
- Data Engineer Demand Is Shifting: A 2026 Snapshot
- The State of Data Engineer Demand in 2023–2025
- Regional Talent Trends: Where Data Engineer Demand Is Concentrated
- Power Your Platform with Live Workforce Intelligence
- Demand vs Workforce Availability: The Structural Mismatch
- The Shift in Data Engineer Skills: AI & ML Are Redefining the Role
- Build Your 2026 Location Strategy on Real Market Data
- The Rise of Secondary Talent Hubs in 2026
- From Recruitment to Location Intelligence: Deciding Where to Hire
- Build Your 2026 Location Strategy on Real Market Data
- Strategic Implications for Engineering & Workforce Leaders in 2026
- Data Engineer Demand Is Now a Location Strategy Decision
- Build Your 2026 Location Strategy on Real Market Data
- FAQs
Data Engineer Demand Is Shifting: A 2026 Snapshot
Data engineer demand is climbing, but the hiring risk in 2026 is mostly geographic. If you keep defaulting to the same “safe” talent hubs, you are competing in the most crowded markets and calling it a strategy.
Two things are happening at once. First, demand is staying strong because companies are still rebuilding their data stacks for AI. Second, the skill mix inside “data engineer” is changing. The World Economic Forum’s Future of Jobs Report 2025 lists AI and big data as the fastest-growing skill area, which is exactly why data engineering is being pulled closer to ML pipelines, real-time systems, and governance work that supports AI at scale.
Key takeaways
- Data engineer demand is rising, but workforce availability is uneven across regions, so “hire where everyone hires” becomes a self-made constraint.
- The role is shifting toward AI-adjacent data engineering, which changes what “good supply” even means in each region.
- Location strategy now needs talent intelligence, not assumptions and old hub playbooks.
- External labor signals still point to strong growth in data-centric roles overall, reinforcing why this pressure isn’t temporary.
The State of Data Engineer Demand in 2023–2025
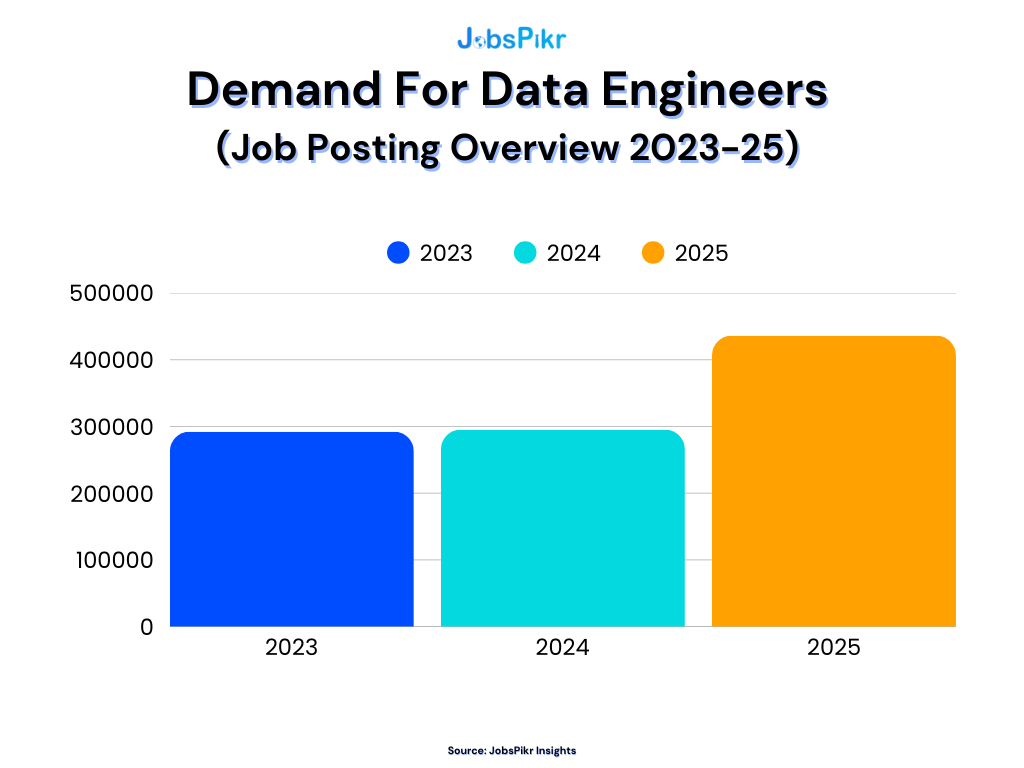
If you look at the last three years, the story is pretty consistent: data engineer demand kept rising, and it did not rise evenly.
