
- **TL;DR**
- What is responsible AI, and why does responsible data decide whether it works
- Build responsible AI on data you can stand behind
- Why responsible data matters more than model performance in real AI systems
- Lesson 1: Data ethics starts with how you collect data, not how you use it later
- Lesson 2: responsible AI needs standardized data because messy data creates unfair outcomes
- Build responsible AI on data you can stand behind
- Lesson 3: Fair AI practices start with coverage and representation at the data layer
- Lesson 4: Responsible AI requires secure data access because misuse is part of the threat model
- Lesson 5: Transparency is not a feature; it is the backbone of responsible AI
- Build responsible AI on data you can stand behind
- Where responsible AI shows up in people analytics and workforce decisions
- A practical way to sanity-check your responsible AI and responsible data posture
- Building responsible AI that people actually trust over time
- Build responsible AI on data you can stand behind
- FAQs:
**TL;DR**
Responsible AI is not something you “add on” after building a model. It is something you either design into your data foundation or struggle to fix later.
When people ask what is responsible AI, they often think about explainability, bias, or governance at the model level. In practice, those outcomes are already decided much earlier. The way data is collected, structured, secured, and explained quietly shapes whether an AI system behaves fairly or amplifies existing problems.
JobsPikr’s approach to responsible AI starts with responsible data. That means ethical data collection, strong normalization, broad and balanced coverage, clear lineage, and controlled access. These choices reduce risk before algorithms ever enter the picture and support fair AI practices that leaders can actually trust.
In this article, we break down five lessons from JobsPikr’s approach to responsible data and data ethics AI. Each lesson shows how responsible data decisions directly enable fair AI use in people analytics and workforce intelligence, without slowing innovation or compromising scale.
If you are an AI, analytics, or innovation leader trying to build intelligent systems people believe in, this is where the work really starts.
What is responsible AI, and why does responsible data decide whether it works
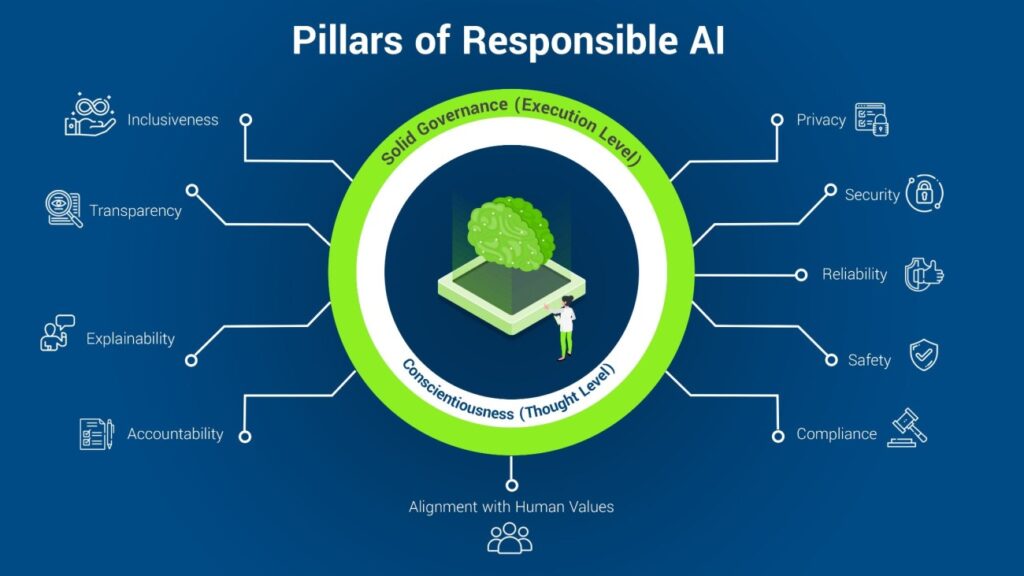
If you have ever watched a team try to “be responsible” with AI after they have already shipped something, you know how it goes.
The model is live. The dashboard looks impressive. Then a senior leader asks a simple question in a review: “Why is this trend suddenly up 30%?”
And the room gets quiet.
Because the uncomfortable answer is usually not, “The model is wrong.” It’s, “We are not fully sure what the data is doing today.” Maybe a source changed. Maybe duplicates spiked. Maybe one region is overrepresented. Maybe job titles were parsed differently this week. The model is just sitting on top of the mess, reflecting it back with confidence.
That’s the heart of this topic. Responsible AI is not something you sprinkle on later with a bias audit and a policy doc. If the data is shaky, the AI will be shaky. If the data is unfair, the AI will learn unfair patterns. If the data is hard to explain, the AI will be hard to defend.
Responsible AI is about whether you can stand behind the output
When people ask what is responsible AI, they often jump to fairness tests or explainability tools. Those matter, but the real test is more basic.
Can you use the output to make a decision that affects people, budgets, or strategy, and not feel like you’re gambling?
