
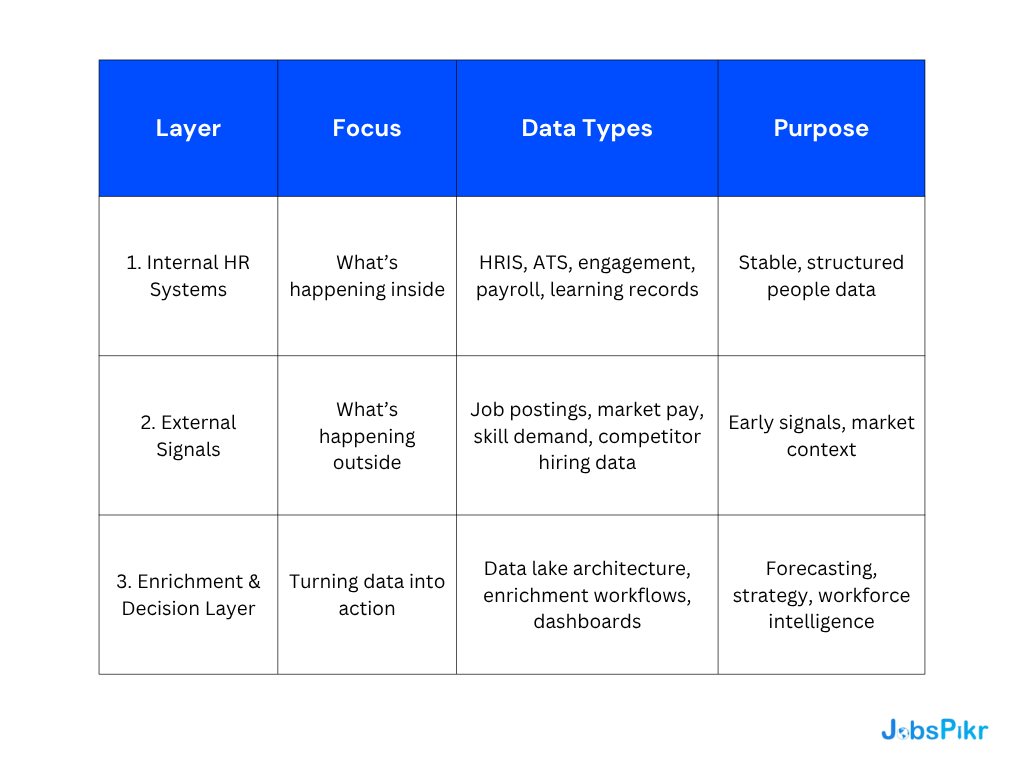
- **TL;DR**
- Why Your Workforce Plan Breaks When Job Evolution Accelerates
- How To Detect Job Evolution Early Using Global Job Data Signals
- Turn Job Data Into Decisions Your Teams Can Stand Behind
- What To Do When AI Role Impact Blurs Role Boundaries And Ownership
- How To Fix Skills Mismatch In Engineering, Data, And Product Roles
- Turn Job Data Into Decisions Your Teams Can Stand Behind
- How To Avoid Bad Decisions From Bad Job Data
- Freshness And Change Tracking Decide Whether Insights Are Actionable
- How To Reduce Compliance And Governance Risk As AI Adoption Grows
- What People Analytics Teams Need To Trust Job Market Insights
- Turn Job Data Into Decisions Your Teams Can Stand Behind
- How Roles Are Actually Evolving In The Age Of AI
- How To Build A Reskilling Strategy That Matches Real Market Demand
- Turn Job Data Into Decisions Your Teams Can Stand Behind
- How JobsPikr Turns Job Data Into Workforce Intelligence You Can Defend
- How To Turn Job Evolution Into A Strategic Advantage
- Turn Job Data Into Decisions Your Teams Can Stand Behind
- FAQs
**TL;DR**
Workforce plans are breaking because job evolution is happening inside roles faster than internal HR systems can detect. AI role impact is showing up as shifting tasks, hybrid skill requirements, and new governance needs. Global job data catches these changes earlier, so teams can prioritize reskilling, reduce skills mismatch, and make workforce decisions on signals they can defend. JobsPikr takes messy job data and turns it into clean, reliable workforce signals your people analytics and data engineering teams can use.
Key takeaways
- Job evolution is now a forecasting problem: internal data is lagging, so plans drift from reality quickly.
- AI role impact looks like skill blending: roles absorb automation, analytics, and oversight responsibilities.
- Global job data provides early signals: skill drift and demand shifts appear in postings before org charts change.
- Reskilling trends should drive priorities: invest in skills the market is validating, not what feels urgent internally.