In the JobsPikr dataset behind the first infographic, the upward curve from 2023 to 2025 is not subtle. What’s changed is the shape of the demand. Early on, many companies were still hiring data engineers to “catch up” on foundational work, like stabilizing pipelines, cleaning up warehouses, and migrating to cloud. By 2024 and into 2025, the hiring language starts to feel different. You still see the usual stack requirements, but you also see a stronger pull toward “AI-ready” infrastructure, real-time data movement, and governance that can survive scrutiny.
That’s why the “data engineer demand” is sticking even when hiring slows in other pockets of tech. It’s not a nice-to-have function anymore. When leadership teams decide they want AI outcomes, they quickly run into a boring truth: models do not compensate for messy, missing, or slow data.
External labor signals support this direction, too. In the U.S., the Bureau of Labor Statistics projects data scientist employment growth of 34 percent from 2024 to 2034, which is a useful proxy for how strongly the broader data and analytics labor market is expected to expand. When the downstream roles grow, the upstream pipeline roles tend to stay hot.
There’s also a skills signal that matters for workforce planners. The World Economic Forum’s Future of Jobs Report 2025 puts AI and big data at the top of the fastest-growing skills list globally. That does not mean every data engineer becomes an ML engineer, but it does mean the “modern” expectation for the role is shifting toward infrastructure that can support AI use cases reliably.
One more layer here: AI-ready data has become a mainstream enterprise priority, not just an engineering preference. Gartner’s 2025 AI Hype Cycle commentary highlights “AI-ready data” as one of the fastest advancing areas, which matches what most workforce teams are seeing in job requirements.
So the takeaway from 2023–2025 is not just that data engineer demand increased. It’s that the role is moving closer to AI readiness, and that shift is already affecting where demand concentrates and what “qualified supply” looks like in each region.
Regional Talent Trends: Where Data Engineer Demand Is Concentrated
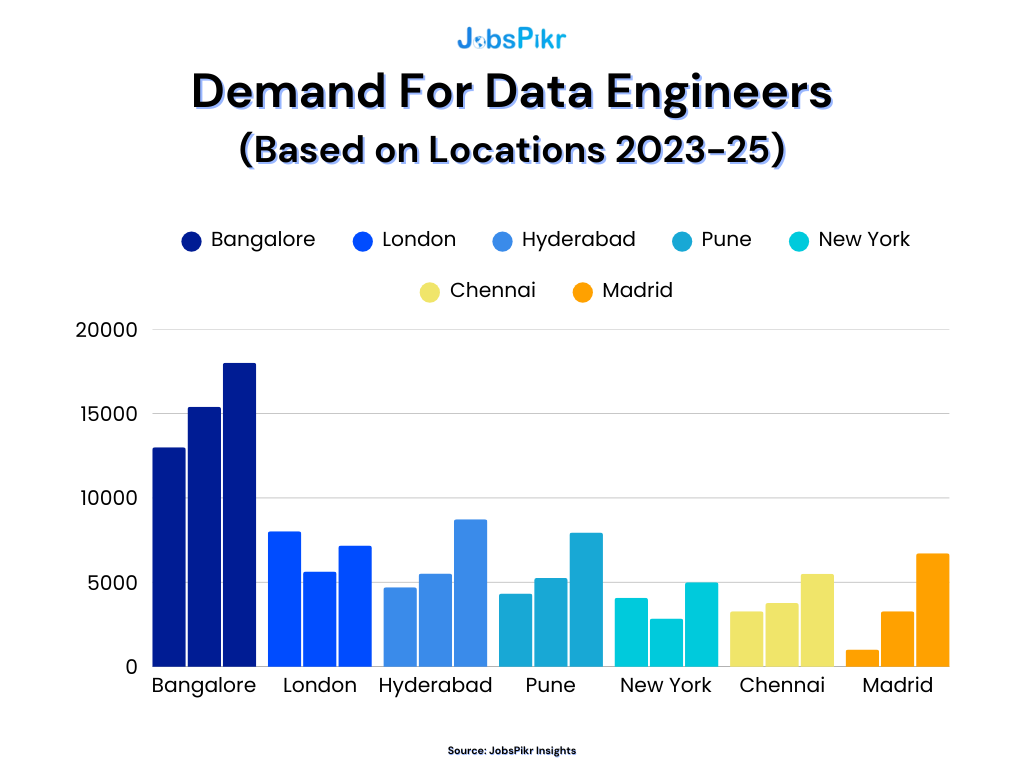
The second infographic tells a story most workforce teams feel intuitively but rarely quantify. Data engineer demand is not evenly distributed. It clusters hard.
