posting data changes in ways that look like market movement when it is a pipeline problem.
This is where data validation stops being a technical checklist and becomes a decision safeguard. Without it, you end up debating the output instead of acting on it. With it, you can separate real shifts in hiring demand from noise caused by duplicates, stale listings, inconsistent job parsing, and source churn.
Trend whiplash is usually a data validation failure, not a market change
Most “trend whiplash” comes from a mismatch between what your dashboard promises and what your dataset can support. One week, a source updates its layout and suddenly a field like location gets misread for thousands of records. Another week, a job ID format changes and deduplication starts missing reposts. Your chart still draws a line, but the line is tracking pipeline instability.
A few quick pointers to sanity-check trend whiplash:
- Did a source change format recently?
This is the most common root cause and the easiest to miss. If parsing breaks, counts can drop or spike without any real market movement, especially for fields like location, company name, or employment type.
- Did the definition of “active” jobs shift?
If expiry rules or lifecycle logic change, your “open roles” trend will move even if hiring demand stayed flat. It often shows up as a sudden drop, followed by a slow rebuild, which is a data signature, not a market signature.
- Did taxonomy mapping get updated?
If title normalization or skill extraction improved, it can look like certain skills suddenly grew. That may be a good change, but it needs to be tagged as a definition change so nobody mistakes it for a hiring surge.
Strong data validation catches these issues early at ingestion and standardization. It is basic, but it is also where many vendors cut corners because it is not flashy in a demo.
Duplicate and repost loops inflate demand and distort benchmarks
Duplicate job postings are not a rare edge case. They are a structural reality of online hiring. Roles get syndicated, mirrored, reposted, and re-listed with small edits. Without solid deduplication, one vacancy can be counted multiple times and show up as “new demand” week after week.
Where duplicates usually come from (and why simple rules fail):
- Multi-site syndication and aggregators.
The same job can appear on a company site, two boards, and an aggregator, all with slightly different URLs. If your dedupe logic relies on URL matching, you will overcount by design.
- Reposts that are “technically new” but practically the same.
Recruiters repost the same role weekly or monthly to keep it visible. If you treat every repost as new demand, you inflate hiring signals and distort competitor benchmarks.
- Minor text edits that break naive similarity checks.
Two postings can be identical in intent but differ in wording, location formatting, or title style. Deduplication needs to handle fuzziness without collapsing genuinely different roles into one.
Even academic research flags duplicate postings as a real quality problem for labor market analytics.
JobsPikr’s stance here is simple: if you want accurate job data, deduplication cannot be hidden. It has to be measurable, explainable, and consistent across time.
Ghost jobs and delayed removals create false momentum
This one is quieter but more dangerous for time-series analysis. Job postings do not always disappear cleanly. Some stay live after they are filled. Some vanish and reappear. Some close on one source but stay active on another.
A few patterns that create “ghost demand”:
- Late takedowns.
A posting stays online even after hiring is done, so it keeps getting counted. Your demand trend stays artificially high, then later collapses when the listing finally disappears.
- Reappearance cycles.
Jobs can vanish due to technical issues or moderation, then return. If the pipeline treats that as two different openings, you get phantom spikes.
- Cross-source mismatch.
One source marks a job as closed, another keeps it open. Without lifecycle reconciliation, you end up with conflicting “truths” inside the same dataset.
Good data validation treats freshness as more than scrape frequency. It enforces lifecycle rules so you know what is truly active, what is expired, and what is a repost.
Taxonomy drift breaks month-over-month comparisons
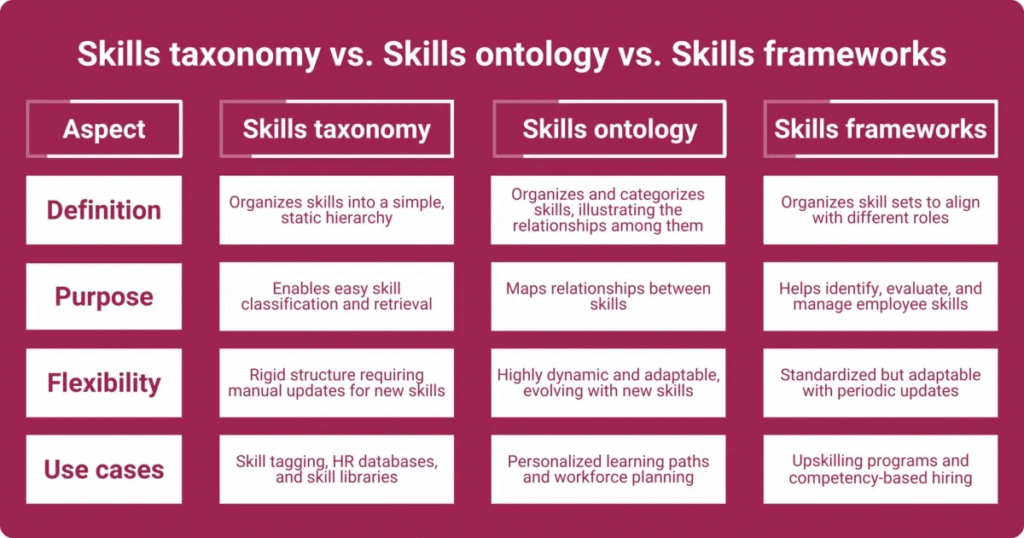
Image Source: workhuman
Taxonomy drift is what happens when the meaning of your categories changes over time. It can be subtle. A normalization update reclassifies titles. A skill extraction improvement captures terms that were previously missed. Your trend line moves, but part of that movement is a definition shift.
Pointers to keep taxonomy drift from wrecking insights:
- Version your mappings.