- Trust matters: without clean, governed job data, job market insights are not usable at enterprise scale.
Why Your Workforce Plan Breaks When Job Evolution Accelerates
Most workforce plans assume roles are stable enough to forecast skills and capacity a year out. That assumption is now the weakest link. Job evolution is happening inside roles faster than your internal systems can capture, which means planning drifts even when your headcount math is “right.”
Role Descriptions Freeze While Work Changes Week on Week
Here’s what usually happens in practice:
- Job descriptions get updated on a calendar, not on reality.
Most teams refresh JDs during annual cycles, reorgs, or a big hiring push. But the work changes continuously because tools, processes, and expectations change continuously. That’s the first gap.
- Titles stay stable even when the role content shifts.
A “Data Analyst” title can quietly absorb data validation, pipeline QA, and tool configuration over a few months. A “Product Manager” title can absorb vendor evaluation, AI workflow design, and measurement, without anyone formally redefining the role. The org chart looks stable, but the operating model has moved.
- Your internal skills inventory becomes stale without anyone noticing.
Skills frameworks and HRIS fields lag because they depend on manual updates or periodic reviews. So, you end up planning with yesterday’s skill taxonomy while teams are living in today’s workflow. That’s how you get a “we hired for it” situation and still feel understaffed.
What global job data adds here is early detection. When thousands of postings for the same role family start mentioning new tools and responsibilities, you can see job evolution unfolding at market speed, not HR speed.
AI Role Impact Creates Hidden Scope Creep Inside Existing Roles
This is where most workforce plans get blindsided, because AI role impact rarely arrives as a neat “role replaced” event. It shows up as scope creep.
- New work gets added, old work doesn’t get removed.
Teams adopt AI tooling to move faster, but the human work doesn’t disappear. Instead, it shifts into review, exception handling, quality checks, and monitoring. People end up doing “the old job” plus “the AI-enabled job” at the same time.
- Ownership boundaries blur and nobody re-draws them.
When workflows become automated, decisions about quality, approvals, and risk move around. Engineering owns part of it, operations own part of it, compliance wants oversight, and product wants outcomes. If you do not assign clear ownership, execution slows down and accountability becomes fuzzy.
- Hiring profiles lag the real job.
Your role profile still lists the classic requirements, while the day-to-day now includes automation stewardship, analytics fluency, and governance basics. That mismatch is why hiring feels harder even when the labor market looks “fine.” The issue is not volume. It’s fit.
Global job data makes this visible because postings expose the new “true requirements” as they emerge. That helps you quantify ai role impact instead of debating it qualitatively.
Internal HR Data Shows Lagging Indicators, Not Early Warnings
Internal data is useful, but it tells you what already happened. Job evolution punishes teams that only look backward.
- Attrition and performance data show damage after it’s done.
You see burnout after the scope creep hits, not before. You see capability gaps after delivery slips, not while the skills are drifting. That’s why reactive planning becomes the default.
- Learning data is not demand data.
Completion rates tell you what people took, not what the market is rewarding. Without external benchmarks, reskilling can turn into well-funded activity that does not move workforce readiness.
- Internal dashboards miss competitive context.
Your HRIS cannot tell you how competitors are redefining the same roles, which tools they are standardizing on, or which skills are becoming table stakes in your sector. That’s exactly where global job trends and job market insights matter.
Global job data fills that gap by acting like an early-warning layer. It surfaces demand shifts, skill drift, and reskilling trends before they show up in your internal outcomes.
How To Detect Job Evolution Early Using Global Job Data Signals
If you wait for internal HR systems to “confirm” job evolution, you’re already late. The fix is to treat global job data like an early-warning feed. It shows what employers are asking for right now, at scale, before your org charts, competency frameworks, or L&D catalogs catch up. This matters because the pace is not slowing down. The World Economic Forum estimates six in ten workers will need training before 2027, while only about half are seen to have access to adequate training today.
Hiring Velocity Exposes Where Change Is Actually Happening
Think of hiring velocity as a pressure gauge. When demand for a role family spikes, it usually means one of three things is happening: the function is being scaled, the work is being reorganized, or the skill mix inside the role is changing. Global job data helps you separate “we are hiring more” from “the job itself is morphing.”
Here’s a simple way teams operationalize it without over-engineering:
- Track role-family posting volume over time, not one-off spikes.
A single quarter bump can be seasonal. Sustained acceleration across multiple months is more often a structural shift. This is where job market insights become useful for planning, not just reporting.
- Split velocity by industry and peer set.
If everyone in your sector is scaling a role family and you are not, you might be under-investing. If only a subset is scaling and they share a similar business model, that’s a more targeted signal.