Bangalore continues to lead by a wide margin in the JobsPikr dataset. London and Hyderabad remain strong. Pune shows consistent growth. New York holds steady. Chennai and Madrid are smaller in absolute numbers, but their trajectory matters more than their size.
This is where regional talent trends become strategic.
2.1 Competition tightens in concentrated markets
When demand piles into a few cities, competition becomes structural, not seasonal. You are not competing with one or two companies in your category. You are competing with every team building data products, AI pipelines, and analytics foundations at the same time.
In practice, that means the same candidate is often running parallel processes. Even strong employer brands feel the pressure because the market is crowded, not because the company is weak.
2.2 Time-to-fill stretches, even when supply looks “large.”
A city can have a big talent pool and still feel slow. High demand density changes the tempo. Shortlists take longer. Interview scheduling becomes messy. Offer cycles stretch. Counteroffers become normal.
This is usually the point where hiring teams blame the process. But the root cause is often workforce availability relative to demand, not recruiter efficiency.
2.3 Skill relevance matters more than raw headcount
This is the part many teams miss. A region may show plenty of data engineers on paper, but how many match what companies need right now?
Between 2023 and 2025, the role shifted toward cloud-native data stacks, streaming systems, and AI-adjacent pipelines. So the question is not “how many data engineers exist here,” but “how many can support the next two years of infrastructure work.”
What’s interesting in the JobsPikr data is not just that Bangalore leads. It’s that secondary hubs like Hyderabad and Pune are holding strong momentum, which suggests hiring is spreading out. In Europe, London remains dominant, but Madrid’s growth pattern is worth watching. Smaller markets can become meaningful when enterprise demand and AI investment start to compound.
This is where global hiring trends meet location strategy. Remote work widened access, but it did not erase regional gravity. Ecosystems still form around universities, capital, and enterprise clusters. Demand builds its own momentum.
Power Your Platform with Live Workforce Intelligence
Access structured, normalized labor market data and turn external hiring signals into product-ready insights.
Demand vs Workforce Availability: The Structural Mismatch
Most teams talk about hiring like it’s a pipeline problem. More sourcing, faster interviews, better employer brand. But when data engineer demand rises faster than the local talent pool can absorb, the bottleneck is structural. You can run the process perfectly and still lose.
3.1 High demand does not automatically mean usable supply
A region can show a big volume of postings and still be short on the kind of data engineers companies actually need right now.
The reason is simple. In 2026, “data engineer” can mean anything from warehouse maintenance to building real-time pipelines for AI products. When demand shifts toward more complex work, the effective talent pool shrinks. On paper the market looks large. In practice, workforce availability is thin.