If a role moved from one category to another, the platform should be able to tell you when and why. Otherwise, leadership sees a change and assumes the market moved.
- Separate “market movement” from “definition movement.
The best practice is to log taxonomy updates and, where relevant, show the expected impact. That way, your month-over-month view stays interpretable, not arguable.
Source churn changes the dataset quietly, then your story changes with it
Sources are not static. Boards change structure. Aggregators change coverage. New sources get added and some become less reliable. If supply changes without coverage transparency, insights can shift even if the market is stable.
What buyers should ask when evaluating vendors on this:
- How do you report coverage changes?
If a major source drops or changes output, you should see it as a coverage event, not discover it through a sudden trend shift. Coverage reporting is part of dataset accuracy.
- How do you score source reliability over time?
A vendor should be able to quarantine low-quality supply before it pollutes your benchmarks. That is the difference between “we collect data” and “we maintain data quality.”
To connect this to outcomes: Gartner has cited research that poor data quality costs organizations at least $12.9 million per year on average. That number lands differently when you realize how easily workforce plans get shaped by unstable job data.
What this means in practice
Workforce intelligence needs a stable base layer. If the base layer is unstable, the dashboard becomes a storytelling tool, not a decision tool.
| What breaks the insight | What it looks like in reports | What data validation must do |
| Duplicate and repost loops | Demand spikes that keep repeating | Detect and suppress duplicates, track repost patterns |
| Ghost jobs and stale roles | Hiring looks strong, then drops suddenly | Enforce lifecycle logic, expiry checks, freshness rules |
| Taxonomy drift | Skill and role trends “change” after updates | Version mappings, log changes, keep trends comparable |
| Parsing and field errors | Location and company trends get weird | Schema checks, plausibility checks, anomaly detection |
| Source churn | Coverage shifts get mistaken as market movement | Coverage reporting, source health scoring, transparency |
What “Dataset Accuracy” Should Mean When You Are Choosing A Talent Intelligence Platform
When a vendor says “high dataset accuracy,” they are usually selling comfort. But you are not buying comfort. You are buying the ability to make decisions without second-guessing the data every time a chart looks surprising.
This is where data validation becomes the real product. If it is strong, the platform behaves like an intelligence layer. If it is weak, you end up with a job data feed that forces your team to keep doing manual sanity checks, and the insights never fully earn trust.
Below are the five things “dataset accuracy” should mean in practice, and what JobsPikr is designed to provide evidence for.
Coverage Evidence Shows What The Dataset Misses, Not Only What It Contains
Coverage is the easiest thing to hide and the hardest thing to fix later. Vendors will often talk about volume, but volume does not tell you whether the dataset is representative for your categories, geographies, or seniority bands.
How to pressure-test coverage properly:
- Ask for coverage by segment, not a global number.
“We cover the US and UK” is not useful unless you see coverage by your priority industries, locations, and role families. JobsPikr buyers should be able to validate coverage where it matters to them, because decision risk sits in the gaps, not in the averages.
- Ask how coverage changes over time.
A dataset can look complete this month and quietly degrade next month if a major source changes or drops. The vendor should have monitoring that flags coverage shifts as an event, not something you only notice after KPIs start behaving weirdly.
- Ask what is excluded and why.
Some postings should be excluded because they are low-quality, duplicated, or malformed. The point is not to collect everything. The point is to keep accurate job data even if that means being strict about what gets filtered out.
Freshness Logic Decides Whether You Are Reading Signals Or History
Freshness is not “how often you scrape.” Freshness is whether the platform can correctly tell what is active right now, what is expired, and what is a repost that should not count as new demand.

Image Source: Decube
What to look for when evaluating freshness:
- Clear rules for “active,” “expired,” and “reposted.”
If those definitions are fuzzy, your time-series insights will always be unstable. Strong data validation makes lifecycle logic explicit so trend lines do not jump around due to stale records.
- Backfill behavior that does not rewrite your past silently.
Vendors often backfill data, which is fine, but you need transparency on when historical numbers were updated and why. Otherwise, your team loses trust because last month’s baseline keeps moving.
- Latency transparency by source.
Not all sources update at the same speed. A reliable platform should be able to explain source-level delays so you do not compare “fresh” with “late” and call it a market shift.
Consistency Checks Prevent Apples-To-Oranges Comparisons Across Sources
Most “market insights” go wrong because the same field means different things across sources. Location formats vary, job types get labeled differently, salary fields are inconsistent, and titles are written in wildly different styles. If a platform does not normalize and validate consistency, segmentation becomes unreliable.
The easiest way to spot this is to ask for a simple comparison: take one role family across two sources and two weeks. If the distribution swings dramatically without a real-world explanation, you are seeing inconsistency, not demand change.
This is exactly why JobsPikr positions itself as a talent intelligence platform. The promise is not just more postings. The promise is stable definitions, enforced through data validation and normalization before insights are generated.
Lineage And Audit Trails Make Insights Defensible To Leadership
If your insights influence planning, hiring strategy, compensation work, or vendor decisions, you need to be able to defend them. That is where lineage matters. Without auditability, you are basically saying “trust us,” and serious buyers should never accept that.
Job Record Lineage And Transformation History
A buyer should be able to trace how a posting moved from raw ingestion to standardized output. That includes what got parsed, what got corrected, what got normalized, and what got excluded. This is the difference between “here is a number” and “here is a number you can stand behind.”
Pipeline Change Logs And Versioned Outputs
Pipelines evolve. Taxonomies improve. Parsers get fixed. That is normal. What is not acceptable is silent changes that rewrite your trends without context. Versioned outputs and change logs let you separate market movement from definition movement, which is core to trustworthy dataset accuracy.