- Use velocity changes as a trigger for “role review,” not “panic hiring.”
When velocity moves, the question should be: what is changing inside the role, and what skills are getting pulled in? That’s how you stay ahead of job evolution instead of reacting to it.
Skill Shift Monitoring Catches Role Drift Before Reorganization
The most reliable early signal is not the job title. It’s the skills inside the job description.
A clean approach looks like this:
- Monitor skill frequency inside the same role title over time.
If “prompt engineering,” “workflow automation,” “model evaluation,” or “data governance” starts showing up more often in the same role family, that’s job evolution in motion. Titles will lag. Skill mentions won’t.
- Watch for “stacking skills,” not just new tools.
AI role impact often shows up as combinations, for example domain expertise plus automation plus measurement. That’s what creates hybrid roles and hiring friction.
- Flag skills that move from “nice-to-have” to “required.”
When the wording shifts toward stronger requirements language, it’s a signal that the market is standardizing expectations.
LinkedIn’s Economic Graph reporting shows how fast this is moving in the wild. Their Work Change research found that AI literacy skills added by members increased sharply (177% since 2023), far faster than overall skill additions. That is exactly the kind of external signal internal skills inventories tend to miss until the gap becomes painful.
Location And Remote Patterns Reveal When Roles Are Being Repackaged
Location data is not just “where talent is.” It’s also a clue about how the role is being redesigned.
Two patterns to watch:
- Remote expansion usually correlates with skill modularization.
When roles go remote at scale, tasks often become more standardized, tool-driven, and measurable. That changes the skill profile even if the title stays the same.
- New hubs often reveal execution constraints.
If postings shift into specific metros or countries, it can signal a change in delivery model, cost strategy, compliance needs, or time-zone coverage. Those are operational decisions reflected through job data.
For people analytics teams, this is a practical way to identify whether job evolution is being driven by new workflows, new operating cadence, or new governance constraints.
Employer Language Flags AI Adoption Maturity Levels
This is the underrated signal: how employers describe work tells you how mature their AI adoption is.
A simple maturity read looks like:
- Early-stage language: “familiarity with AI tools,” “interest in automation,” “assist with.”
This usually signals experimentation and uneven enablement. - Mid-stage language: “build workflows,” “integrate,” “evaluate,” “monitor.”
This is where ai role impact becomes operational, and role boundaries start to blur. - Later-stage language: “governance,” “risk controls,” “auditability,” “model performance tracking.” This signals production-scale adoption, where compliance and quality work expands fast.
The point is not semantics. The point is that language is often the first place job evolution shows up, especially when org charts are slow to change.
Turn Job Data Into Decisions Your Teams Can Stand Behind
Clean, governed job data powering reliable workforce intelligence at scale.
What To Do When AI Role Impact Blurs Role Boundaries And Ownership
When AI moves into daily workflows, roles start bleeding into each other. Decisions travel across teams. Automation creates new operational work that no one explicitly owns. The result is not chaos, but quiet friction that slows delivery and increases risk.
The fix is not another org redesign. It’s making ownership visible, measurable, and aligned with how work is actually changing.
Decision Rights Get Messy When Hybrid Roles Expand
Hybrid roles stretch accountability in ways most org structures were never designed for.
- Decision ownership fragments.
An engineer may control the automation logic, operations owns the downstream workflow, and compliance wants sign-off authority. Everyone influences the outcome, but no single role owns the end-to-end result. That creates hesitation and over-alignment loops.
- Escalations become ambiguous.
When something breaks, teams argue about whether it’s a tooling issue, a data issue, or a process issue. Resolution time stretches because escalation paths are unclear.
- Performance metrics lag reality.
People are still measured on legacy outputs while their actual work has shifted toward governance, monitoring, and exception handling. This disconnect quietly erodes accountability.
- Hiring profiles remain outdated.
New ownership expectations are rarely reflected in role descriptions quickly enough, which means new hires arrive underprepared for the real scope of the job.
Global job data helps benchmark how other companies are resolving these boundaries by tracking how ownership language and accountability requirements evolve in job descriptions.
Quality And Risk Work Explodes Without Clear Owners
AI increases throughput, but it also multiplies failure modes. Quality and risk work expand even when no new roles are formally created.
- Monitoring and validation load grows continuously.
Model drift checks, data quality reviews, and automation audits become recurring operational work, not one-off tasks.
- Risk review often stays reactive.
Compliance and legal teams get pulled in after systems are already live, which creates patchwork controls instead of embedded governance.
- Capacity planning underestimates operational overhead.