3.2 Demand and supply can be “balanced” on headcount but broken on skills
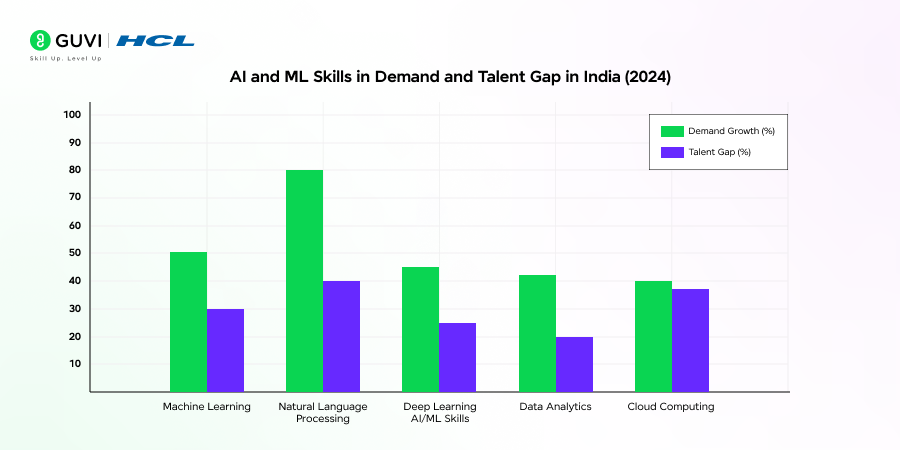
Image Source: Guvi
This is the mismatch most planners miss.
Even if supply and demand look close in total numbers, the market can still be dysfunctional if the skills are skewed. A region might have plenty of ETL-heavy experience, but not enough people who have shipped streaming systems, handled large-scale orchestration, or built data layers designed for ML workflows.
This is why regional talent trends need to be read as “capability distribution,” not just hiring volume.
3.3 Concentration triggers salary inflation, but the deeper cost is execution drag
Salary inflation is the obvious part. Every hiring manager sees it.
The hidden cost is slower execution. Teams end up with longer hiring cycles, more open roles sitting unfilled, and projects that slip by quarters. Sometimes you get the hires, but not fast enough to hit the roadmap. Sometimes you get them quickly, but you compromise on quality and pay for it later in reliability issues.
That is why concentrating all hiring in one saturated hub is not just expensive. It’s risky.
3.4 Hiring teams “solve” the mismatch in ways that quietly damage outcomes
When workforce availability tightens, companies usually respond in predictable ways. None of them is great.
They either lower the bar without admitting it, stretch senior engineers across too many projects, or overpay for talent that isn’t a true match. In the short term, this helps close roles. Over time, it increases operational load and raises the chance of data incidents, pipeline fragility, and churn in the team.
This is also why data engineer demand can look satisfied in dashboards while the data platform still feels unstable.
3.5 Workforce availability is a forecasting problem, not a recruiting problem
Most organizations treat hiring friction as an operational issue. In reality, it’s often a planning issue.
Workforce availability moves with graduation cycles, local investment patterns, enterprise expansion, and macro shifts. Regional demand can heat up months before it shows up as missed hiring targets. If you are only looking at internal ATS metrics, you are usually late.
This is where talent intelligence matters. Real-time labor market signals help workforce planners compare regions early, spot saturation before it hits, and build a more resilient hiring map.
The Shift in Data Engineer Skills: AI & ML Are Redefining the Role
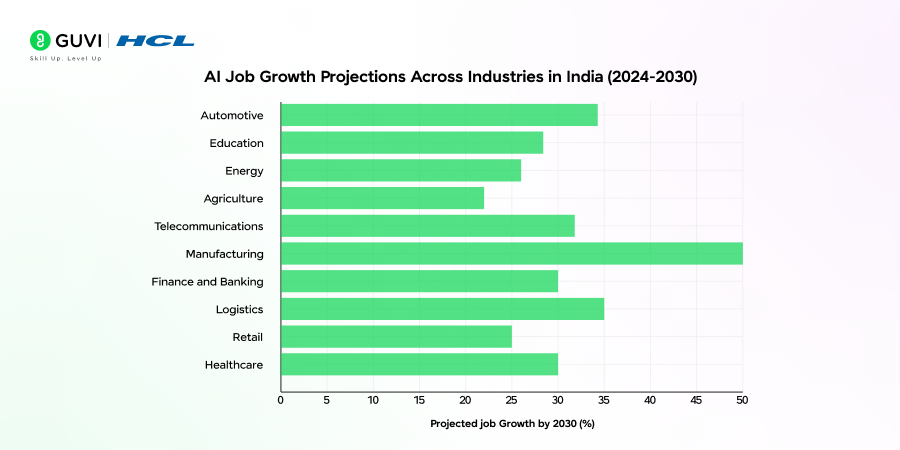
Image Source: Guvi
If you read job descriptions from three years ago and compare them with 2025 listings, the difference is obvious.