Exception Handling Prevents Edge Cases From Poisoning The Baseline
Every job dataset has edge cases: unrealistic salaries, broken locations, spam postings, and malformed fields. The worst platforms either ignore them or “auto-fix” them in ways that create new errors.
What strong exception handling looks like:
- Outliers are flagged before they influence aggregates.
A handful of extreme salary values can distort medians and percentiles, especially in smaller segments. A reliable platform uses validation and plausibility checks so bad records do not leak into insight-level metrics.
- High-impact segments get stricter validation.
A niche role family with low posting volume cannot afford loose rules, because a small number of errors can move the whole trend line. JobsPikr’s approach should prioritize stricter checks where the decision stakes are higher.
- There is a human review loop for what automation should not guess.
Some records will always need review, especially when ambiguity is high. That is not a weakness. It is part of producing data quality that leaders can trust.
Turn Job Postings Into Decision-Grade Workforce Intelligence
See how JobsPikr applies data validation, normalization, and bias removal so your benchmarks stay stable and defensible.
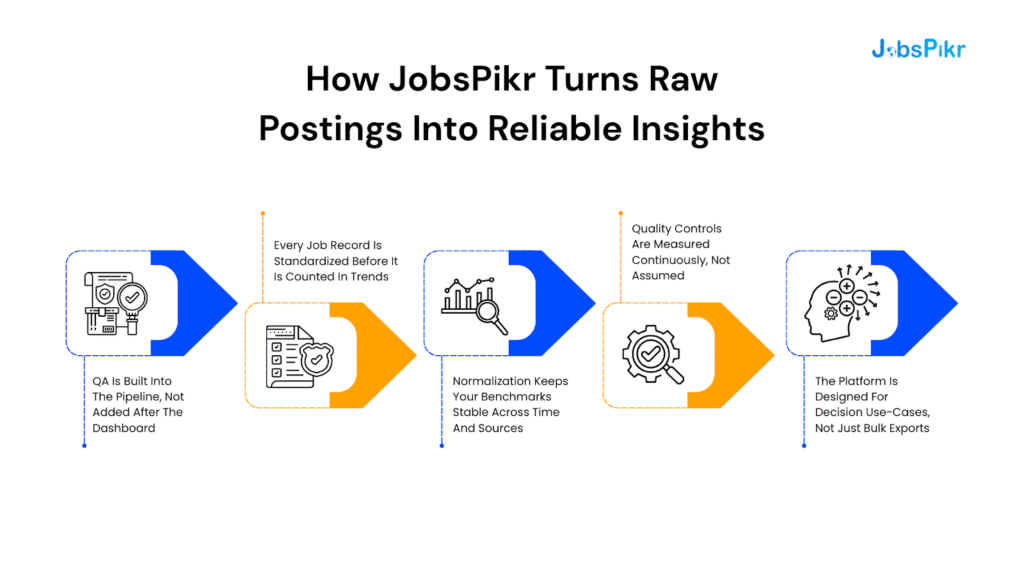
How JobsPikr Turns Raw Postings Into Reliable Insights, Not Just “More Job Data”
When you are evaluating vendors, most of them sound the same on the surface. Everyone has “millions of jobs.” Everyone claims coverage. Everyone shows a dashboard.
The difference shows up when you ask one uncomfortable question: can you trust the insight enough to act on it without doing your own cleanup first?
This is the gap JobsPikr is built to close. The platform is positioned as a talent intelligence layer that sits between messy job postings and decision-grade outputs. That means data validation, normalization, and quality controls are not “nice-to-haves.” They are the product.
QA Is Built Into The Pipeline, Not Added After The Dashboard
A dashboard cannot fix a broken dataset. It can only visualize it. So the core design choice is where quality gets enforced.
Here is what “built-in QA” looks like in practice:
- Validation happens before aggregation.
If a record is malformed, incomplete, or fails plausibility checks, it should not be allowed to influence trends. Otherwise, you are cleaning after the damage is done.
- Quality checks are continuous, not a one-time cleanup.
Job data changes daily. Sources change formats, new duplicates appear, and categories drift. Built-in data validation is about detecting drift as it happens, not doing a monthly patch job.
- The platform surfaces issues instead of hiding them.
The goal is not to pretend data is perfect. It is to make the dataset health visible so analysts and decision-makers know what they are looking at.
Every Job Record Is Standardized Before It Is Counted In Trends
This is where a “job data provider” and an “insights platform” usually diverge.
A provider often delivers raw or lightly cleaned records and expects your team to normalize. JobsPikr’s intended value is that the standardization happens upstream, so you can benchmark roles, skills, and locations without constantly worrying about mismatched labels.
To keep this readable, here are the big standardization moves that matter most for dataset accuracy:
- Titles and seniority get mapped into consistent buckets.
This stops title inflation from creating fake “senior demand.” It also reduces role fragmentation where the same job appears under five different names.
- Companies and locations are resolved into stable entities.
Without this, you end up with “one employer, many spellings,” and “one city, many formats.” That breaks competitor benchmarking and geographic trends fast.
- Skills are extracted and normalized so you are not tracking keyword soup.
The difference between “mentions Python” and “requires Python” matters. A platform focused on accurate job data needs to preserve that intent, not just count words.
Normalization Keeps Your Benchmarks Stable Across Time And Sources
This is the part most teams do not appreciate until they are burned by it.
If your sources label things differently, then your analysis becomes a translation problem. One source uses “Hybrid,” another uses “Remote with travel,” another hides it in the description. If you do not normalize consistently, the trend line you present to leadership is not the market. It is the mix of your sources.