Workforce models still assume the old workload profile while manual reviews, escalations, and audits quietly consume real headcount.
Job market insights show where organizations are explicitly baking these responsibilities into roles rather than treating them as side work. That signal helps workforce teams anticipate capacity needs instead of reacting to incidents.
Cross-Functional Dependencies Multiply And Slow Execution
AI workflows rarely stay inside one function. Data, tooling, risk, and delivery now cut across traditional boundaries.
Two baseline shifts are becoming visible in global job trends.
Business-First Technical Fluency As a Baseline
Non-technical roles increasingly need enough technical literacy to understand automation limits, data quality constraints, and system trade-offs. This reduces handoff friction and unrealistic expectations.
Technical-First Business Context as A Baseline
Technical roles are expected to understand revenue impact, regulatory exposure, and operational cost, not just system performance. This tightens decision quality and speeds alignment.
When both sides evolve together, execution accelerates. When they evolve unevenly, coordination costs explode.
How To Fix Skills Mismatch In Engineering, Data, And Product Roles
Skills mismatch doesn’t announce itself with a hiring freeze or a missed OKR. It creeps in quietly. Delivery starts taking longer than expected. Teams depend on a few key people for everything. Small changes feel risky because nobody fully understands how the system behaves anymore.
Engineering, data, and product roles usually feel this first because they sit closest to tooling decisions and automation. As job evolution accelerates, the definition of “competent” inside these roles keeps shifting, but most organizations update hiring profiles and learning paths far too slowly.

Image Source: vervoe
Platform Ownership Gaps Create Delivery Bottlenecks
Many teams start by building small internal tools to remove friction. A script to clean data. A dashboard to track experiments. A lightweight workflow to automate handoffs. None of this feels risky at the beginning. It feels pragmatic.
Over time, these pieces start carrying real business load. Other teams depend on them. Edge cases accumulate. Failures have downstream impact. But ownership rarely evolves at the same pace.
- Responsibility stays informal even as dependency grows.
The original builder often remains the only person who understands how the system behaves in production. When that person is unavailable, progress slows or work pauses entirely.
- Stability work keeps getting postponed.
Refactoring, documentation, monitoring, and operational hardening get pushed aside because feature work feels more urgent in the moment. The cost shows up later as fragile delivery.
- New hires inherit complexity without context.
Instead of onboarding into a clearly defined platform, they learn by reverse-engineering decisions made months or years earlier. Ramp time stretches and small changes feel risky.
If you look at how roles are described in the market today, engineering postings increasingly reference internal enablement, operational ownership, and reliability responsibilities. That’s a concrete signal that job evolution is pushing engineering away from pure feature delivery toward platform stewardship.
Data Teams Get Stuck In Pipelines Instead Of Decision Support
Data teams often scale infrastructure faster than they scale decision impact. Pipelines multiply. Dashboards grow. But the organization still debates which numbers to trust.
- Hiring skews toward building rather than interpreting.
Strong pipeline builders are essential, but without enough analytical depth and domain understanding, insights remain shallow or disconnected from business reality.
- Data quality ownership becomes fragmented across teams.
When nobody clearly owns semantic consistency, validation logic, and lineage, trust erodes quietly. Stakeholders stop relying on central datasets and start maintaining their own versions.
- Manual work creeps back into the workflow.
People export data into spreadsheets, rebuild logic locally, or rely on one-off queries because centralized systems feel slow or opaque.
Job data shows increasing demand for profiles that combine engineering discipline with analytical judgment and domain fluency. That matters for reskilling because it tells you where specialization alone is starting to break down in real operating environments.
Product Teams Absorb AI Workflow Design Without New Guardrails
Product roles are expanding beyond feature definition into workflow orchestration and automation design. That adds a different kind of cognitive load.
- Product decisions now influence system behavior, not just UX.
Choices about prompts, automation logic, thresholds, and fallbacks directly shape outcomes at scale. Mistakes propagate faster than in traditional feature releases.
- Tooling and vendor choices create long-term constraints.
Once an organization commits to a model provider or automation layer, switching costs and operational dependencies follow. Product teams increasingly carry that responsibility.
- Risk conversations move closer to roadmap decisions.
Privacy exposure, audit requirements, and operational reliability are no longer downstream concerns. They surface during prioritization and experimentation.
If you scan how product roles are written today, references to data fluency, experimentation discipline, and operational accountability appear far more often than a few years ago. That’s job evolution showing up directly in hiring language, not in strategy decks.
Across engineering, data, and product, the fix is not simply adding headcount. It’s redesigning role expectations, reskilling pathways, and ownership models to match how the work is shifting in the market.