Earlier, most data engineering roles centered on data warehouses, ETL pipelines, and batch processing. Those skills still matter. But they are no longer enough. As AI investments moved from pilot projects to production systems, the expectations placed on data engineers changed.
This is not speculation. The World Economic Forum’s Future of Jobs Report 2025 ranks AI and big data among the fastest-growing skill categories globally. That growth does not just create new AI roles. It reshapes adjacent ones, including data engineering.
4.1 From Data Warehousing to AI Infrastructure
Companies building AI systems quickly realize something simple. Models are only as strong as the data pipelines feeding them.
That means data engineers are now expected to handle real-time ingestion, distributed processing frameworks, cloud-native orchestration, and data governance that supports compliance and traceability. Vector databases, feature stores, streaming architectures, and ML-ready data layers are showing up more frequently in job descriptions.
In other words, the role is drifting closer to infrastructure engineering for AI systems.
This shift is also reflected in industry commentary. Gartner’s 2025 AI research highlights “AI-ready data” as a priority area for enterprise maturity. That framing matters. AI readiness is not just about algorithms. It is about stable, scalable data foundations.
4.2 AI Adoption Is Expanding the Skill Surface
As enterprises scale generative AI and predictive analytics, the skill surface of data engineering expands.
Python remains central, but not just for transformation scripts. It now overlaps with ML tooling and experimentation workflows. Distributed systems experience, especially with streaming technologies, becomes more valuable. Cloud expertise moves from nice-to-have to baseline expectation.
What this does to workforce planning is significant. A region may have many data engineers. But how many have worked in environments where AI workloads are production-grade, not experimental?
That is where regional talent trends and skill signals need to be read together.
4.3 The AI Readiness Gap Across Regions
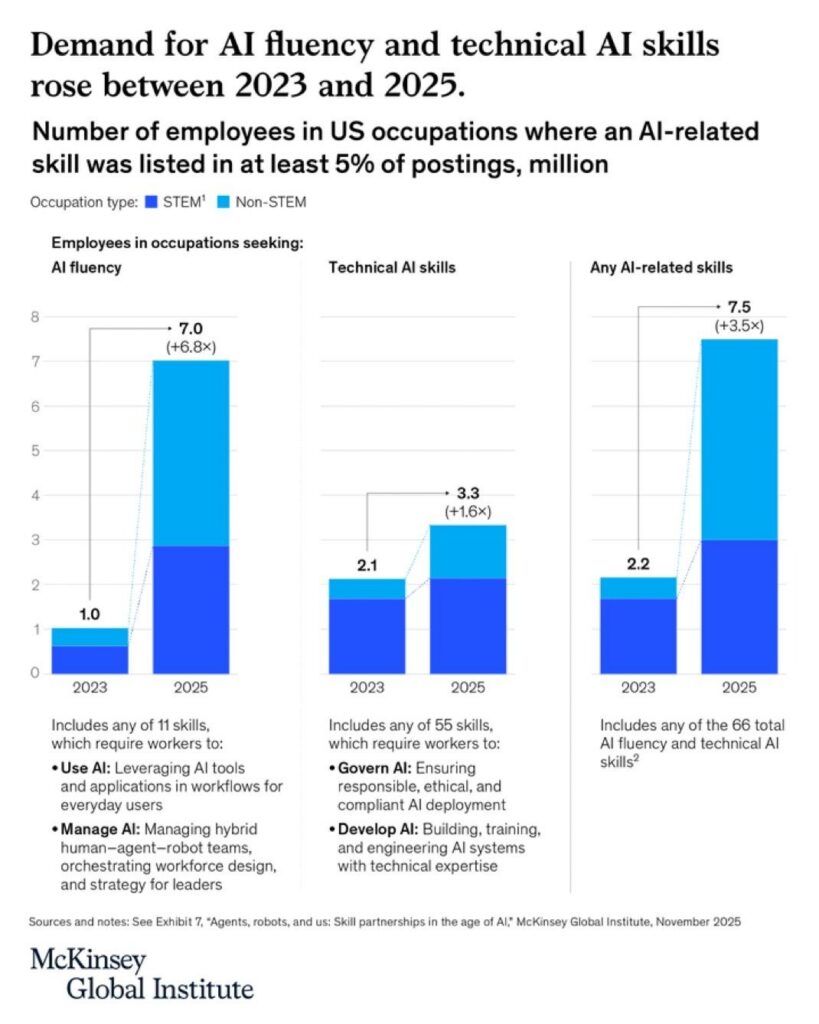
Image Source: McKinsey
Not all talent hubs evolve at the same pace.