JobsPikr’s approach is designed to make benchmarks comparable by keeping definitions stable. When definitions do change because the taxonomy improves, those changes should be trackable, so you can separate real movement from reclassification.
A clean way to see why this matters is the “same metric, different meaning” problem:
- If “active jobs” includes stale listings, demand looks inflated.
- If “skills demand” counts casual mentions, skills look noisier than reality.
- If “company hiring” is not entity-resolved, you overcount and mis-rank competitors.
Normalization is what keeps those metrics meaningful.
Quality Controls Are Measured Continuously, Not Assumed
Most vendors say “we clean data.” Very few show what “clean” means.
When JobsPikr is evaluated as a talent intelligence platform, buyers should expect quality to be measurable. Not in abstract promises, but in metrics that answer practical questions like: how duplicate-heavy is this segment, how fresh is the dataset this week, and what changed since last month?
Here are examples of quality controls that matter because they directly protect decision-making:
- Duplicate rate visibility
If duplicates and repost loops are not measured, you cannot trust demand signals. Deduplication is not a feature, it is a guardrail.
- Freshness and lifecycle checks
If the platform cannot reliably separate active, expired, and reposted roles, your time-series insights will always be arguable.
- Schema completeness and plausibility checks
These stop broken fields, unrealistic salaries, and malformed locations from quietly skewing aggregates, especially in smaller segments.
This is what “data quality” looks like when it is treated as an ongoing operational system, not a one-time cleaning step.
The Platform Is Designed For Decision Use-Cases, Not Bulk Exports
A surprising number of teams buy job data and then spend months trying to make it usable for decisions. That is expensive, slow, and easy to get wrong.
JobsPikr’s positioning is that you should not have to rebuild the validation layer internally. You should be able to use the platform to answer decision questions directly, like:
- Which skills are actually rising in demand in a region, without duplicates inflating the story?
- Which competitors are increasing hiring velocity, without repost loops making them look bigger than they are?
- Which roles are shifting in seniority mix, without title inflation corrupting the signal?
That is the difference between “we provide job data” and “we provide workforce intelligence.”
Job Data Provider Vs Talent Intelligence Platform
| What You Need As A Buyer | Typical Job Data Provider | JobsPikr’s Intended Intelligence Layer |
| Stable trends you can defend | Raw volume, limited validation | Data validation before insights |
| Benchmarks across sources | Inconsistent fields and definitions | Normalization and harmonization |
| True demand signals | Duplicates and reposts leak in | Deduplication and lifecycle logic |
| Confidence in segmentation | Fragmented titles and locations | Entity resolution and mapping |
| Trust over time | Silent pipeline changes | Quality monitoring and transparency |
The Biggest Reason Accurate Job Data Fails Is Duplication And Identity Confusion, And How JobsPikr Fixes It
If you want one “boring” reason job market insights go sideways, it is this: the same real-world job gets counted multiple times, and the same real-world employer gets split into multiple identities.
That combination breaks everything you care about in an evaluation. Benchmarking becomes shaky. Hiring velocity gets inflated. “Top hiring companies” lists become noisy. And the worst part is you often do not notice it until a decision meeting turns into a data argument.
JobsPikr treats this as a first-class data validation problem because duplication and identity resolution are not edge cases in job data. They are the default reality.
Deduplication That Goes Beyond URL Matching And Obvious Repeats
Most vendors start with simple rules because they are easy to implement and easy to explain. But job data does not behave nicely. The same role gets syndicated to multiple boards, re-posted with small edits, and mirrored by aggregators with new URLs.
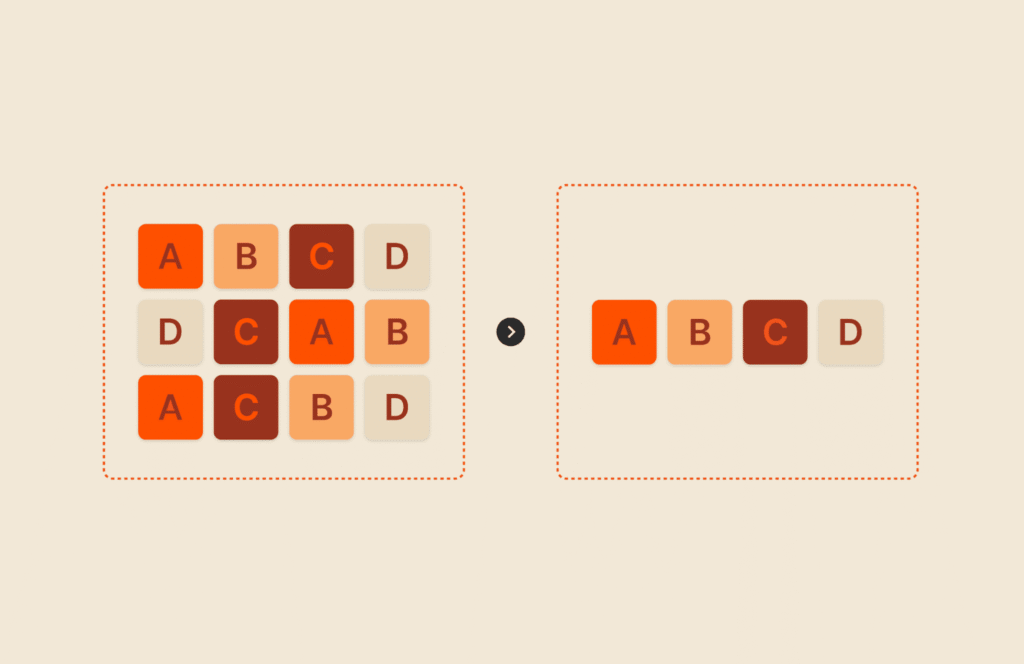
What “real” deduplication needs to handle:
- Same job, different URLs, different sources.