Turn Job Data Into Decisions Your Teams Can Stand Behind
Clean, governed job data powering reliable workforce intelligence at scale.
How To Avoid Bad Decisions From Bad Job Data
Global job data is powerful, but it’s also easy to misuse. The risk is not “lack of coverage.” The risk is building workforce plans on signals that look clean in a dashboard but are directionally wrong because the underlying data is noisy. When that happens, job evolution analysis turns into confident storytelling instead of usable workforce intelligence.
Duplicate And Reposted Jobs Can Distort Job Evolution Signals
If you do not control duplicates and reposts, you inflate demand and misread job market insights.
- Duplicates inflate demand in uneven ways.
The same role can appear across multiple job boards, aggregators, and mirrored ATS pages. That does not mean demand is higher. It means distribution is wider. Without deduplication, you end up treating marketing reach as hiring intent.
- Reposts are a different signal than new demand.
A repost can mean the role is hard to fill, compensation is misaligned, approvals are slow, or the job description is not attracting the right talent. If you lump reposts into “growth,” your global job trends become misleading.
- Some duplicates are almost identical, others are subtly different.
This matters because simple URL-based dedupe misses near-duplicates, while overly aggressive dedupe can collapse genuinely different requisitions. The right approach usually combines multiple fingerprints, title similarity, location normalization, employer entity resolution, and description overlap.
- Benchmarking breaks when duplication varies by employer.
Some companies post cleanly. Others repost constantly. If you do not normalize for that behavior, your competitor comparisons are biased by posting habits, not workforce strategy.
Title And Skill Chaos Creates Fake Categories And Wrong Conclusions
This is where a lot of job evolution work goes off the rails, especially when teams rely on surface-level parsing.
- Titles are not stable identifiers.
“Data Analyst,” “Insights Analyst,” “BI Analyst,” and “Reporting Specialist” can be near-identical roles, or completely different roles, depending on the company and seniority. If you do not normalize titles into consistent role families, you will “discover” trends that are really naming differences.
- Titles get inflated on purpose.
Some employers use aspirational titles like “Lead” or “Head” to attract candidates, while the responsibilities read like mid-level work. Without cross-checking title with description content, you misclassify level and role scope.
- Skill lists are often wishlists, not reality.
Job descriptions frequently include long tool menus copied from templates. Counting every tool equally overstates reskilling trends and pushes teams toward bloated learning roadmaps. Skills need weighting, clustering, and filtering based on context.
- Hybrid roles expose taxonomy weakness first.
Cross-domain roles are exactly where job evolution shows up early, but they are also where naive taxonomies fail. If your taxonomy cannot represent blended responsibilities and skill adjacency, you either misclassify the role or ignore it.
Freshness And Change Tracking Decide Whether Insights Are Actionable
Even perfectly cleaned data becomes useless if it is stale or if you cannot track how roles are changing over time.
- Freshness is not just “posted date.”
A listing can be posted once and edited multiple times. Or it can be reposted with a new date but the same content. Without live-status checks and update tracking, you cannot tell whether demand is real or recycled.
- You need to observe changes in the description itself.
Job evolution shows up as changing requirements, new tools, and shifting responsibilities. If you only store one snapshot, you lose the trail. If you store snapshots but do not diff them, you cannot measure direction.
- Trend charts fail when definitions shift.
If your normalization rules or skill mapping logic changes month to month, your trendline becomes an artifact of your pipeline. Stable versioning and audit trails are what make job market insights defensible.
- People analytics teams need “show your work,” not just results.
When stakeholders challenge an insight, you need lineage: where the data came from, what transformations were applied, and what quality gates were passed. Without that, global job data becomes untrusted quickly.
How To Reduce Compliance And Governance Risk As AI Adoption Grows
As AI moves deeper into everyday workflows, workforce decisions start carrying regulatory and audit exposure that did not exist even two years ago. The risk is not only what models do. It’s how data is collected, reused, shared across teams, and eventually relied on for planning and investment decisions.
Job data is especially sensitive in this context because it often sits outside traditional HR governance while still influencing strategic decisions. If governance is bolted on later, trust erodes quickly.
Policy Breaks When Operational Reality Moves Faster Than Reviews
Most policies assume stable workflows. AI does the opposite. Teams experiment, automate, and integrate faster than policy cycles can adapt. Over time, the written rules describe a world that no longer exists.
Data that was originally approved for research quietly flows into forecasting models, internal dashboards, and executive reporting. Access expands organically as more teams “just need visibility.” Retention assumptions drift as datasets get copied and merged into other systems. None of this is malicious. It’s operational gravity. But without periodic policy reconciliation against actual usage, compliance risk accumulates invisibly.