Some regions have strong foundational engineering depth but limited exposure to AI-first systems. Others, often where AI startups and research ecosystems cluster, see faster convergence between data engineering and machine learning workflows.
For workforce planners, this creates a new dimension in location strategy. It is no longer enough to ask where data engineer demand is highest. The better question is where the overlap between data engineering and AI capability is strongest.
That overlap is what determines whether your hiring strategy supports short-term pipeline stability or long-term AI infrastructure growth.
Build Your 2026 Location Strategy on Real Market Data
Stop relying on assumptions about talent hubs. Use real-time regional demand and skill intelligence to plan where your next data engineering team should sit.
The Rise of Secondary Talent Hubs in 2026
If the last section was about pressure, this one is about adaptation.
When data engineer demand concentrates too heavily in a few primary cities, companies respond. Not always loudly, but steadily. They start looking elsewhere.
The JobsPikr data shows this shift clearly. While Bangalore and London remain dominant, cities like Hyderabad and Pune are showing sustained momentum. Madrid, though smaller, is growing in relevance. These are not accidental spikes. They reflect companies expanding their hiring footprint, not just following tradition.
5.1 Saturation Forces Geographic Diversification
In high-density markets, hiring becomes slower and more expensive. At some point, leadership teams start asking whether the concentration risk is worth it.
That is when secondary hubs become strategic. They may not match the volume of established markets, but they often offer stronger workforce availability relative to demand. The competition per qualified engineer is lower. The time-to-fill can be shorter. Compensation pressure may be more manageable.
This does not mean abandoning primary hubs. It means building optionality.
5.2 AI Investment Is Spreading Beyond Traditional Centers

Image Source: Statista
AI ecosystems are no longer confined to a handful of global cities. Enterprise digital transformation programs, government-backed tech initiatives, and university research clusters are expanding the map.
When AI adoption increases in a region, local data engineer demand follows. Over time, this builds experience density. Engineers gain exposure to AI-adjacent infrastructure work, which compounds regional capability.
That is how a secondary hub matures. Not because it was declared one, but because repeated enterprise demand created a skill base.
5.3 Secondary Hubs Are Not Just Cost Plays
A common mistake is to treat emerging markets as cost arbitrage. That framing is outdated.
The smarter approach is capability arbitrage. Where can you find engineers with relevant AI-aligned experience who are not competing in the most saturated ecosystem? Where is the growth trajectory strong but not overheated?
This is where regional talent trends need to be read dynamically. A city’s current volume matters less than its direction. Steady multi-year growth signals ecosystem formation.
5.4 Location Strategy Is Now Part of AI Strategy
When organizations talk about AI readiness, they often focus on tooling and data governance. But geographic distribution is just as critical.
If your entire AI infrastructure roadmap depends on hiring in two over-concentrated cities, you are exposed to market volatility. If instead you diversify across primary and secondary hubs, you reduce execution risk and improve resilience.
The shift toward distributed hiring is not just about remote work. It is about balancing demand and workforce availability across regions.
From Recruitment to Location Intelligence: Deciding Where to Hire
At this point, the pattern is clear. Data engineer demand is rising. Skills are shifting toward AI infrastructure. Demand is clustering. Secondary hubs are emerging.
The mistake is treating all of that as a recruiting problem. It’s not. It’s a location intelligence problem.