A role posted on a company careers page often shows up on multiple boards with different identifiers. If deduplication relies heavily on URLs or job IDs, you are guaranteed to overcount.
- Same job, slightly edited text.
Recruiters tweak titles, reorder bullet points, or change the first paragraph. If deduplication only catches exact matches, repost loops sneak through and inflate demand signals.
- Same job, multi-location or ambiguous location formatting.
Some roles are listed as “Bangalore or Remote,” others as “India,” others as a specific neighborhood. Weak location normalization makes duplicates look like distinct postings.
This is why dataset accuracy cannot be separated from how deduplication is handled. If dedupe fails, every downstream insight becomes fragile.
Job Lifecycle Tracking To Stop Reposts From Looking Like New Demand
Even when a job is legitimately re-posted, the analytics question is usually not “is this a new job object?” It is “is the company still hiring for the same role, and for how long?”
That is where lifecycle tracking matters. You want the dataset to understand posting continuity and expiry so you can tell the difference between:
- a genuinely new opening,
- a repost meant to refresh visibility,
- and a stale posting that never got taken down.
What makes lifecycle tracking decision-useful:
- You need an “active” definition that is stable.
If “active” includes stale records, demand looks inflated. If it excludes too aggressively, you undercount and miss early signals. Lifecycle logic is the control that keeps this consistent.
- You need a view of “time open,” not just “posted date.”
For workforce intelligence, duration often matters more than timestamps. Roles staying open unusually long can indicate talent scarcity, compensation mismatch, or unrealistic requirements.
Lifecycle controls are part of data quality because they prevent a reporting illusion where the same demand is repeatedly counted as “new.”
Company Entity Resolution To Prevent “One Employer, Many Names” Errors
Identity confusion is a silent benchmark killer. The same employer can show up as:
- “Amazon”
- “Amazon.com”
- “Amazon India”
- “Amazon Development Centre”
- a staffing partner name that masks the real employer
If these are not resolved, company-level insights become unreliable. You end up with fragmented counts that understate true hiring volume, or worse, you overcount by treating subsidiaries, divisions, and staffing wrappers as separate employers when the decision needs a consolidated view.
Here’s how you can pressure-test company identity resolution:
- Do subsidiaries roll up cleanly when you want them to?
Benchmarking often needs both views: parent-level and entity-level. A platform should support both without forcing you into manual cleanup.
- Can the platform separate staffing firms from end employers when possible?
Staffing-heavy markets can distort “top hiring companies” lists if identity logic is weak. If your goal is competitive intelligence, the end employer matters.
Company entity resolution is not just “nice hygiene.” It is what makes company benchmarking believable.
Source Reliability Scoring To Contain Low-Quality Supply
Not all sources are equal. Some are noisy aggregators. Some are spammy. Some have broken fields frequently. If you treat all sources equally, your dataset gets polluted and you spend your time arguing about whether a spike is real.
JobsPikr’s intelligence positioning requires the platform to behave like a curator, not a vacuum cleaner. That means sources should be monitored and scored, and low-quality supply should be contained before it impacts trends.
Why this matters:
- One bad source can warp an entire segment.
If a source suddenly floods your dataset with duplicates or malformed records, a role family can look like it exploded. Reliability scoring is the guardrail that stops that from turning into “insight.”
- Source health changes over time.
A source can be clean for months, then break due to a structural change. Continuous monitoring is part of data validation, not a one-time onboarding step.
Duplicate Handling That Is Visible As A Metric, Not Hidden As A Guess
Here is the buyer’s reality: if a vendor cannot show you what it is doing about duplicates, you cannot trust the output. Full stop. Dedupe should show up as a measurable dataset health, not as “trust our proprietary process.”
That is why the most confidence-building thing a platform can do is make duplicate handling observable. Not with jargon, but with straightforward reporting, you can sanity-check.
Duplicate-Rate Reporting By Source, Category, And Geography
If duplicate rates are not visible by segment, you do not know where the dataset is strong or weak. Segment-level reporting tells you where benchmarks are stable and where you should interpret trends with caution.
Rules And Thresholds That Can Be Reviewed And Tuned
You do not need the full algorithm. But you do need clarity on what signals define a duplicate, what thresholds are used, and how the platform avoids collapsing truly distinct roles into one. This is especially important in high-volume roles where small mistakes scale fast.
What This Fixes For A Buyer:
| Buyer Question | What Goes Wrong Without Strong Controls | What JobsPikr’s Approach Enables |
| “Who is hiring the most?” | One employer is split into many identities | Clean company rollups and stable rankings |
| “Is demand really rising?” | Reposts and duplicates inflate counts | Trends that reflect real change, not repost noise |
| “Where are hotspots?” | Location noise creates false clusters | Comparable geo insights and reliable rollups |
| “How long do roles stay open?” | Stale jobs and lifecycle gaps distort duration | Posting lifecycle insights you can act on |
Turn Job Postings Into Decision-Grade Workforce Intelligence
See how JobsPikr applies data validation, normalization, and bias removal so your benchmarks stay stable and defensible.
Why Your Skill And Role Trends Go Wrong Without Normalization, And What JobsPikr Standardizes
Most teams think their “skills insights” problem is an analytics problem. It is usually a labeling problem.
If the same role can show up under ten titles, if skills are counted as raw keyword mentions, and if seniority is guessed from vague phrases, your trend line becomes a mix of real demand and messy language. That is how you end up with confident charts that do not hold up in a leadership review.