This is why governance has to be embedded into operating workflows rather than treated as an annual review exercise.
Auditability Fails Without Lineage And Change Tracking
When leadership or auditors ask, “How did we arrive at this conclusion?”, teams often realize they cannot reconstruct the full path.
- Point-in-time extracts lose historical context.
You cannot explain trend shifts if you only keep the latest snapshot and overwrite prior data.
- Transformation logic drifts without versioning
Normalization rules evolve, but past reports remain unchanged, making comparisons unreliable.
- Manual patches break traceability.
One-off fixes applied in notebooks or ad-hoc pipelines rarely get documented properly.
Auditability is not about paperwork. It’s about being able to explain your reasoning chain when decisions matter.
Governance Work Expands Faster Than Teams Expect
AI systems increase operational surface area even when headcount stays flat. What starts as “just another data feed” turns into ongoing operational responsibility.
- Vendor contracts introduce ongoing obligations.
Usage limits, redistribution rights, data residency, and audit clauses need active monitoring, not one-time review.
- Security exposure grows through integrations.
Every new API, dashboard, or downstream consumer increases access complexity.
- Exception handling becomes a recurring workload.
Data anomalies, pipeline failures, and policy edge cases require real human time.
- Risk ownership often remains implicit.
When no role explicitly owns governance outcomes, issues linger longer than they should.
Treating governance capacity as part of workforce planning, not overhead, prevents unpleasant surprises later.
What People Analytics Teams Need To Trust Job Market Insights
People analytics teams don’t struggle with dashboards. They struggle with credibility. If job evolution insights can’t be explained and defended, they won’t influence hiring plans, reskilling, or workforce strategy.
External Benchmarks Prevent Misleading Internal Narratives
Internal HR data is useful, but it’s inward-looking. Global job data adds the outside view: how role expectations are shifting in the market, what competitors are asking for, and which skills are becoming standard. Without that benchmark, teams can end up optimizing for yesterday’s role definitions while the market moves on.
Skills Intelligence Breaks Without Consistent Taxonomy
Skills analysis collapses quickly when titles and skill labels are inconsistent. The same capability appears under multiple names, tool stacks change, and hybrid roles blur boundaries. Without normalization and a stable taxonomy, reskilling trends become noisy and hard to act on, even when the underlying signal is real.
Trust Requirements Decide Adoption More Than Coverage
Coverage is not the differentiator, governance is. People analytics teams need clear answers on freshness, deduplication, change tracking, and auditability. If the data behaves like a black box, job market insights get dismissed as “interesting” instead of becoming a trusted input to decisions.
Turn Job Data Into Decisions Your Teams Can Stand Behind
Clean, governed job data powering reliable workforce intelligence at scale.
How Roles Are Actually Evolving In The Age Of AI
Roles are changing in a boring way. Not with dramatic title changes, but with small additions that keep stacking up. That stacking is what job evolution looks like in real job descriptions.
Here are the clearest ways it shows up.
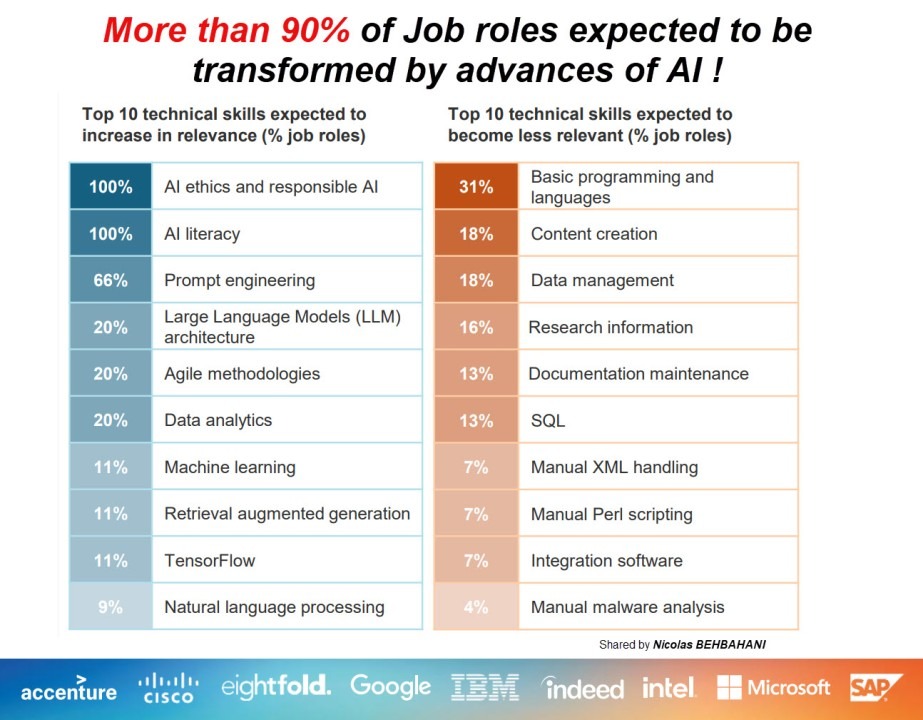
Image Source: LinkedIn
Role Expectations Are Expanding Without Changing Titles
This is the most common pattern across global job data. The title stays the same, but the “real job” grows.