6.1 Hiring Geography Is a Strategic Lever, Not an Afterthought
Most organizations still decide location reactively. A business unit needs engineers. The hiring team defaults to cities where they have hired before. Maybe they add one new region if leadership pushes.
That approach works when supply is abundant and demand is stable. It breaks when markets overheat.
When workforce availability tightens in a primary hub, you are not just competing on brand. You are competing on timing. And timing is rarely in your control.
Strategic workforce planners flip the question. Instead of asking, “Where can we open roles?” they ask, “Where does the market show sustainable capacity for the next three years?”
That requires external labor signals, not just internal headcount dashboards.
6.2 Reading Regional Talent Trends Before They Show Up in Missed Targets
By the time hiring slows down, the data has usually been signaling pressure for months.
Rising posting intensity in a city. Increasing salary bands. Growing overlap in required skills across multiple enterprises. These are early indicators that data engineer demand is concentrating faster than workforce availability can expand.
With real-time job market tracking, workforce planners can:
- Compare demand growth across regions before committing to large hiring waves.
- Assess skill distribution trends, not just total role counts.
- Identify secondary hubs where hiring velocity is accelerating but competition is not yet extreme.
This shifts workforce planning from reactive to predictive.
6.3 How Talent Intelligence Changes the Conversation
This is where platforms like JobsPikr become more than reporting tools.
Instead of manually piecing together regional insights, workforce teams can track multi-year demand trajectories, normalized skill clusters, and compensation signals across markets. That allows them to model scenarios.
For example, if AI-aligned data engineering skills are growing faster in Hyderabad than in a saturated primary hub, that becomes a strategic input for expansion planning.
If a European city shows steady growth in ML-adjacent data roles but lower overall demand density, it may offer a more resilient hiring environment for AI infrastructure teams.
The goal is not to chase the largest market. It is to balance data engineer demand against workforce availability in a way that reduces execution risk.
Build Your 2026 Location Strategy on Real Market Data
Stop relying on assumptions about talent hubs. Use real-time regional demand and skill intelligence to plan where your next data engineering team should sit.
Strategic Implications for Engineering & Workforce Leaders in 2026
By now, one thing should be clear. Data engineer demand is not just a hiring metric. It’s a signal about infrastructure pressure.
If your organization is serious about AI, automation, and real-time analytics, then data engineering capacity is not optional. It’s foundational. And where that capacity sits geographically will shape how fast you can execute.
7.1 AI Roadmaps Now Depend on Regional Skill Depth
Every AI roadmap eventually runs into the same bottleneck: data readiness.
You can invest in models. You can buy tooling. But without engineers who can build stable pipelines, manage streaming workloads, and support ML deployment, progress slows.
That is why workforce planning for AI cannot ignore regional talent trends. A city with high data engineer headcount but limited AI exposure may not support long-term infrastructure growth. On the other hand, a smaller market with increasing AI-aligned hiring may offer deeper future capacity.
The difference shows up two years later in execution velocity.
7.2 Concentration Risk Is a Strategic Vulnerability
If most of your data engineering footprint sits in one or two overheated markets, you are exposed.
Market shocks, funding cycles, policy changes, or even aggressive competitor hiring can tighten workforce availability quickly. When that happens, scaling slows.
Diversification across regions is not about cost optimization alone. It is about resilience. Spreading teams across primary and emerging hubs reduces dependency on a single labor ecosystem.
In other words, geographic distribution becomes part of infrastructure risk management.
7.3 Workforce Planning Needs External Labor Signals
Internal dashboards tell you what happened. External labor data tells you what is happening.
When data engineer demand rises sharply in a specific city, that signal often appears months before your own hiring slows down. When AI-related skill requirements increase in job descriptions across a region, that trend can indicate where capability depth is forming.
Workforce planners who incorporate these signals early can adjust location strategies before friction becomes visible.
7.4 Location Strategy Is Now Part of Data Infrastructure Strategy
For years, companies treated hiring geography as an operational detail. In 2026, that view is outdated.
Where you are hired determines access to skill depth. Skill depth determines infrastructure quality. Infrastructure quality determines whether AI initiatives scale or stall.