JobsPikr treats normalization as a core part of data validation because it is the only way to keep dataset accuracy stable when you compare across time, geographies, and sources.
Job Title Normalization Prevents Title Inflation From Skewing Demand
Titles are not consistent across companies or even within the same company. One team says “Software Engineer,” another says “Backend Developer,” and a third says “Platform Engineer,” even when the work is similar. On top of that, titles get inflated. “Lead” becomes “Senior.” “Associate” becomes “Manager.” Suddenly you think senior hiring is rising, when it is mostly wording.
How to spot title-based noise early:
- If your role family count is growing but your company mix did not change, suspect title variance.
Title variance often shows up as fragmentation, where demand is real but scattered across labels. Normalization brings those labels into a stable role taxonomy so the trend reflects hiring, not naming style.
- If senior demand spikes without a matching shift in experience requirements, suspect title inflation.
Vendors that do not normalize titles will over-report seniority movement, especially in tech and consulting-heavy datasets. JobsPikr’s goal is to standardize titles so seniority insights are driven by requirements, not marketing language.
Skill Extraction That Separates Real Requirements From Casual Mentions
Skills are messy because job descriptions are messy. Many postings include “nice to have” tools, team preferences, or random ecosystem mentions that are not requirements. If you count every mention equally, your “top skills” view becomes inflated and noisy.
This is where normalization is not just dictionary mapping. It is about preserving meaning so the skill signal stays usable for decisions like workforce planning, learning programs, and vendor benchmarking.
Separating Skill Mentions From Requirements And Responsibilities
A reliable skills model needs to distinguish between a skill that is required and a skill that is referenced. If the dataset does not separate those, the skill demand curve becomes hard to trust, and you end up over-investing in training for skills that are not actually gating hiring.
De-Duping Skills And Standardizing Variants
“ReactJS” vs “React,” “PostgreSQL” vs “Postgres,” “GenAI” vs “Generative AI.” Without standardization, you undercount true demand because the same skill is split across variants. JobsPikr’s normalization layer is meant to collapse variants into a consistent representation so skills trends reflect the market, not spelling.
Seniority Mapping To Stop Junior Roles From Masquerading As Mid-Level
Seniority is one of the easiest dimensions to get wrong because job postings rarely use clean labels. Some titles encode seniority. Some descriptions encode it through years of experience. Some hide it in responsibility scope.
If seniority is not mapped consistently, you get bad segmentation. And once seniority segmentation is wrong, any skill trend or compensation proxy analysis built on it becomes fragile.
What usually reveals seniority mapping issues:
- If “mid-level” roles include a lot of 0–2 year requirements, your mapping is leaking.
This is a common vendor failure because title-only heuristics are not enough. A platform focused on accurate job data needs to combine signals and validate plausibility.
- If seniority distribution changes sharply after a taxonomy update, it needs to be logged.
Sometimes mapping improves and that is good. But it must be visible, otherwise stakeholders assume the market moved when the definition moved.
Location Normalization To Avoid Fake Hotspots And Messy Geo Rollups
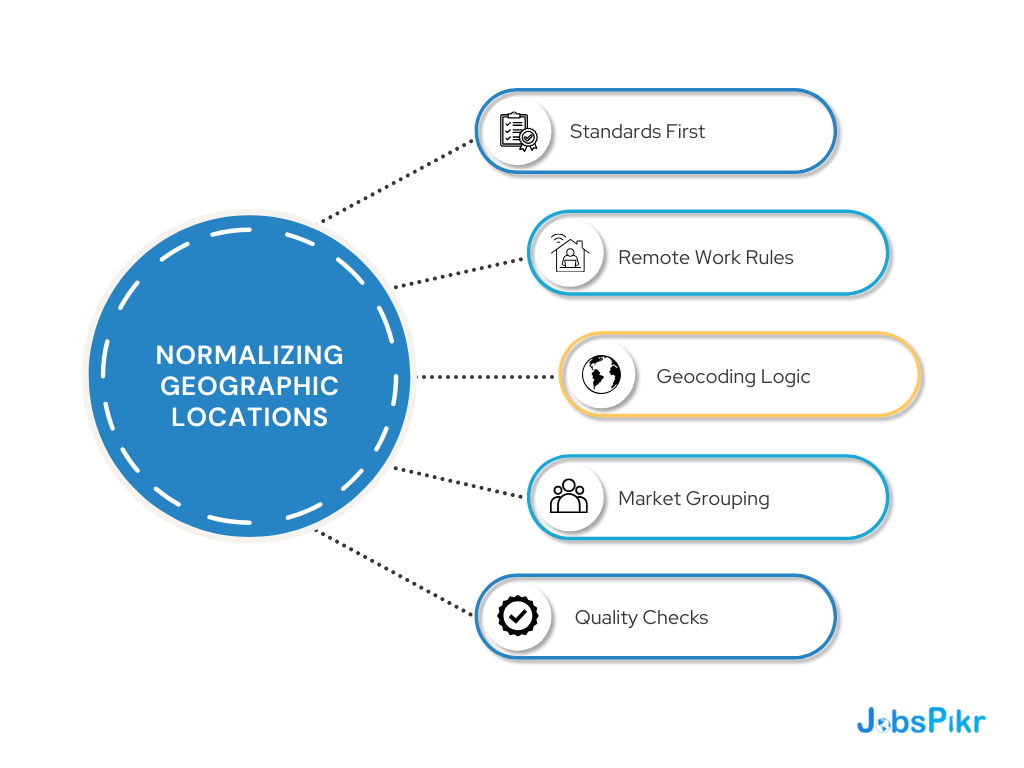
Location is deceptively hard. Some postings list a city. Some list a region. Some list multiple locations. Some say “Remote” but include an office city anyway. If the platform cannot normalize this, your heatmaps become storytelling, not analysis.