You’ll see it when familiar roles start absorbing responsibility for things that used to sit elsewhere. Monitoring. Validation. Governance. Workflow design. Tool evaluation. None of those were default expectations for many roles a few years ago. Now they show up more often, even for the same job families.
The practical implication is simple: if your workforce plan assumes the old version of the role, you will under-estimate time, skill requirements, and headcount needs.
Example: Software Engineers Are Being Asked To Own What Happens After Automation Goes Live
Older engineering postings leaned heavily on building and shipping. Newer postings increasingly imply: “Ship it and keep it working.”
That tends to show up in responsibilities like:
- building internal tools other teams rely on, then maintaining them as usage grows
- watching system behavior, not just deploying features
- handling edge cases, failures, and drift instead of treating them as rare incidents
This changes what “senior” means. It is less about writing complex code and more about preventing downstream chaos.
Example: Data Analysts Are Shifting From Reporting To Interpretation
In many teams, reporting is now cheap. Dashboards exist. Automated summaries exist. What is scarce is sense-making.
So analyst roles are evolving toward:
- validating outputs from automated systems and calling out when they look wrong
- translating metrics into decisions, not just producing charts
- partnering with business teams on experiments and trade-offs
This is ai role impact that does not look like replacement. It looks like the human role moving up the chain into judgment and context.
Example: Product Managers Are Becoming Workflow And Risk Designers
When features are driven by AI or automation, product work expands beyond “what should we build.”
Product roles increasingly get pulled into:
- designing how humans and automation interact, including fallbacks and escalation paths
- thinking through failure modes and unintended outcomes early, not after launch
- evaluating long-term constraints introduced by tools and vendors
Even if the title is unchanged, the accountability expands. That is job evolution in practice.
Role Boundaries Are Blurring, Which Forces Skill Blending
A second pattern shows up once you look across functions. Roles are borrowing skills from each other.
Commercial roles need more analytics fluency. Technical roles need more business context. HR roles need more labor market intelligence. This is not a nice-to-have shift. It is driven by workflows that now depend on shared tooling, shared data definitions, and shared governance.
That is why reskilling trends are moving toward cross-domain skills. The work itself is cross-domain now.
What These Examples Have In Common
Across functions, the pattern is consistent:
- Roles absorb system ownership, not just execution.
- Skills blend across technical, analytical, and domain boundaries.
- Accountability expands into quality, risk, and long-term operability.
- Reskilling becomes continuous instead of episodic.
None of this shows up cleanly if you only track titles and headcount. It shows up when you analyze job descriptions at scale, track skill drift, and observe how expectations compound over time using global job data.
That is why job evolution needs to be measured as a living signal, not a static taxonomy exercise.
How To Build A Reskilling Strategy That Matches Real Market Demand
Most reskilling programs fail for one simple reason. They are designed around what the organization thinks it will need, not what the market is already rewarding. By the time internal plans catch up, the skill gap has usually widened and hiring becomes harder, slower, and more expensive.
If job evolution is accelerating, reskilling has to become a continuous operating capability, not an occasional initiative.
Internal Learning Signals Lag Behind Market Reality
Learning data tells you what people enrolled in and completed. It does not tell you whether those skills are becoming more valuable in the market or fading out of relevance.
A team may invest heavily in a certification because it feels strategically important, while global job data shows demand shifting toward adjacent tools or entirely different skill clusters. That mismatch creates a false sense of progress. Activity looks high. Readiness does not improve.
This is why reskilling trends need external validation. Market demand should anchor learning priorities, not internal enthusiasm or anecdotal signals.
Skill Adjacency Shows Where Reskilling Is Actually Feasible
Not all skill transitions carry the same risk or time investment. Some skills compound naturally. Others require a full reset.
Job data reveals which skills frequently co-occur in real roles and which transitions are common across industries. That creates a practical map of adjacency. For example, analysts often move into analytics engineering. QA engineers often move into automation roles. Operations analysts often move into tooling-heavy process design.