That chain is direct.
The organizations that treat location planning as part of talent intelligence strategy, not just recruitment logistics, will move faster and with fewer surprises.
Data Engineer Demand Is Now a Location Strategy Decision
If there is one shift defining 2026, it is this: data engineer demand is no longer just a hiring trend. It is a signal about infrastructure readiness.
The growth from 2023 to 2025 shows that organizations are still investing heavily in data foundations. External labor projections reinforce that data-centric roles are expected to expand significantly over the next decade. At the same time, the skill mix inside data engineering is moving closer to AI infrastructure. That combination makes the role more critical, not less.
But volume alone is not the real story.
The real story sits inside regional talent trends.
Demand is clustering in major hubs. Workforce availability is uneven. Skill depth varies by geography. Secondary cities are quietly gaining relevance. AI exposure is not distributed equally across markets.
When companies ignore these dynamics, they feel it later as longer hiring cycles, salary inflation, and delayed AI execution. When they monitor them early, they gain options.
This is why location intelligence now sits alongside technical architecture in strategic planning conversations.
The question is no longer, “Can we hire data engineers?” The better question is, “Where does the labor market show sustainable capacity for the type of data engineering work we will need two years from now?”
That requires real-time visibility into:
- Regional demand growth
- Skill distribution shifts
- Workforce availability signals
- Emerging hub momentum
This is where talent intelligence becomes operational leverage.
JobsPikr enables workforce planners, leaders, and location strategy teams to move from assumption to evidence. By transforming raw job market data into structured insights, organizations can compare regions before opening roles, forecast saturation risk, and align hiring geography with AI infrastructure plans.
In 2026, the advantage does not go to the company that hires the fastest. It goes to the company that hires in the right place.
Build Your 2026 Location Strategy on Real Market Data
Stop relying on assumptions about talent hubs. Use real-time regional demand and skill intelligence to plan where your next data engineering team should sit.
FAQs
1. What is driving data engineer demand in 2026?
AI is a big reason, but not because every company suddenly needs more models. It’s because AI projects collapse quickly when the data layer is slow, messy, or unreliable. Most teams are hiring data engineers to rebuild the plumbing: cleaner pipelines, faster ingestion, better monitoring, and datasets that can be trusted in production. That is why data engineer demand keeps showing up even when other tech roles fluctuate.
2. Which regions show the strongest data engineer demand growth?
The biggest volumes still sit in the usual hubs. Bangalore stays dominant. London and New York remain strong. In India, Hyderabad continues to show serious pull. What’s worth watching in 2026 is the steady rise of secondary markets like Pune and in Europe, growth pockets like Madrid.
The point is not “these are the best cities.” The point is that regional talent trends are shifting, and companies that only hire in the loudest hubs end up fighting the most crowded battles.
3. How are AI and ML changing the data engineering role?
It’s changing what “good” looks like.
A few years ago, you could be a strong data engineer focused mainly on batch ETL and warehouses. Now, many teams expect data engineers to support ML workflows and real-time data needs. That means more demand for experience in streaming systems, cloud-native orchestration, and data governance that can hold up when AI starts influencing decisions.
So the job title stays the same, but the skills in demand are moving closer to AI infrastructure.
4. What are regional talent trends, and why do they matter?
Regional talent trends are basically the “shape” of the labor market by location. Where the jobs are increasing, where skills are deepening, where competition is heating up, and where workforce availability is starting to thin out.
They matter because a region can look attractive on reputation, but still be a risky hiring market. If demand is rising faster than supply, you will feel it through slower hiring, higher costs, and more compromises. Location strategy becomes the lever that prevents that pain from becoming your default.
5. How can talent intelligence improve global hiring decisions?
It helps you stop guessing.
Instead of relying on old assumptions about talent hubs, talent intelligence lets you compare regions using real hiring signals. You can see where data engineer demand is accelerating, which skills are appearing more often, and where competition is building before your hiring plan gets stuck.
For workforce planning teams, that means fewer surprises, better location bets, and a hiring footprint that supports long-term infrastructure goals, not just short-term headcount targets.