JobsPikr’s normalization focus here is about keeping geographic comparisons stable. That means consistent city and country mapping, consistent handling of hybrid and remote cases, and a reliable way to roll up from city to metro to state to country without double counting.
Industry And Function Mapping To Keep Benchmarks Comparable
Industry categories and job functions are another source of drift. The same company can be categorized differently across sources. The same role can be assigned different functions based on title keywords. Without normalization, your “industry hiring trends” are often a mix of real movement and inconsistent labeling.
A talent intelligence platform needs consistent mapping so you can benchmark, for example, tech hiring in the UK versus the US, without accidentally comparing different definitions of “tech” across sources.
Cross-Source Harmonization So “The Same Metric” Stays The Same Metric
This is the part that decides whether your analysis is portable across sources.
When two sources represent the same field differently, the metric is not truly the same. One source may treat contract roles as full-time. Another may hide employment type in the description. Another may omit salary entirely. Harmonization is the work of creating a common language across sources so you can compare without hidden mismatches.
Standard Taxonomies For Roles, Skills, Industries, And Seniority
Stable taxonomies are how a platform protects dataset accuracy over time. You cannot trend reliably if the meaning of categories changes every month or differs by source. JobsPikr’s intent is to standardize these taxonomies before insights are computed.
Mapping Logic For Synonyms, Variants, And Regional Naming Differences
Regional differences matter more than most vendors admit. The same role can be phrased differently in the US versus the UK. Skills can be referenced with different shorthand. Location formatting differs by region. Harmonization needs to account for this, otherwise cross-geo comparisons become noisy.
Bias Removal That Leaders Can Trust, Without Flattening The Market Signal
Most buyers only start asking about bias removal after something goes wrong. A leadership team questions why a role “looks hot” in one region but not another. A DEI leader flags that your benchmarks seem to mirror the same historical skews you are trying to fix. Or an analytics team worries they are about to bake ai bias into downstream models because the input dataset is uneven.
Here is the uncomfortable truth: bias can enter job posting datasets even when nobody is trying to be biased. It comes from how postings are written, where you source them from, and what gets overrepresented by default. That is why JobsPikr treats bias control as part of trust and data quality, not as an optional add-on.

Image Source: Talentlyft
Where Bias Enters Job Datasets Through Language, Coverage Gaps, And Proxies
Bias does not need an explicit sensitive field to show up. Job data can carry bias through patterns that look innocent on the surface.
- Language patterns can skew who a role “sounds like” it is for.
Some job descriptions use coded language, aggressive tone, or gendered phrasing that correlates with different applicant behavior and employer intent. If your platform turns those patterns into features without care, your insights start reflecting writing style more than true demand.
- Coverage gaps are bias, even if the dataset is large.
If your sources over-index on certain industries, cities, or company types, your “market view” becomes a partial view that you might mistake as reality. This is why vendor evaluation must include coverage evidence by segment, not just total volume.
- Proxy variables are the silent driver of ai bias risk.
Even if you never store protected attributes, proxies can leak them. Think of location granularity, school signals, employment gaps, or certain phrasing patterns that correlate strongly with protected groups. Controlling proxy leakage is one of the practical ways to reduce AI bias risk without pretending the world is perfectly clean.
Why Bias In Hiring Gets Amplified When Biased Inputs Become Benchmarks
Teams rarely use job data in isolation. They use it as a reference layer. That is where “small bias” becomes “big impact.”
- Benchmarks influence policy decisions, not just dashboards.
If your job dataset overrepresents certain employers or regions, your “market median” and “top skills” lists can push workforce plans in the wrong direction. Once that happens, it is hard to unwind, because the decisions look data-backed.
- Hiring workflows increasingly involve automated screening and recommendations.
Even when the final decision is human, the shortlisting and prioritization steps can inherit bias from inputs. The EEOC has explicitly warned that employers’ use of AI and automated systems in employment decisions can raise discrimination concerns.
- Bias becomes harder to spot after aggregation.
The moment you roll up by role, region, or company, the dataset can look “balanced” while still carrying structural skews underneath. That is why bias controls need to exist before the insight layer, not as a disclaimer after.
Managing AI Bias Risk By Limiting Proxy Leakage And Skewed Representation
This is where a lot of platforms get performative. They either claim “bias-free data,” which is not realistic, or they over-sanitize and destroy the useful signal.
- Limit proxy leakage by design, not by promises.
A strong approach is to identify high-risk proxies and either constrain how they are used in insight generation or flag them for careful interpretation. The goal is not to pretend proxies do not exist, it is to prevent them from quietly driving decisions.
- Correct representation skews without rewriting the market.
If one segment is heavily overrepresented because of sourcing patterns, you do not want your outputs to simply echo that skew. The right move is to control for overrepresentation so your trends reflect the market more than the data supply.
- Make bias controls visible to buyers.
Decision-makers should not have to trust a black box. A vendor that takes trust seriously should be able to explain what bias risks exist in job data, what controls are applied, and what limitations remain.
Bias Removal Methods That Preserve Signal Rather Than Sanitize It
The real challenge is doing bias removal without flattening insights into something bland and useless. Buyers do not want a dataset that hides reality. They want a dataset that does not exaggerate distortions.
What Gets Adjusted To Correct Skew
Adjustments should be used when the skew is clearly from data supply, not from the market. For example, if a source mix change suddenly overrepresents a specific role family, a platform can correct the reporting so the trend does not jump for the wrong reason. The important part is that adjustments must be documented, otherwise you create a new trust problem.