These pathways matter because they determine how quickly reskilling investments convert into usable capacity.
Hiring Signals Help You Avoid Over-Investing In The Wrong Skills
Rising course enrollments or internal excitement can be misleading. What matters is whether employers are consistently paying for those skills.
Tracking job market insights like posting velocity, salary movement, and skill frequency helps filter signal from noise. If demand is stable or declining, heavy reskilling investment may not compound. If demand is accelerating across multiple industries, that’s where early investment pays off.
This protects reskilling budgets from chasing short-lived hype cycles.
How Teams Operationalize This In Practice
Strong teams connect three signals:
- what skills they already have internally
- what global job trends indicate the market is moving toward
- how adjacent those skills are in real hiring data
That combination allows leaders to prioritize a small number of high-impact reskilling bets instead of spreading investment thin across dozens of programs.
When reskilling aligns with verified market demand, workforce readiness improves faster and hiring pressure drops naturally.
Turn Job Data Into Decisions Your Teams Can Stand Behind
Clean, governed job data powering reliable workforce intelligence at scale.
How JobsPikr Turns Job Data Into Workforce Intelligence You Can Defend
Most teams can pull job postings. The hard part is turning them into job evolution insights that stand up in a stakeholder review. JobsPikr focuses on making job data usable, comparable, and trustworthy for workforce decisions.
Clean Inputs So Job Evolution Isn’t Just Noise
Raw postings are inconsistent. JobsPikr standardizes the basics so you are comparing like with like, not title chaos or messy entities.
Title Normalization That Prevents Fake Trends
Role names vary across employers. JobsPikr maps titles into stable role families so “growth” is not just naming variance.
Company Resolution That Stops Duplicate Employer Counting
The same employer can appear under multiple names and subsidiaries. JobsPikr resolves entities so your benchmarks do not fragment.
Location Standardization For Real Global Job Data Comparisons
Location formats differ widely. JobsPikr normalizes locations into comparable geographies for cleaner global job trends.
Skills Extraction Mapped To A Stable Taxonomy
Skills in postings are messy and repetitive. JobsPikr extracts and maps skills so trend tracking stays consistent over time.
Freshness And Change Tracking That Makes Shifts Measurable
To understand job evolution, you need history. JobsPikr tracks updates and changes so you can see role drift instead of one-time snapshots.
Quality Controls That Protect Job Market Insights
JobsPikr applies quality checks so duplicates, reposts, and stale listings do not distort your signals.
Compliance-First Delivery For Enterprise Teams
For teams evaluating secure data sources, JobsPikr is designed for governed access and usage, so workforce intelligence is not a risk.
How To Turn Job Evolution Into A Strategic Advantage
Job evolution is no longer a slow, predictable shift. Roles are expanding, blending, and absorbing new responsibility faster than internal systems can track. When organizations rely only on historical HR data, they end up reacting late, over-investing in the wrong skills, and underestimating operational risk.
Global job data changes that equation. It exposes real ai role impact, emerging reskilling trends, and shifting role expectations while those signals are still forming in the market. When this intelligence is clean, governed, and operationalized, workforce planning becomes proactive instead of reactive.
JobsPikr provides that intelligence layer, turning raw job data into reliable job market insights that people analytics and data engineering teams can confidently use to guide hiring, reskilling, and long-term workforce strategy.
Turn Job Data Into Decisions Your Teams Can Stand Behind
Clean, governed job data powering reliable workforce intelligence at scale.
FAQs
1. How Can Global Job Data Help Organizations Track Job Evolution Earlier Than Internal HR Systems?
Internal systems update slowly. Job descriptions in the market update fast. Global job data shows what employers are asking for right now, so you spot job evolution before it hits your hiring plan.
2. What Does AI Role Impact Actually Look Like In Real Job Descriptions Today?
Mostly scope creep. The title stays the same, but roles pick up new work like monitoring automation, validating outputs, or owning workflows. That’s ai role impact in practice.
3. How Can Teams Use Job Market Insights To Build Smarter Reskilling Strategies?
Use postings to see which skills are rising and which skill combos keep showing up together. Then reskill into those adjacencies instead of guessing based on internal preferences.
4. Why Is Data Quality And Trust So Critical When Using Job Data For Workforce Planning?
Because messy job data creates fake trends. Duplicates, stale listings, and inconsistent titles can make job market insights look convincing but wrong. Trust needs clean, comparable inputs.
5. How Does AI In HR Change The Role Of People Analytics And Workforce Planning Teams?
It pushes teams toward labor intelligence. Instead of only internal metrics, they use global job data to benchmark demand, track reskilling trends, and plan for role shifts earlier.