What Gets Flagged As High-Risk For Interpretation
Some patterns should not be “fixed” silently. They should be flagged. If a trend is driven by a small number of sources, or if a segment has thin coverage, the output should carry that context so teams do not over-read it. This is how you keep leaders confident without overselling certainty.
Documentation That Lets Buyers Audit Choices Instead Of Trusting Black Boxes
If you are benchmarking vendors, this is one of the simplest ways to separate an insights platform from a data vendor: ask what they can prove.
- Bias controls should be explainable in plain language.
You do not need the full algorithm. But you do need a clear description of where bias can enter, what the system does about it, and where humans should be cautious.
- You should be able to trace how an insight was produced.
If a “top skills in London” insight is influenced by a change in sources or taxonomy, that should be visible. This is where data validation, lineage, and bias controls overlap. Trust comes from being able to explain the output end-to-end.
- Compliance risk is not hypothetical anymore.
The EEOC’s materials make it clear that automated tools used in employment contexts can raise discrimination issues, and employers remain responsible for outcomes even when tools are provided by vendors.
Turn Job Postings Into Decision-Grade Workforce Intelligence
See how JobsPikr applies data validation, normalization, and bias removal so your benchmarks stay stable and defensible.
What Data Quality Looks Like In Production, And What JobsPikr Monitors Continuously
Most vendors talk about quality like it is a one-time cleanup. In reality, data quality is a production system. Sources change, formats break, duplicates creep back in, and taxonomies drift. If the monitoring is weak, your dataset accuracy slowly degrades, and you only notice when insights start looking “off.”
JobsPikr’s reliability story is strongest when it is framed like this: data validation is not a project, it is ongoing control.

Freshness And Expiry Controls That Stop Stale Records From Polluting Trends
Freshness is not just crawl frequency. It is whether “active” actually means active. JobsPikr’s quality layer needs expiry logic and lifecycle checks so old postings do not sit inside current demand counts and create fake momentum.
Quick pointer: if a vendor cannot explain how they handle reposts vs genuinely new roles, you will never fully trust hiring velocity insights.
Schema Validation And Field Completeness Checks That Prevent Broken Joins
A lot of breakage is boring. Missing fields, shifted HTML, malformed locations, broken salary formats. Without strict data validation, these records slip through and then destroy segmentation accuracy later.
Quick pointer: schema checks matter most on the fields you slice by: company, location, title, seniority, skills, and posting date.
Outlier And Plausibility Checks For Salary, Experience, And Location
Outliers are not “rare.” They are constant in job data. One unrealistic salary can distort percentiles for a niche role family. One bad location parse can create a fake hotspot. Plausibility checks keep these from leaking into insight-level metrics and protect accurate job data in smaller segments.
Drift Monitoring So Taxonomy Changes Do Not Silently Change Results
Taxonomies will evolve. Parsers will improve. That is fine. What breaks trust is silent drift that changes your trendlines without telling you why. Drift monitoring and change logs make insights defensible, because you can separate market movement from definition movement.
Human Review Loops For The Edge Cases, Automation Should Not Guess
Some records should not be auto-fixed. Ambiguous company identity, multi-location roles, and noisy descriptions often need review, especially in high-impact segments. A controlled human loop is part of maintaining data quality, not a sign the system is weak.
JobsPikr, The Intelligence Layer That Makes Job Data Usable for Decisions
Raw postings are cheap. Trust is not. The difference between a job data provider and a workforce intelligence platform is whether you can rely on the output without rebuilding the pipeline yourself. JobsPikr’s value is that data validation and normalization are enforced before insights are produced, so dataset accuracy and data quality stay stable across sources and over time. That is what makes accurate job data usable for benchmarking, planning, and leadership decisions, with bias removal handled as part of reliability, not as an afterthought.
Turn Job Postings Into Decision-Grade Workforce Intelligence
See how JobsPikr applies data validation, normalization, and bias removal so your benchmarks stay stable and defensible.
FAQs:
1) What Is Data Validation In Job Posting Data, And Why Does It Matter?
Data validation is the set of checks that makes job postings usable for analysis, not just collectible. It catches issues like duplicates, broken fields, stale listings, and inconsistent labels before they distort trends. Without it, you can get confident-looking insights that are driven by pipeline noise, not hiring demand.
2) How Does JobsPikr Improve Dataset Accuracy Compared To Raw Job Data Providers?
JobsPikr focuses on dataset accuracy by standardizing records before reporting trends. That includes deduplication, posting lifecycle rules, and normalization across titles, skills, companies, and locations. The outcome is more stable benchmarking and fewer “why did this change?” moments in reviews.
3) What Does Bias Removal Mean In Job Data, And Does It Affect Accuracy?
Bias removal means reducing skew caused by uneven coverage and proxy signals that can distort insights or reinforce bias in hiring. Done correctly, it improves trust without flattening real market differences. The key is documentation so teams know what was adjusted, flagged, or interpreted cautiously.
4) How Can I Tell If A Vendor’s Accurate Job Data Claims Are Real?
Ask for evidence, not volume. You want duplicate-rate visibility, freshness logic for active vs expired roles, coverage by your priority segments, and lineage or change logs that explain what changed and when. If they cannot show these, the “accurate job data” claim is mostly branding.
5) Does This Help With Ai Bias Risk If We Use Insights In Models Or Automation?
Yes, because ai bias often starts with biased or skewed inputs. Strong data validation and bias controls reduce proxy leakage and representation issues before insights become features or benchmarks. It does not guarantee “bias-free,” but it lowers risk and makes outputs more defensible.