A lot of AI systems fail that test in quiet ways. The results look plausible, but they are not stable. A signal appears, disappears, reappears. Two teams pull the “same” metric and get different answers. Stakeholders start treating the system like a nice-to-have instead of a source of truth.
This is where trust gets lost. Not in a scandal. In a slow drip of small inconsistencies.
And that is why responsible AI ends up being less about model sophistication and more about whether the system behaves like something you can rely on.
The data makes the biggest decisions before the model ever shows up
Here’s the part people underestimate: the model does not get to choose what reality looks like. Your data does.
Someone decides which sources count. Someone chooses how far back history goes. Someone decides whether reposted jobs are treated as fresh demand or noise. Someone decides what happens to incomplete records. Someone decides how to standardize job titles, skills, locations, and company names, or not to.
None of that feels like “AI work” in the moment. It feels like data plumbing. But those choices shape what the AI learns as normal.
So when we talk about fair AI practices or fair AI use, we cannot pretend it starts at training time. It starts when you define the dataset and the rules around it.
Data governance is what turns “data ethics” from a slogan into something real
Most teams don’t lack good intent. They lack repeatability.
If you ask, “Where did this data come from?” you might get a vague answer. If you ask, “How often does it refresh?” you might get three different answers depending on who you talk to. If you ask, “Can we trace this insight back to source?” you might get a screenshot instead of lineage.
That’s not a morality problem. That’s a governance problem.
And without governance, “data ethics AI” becomes hard to practice consistently. You can have the best responsible AI principles on paper, and still end up with an AI system that is impossible to explain when someone challenges it.
Where data ethics shows up when nobody is calling it “ethics”
Data ethics is not always a dramatic debate about what you should or should not use. More often, it shows up as small calls teams make under deadline pressure.
Do we keep these records even though they’re messy, because we need coverage? Do we discard them, knowing that discarding might bias the dataset toward cleaner sources? Do we allow broad access so teams can move faster, or tighten access because misuse is a real risk? Do we keep old data because it looks “rich”, or remove it because it creates misleading trends?
This is the stuff that decides whether responsible AI is real in practice.
JobsPikr’s approach to responsible data is built around that reality. The goal is not just to have more labor market data. The goal is to have data you can explain, defend, and trust. Because once you do, responsible AI stops feeling like a compliance exercise and starts feeling like a reliable way to make decisions.
Build responsible AI on data you can stand behind
Let’s talk about building AI-ready, responsible labor market data you can rely on.
Why responsible data matters more than model performance in real AI systems
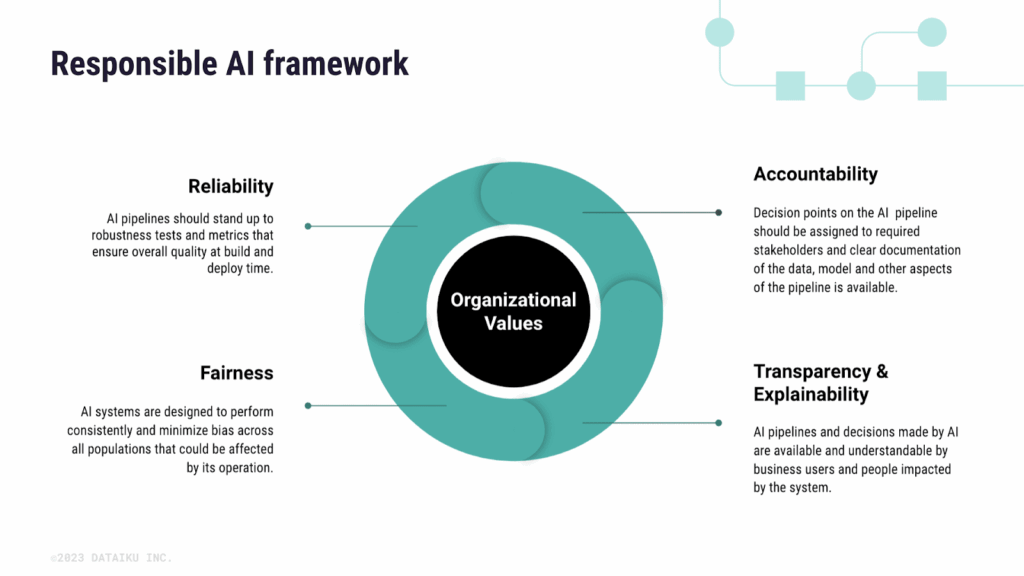
Image Source: knowledge.dataiku
There is a reason so many AI projects stall after the demo phase. The model works. The charts look good. But when it is time to rely on the output for something real, hiring plans, budget decisions, workforce strategy, people hesitate.
That hesitation usually has very little to do with model performance.
It has everything to do with whether the data underneath feels solid enough to trust.
AI learns patterns, not context, and that is where risk creeps in
AI systems are very good at spotting patterns. They are not good at understanding why those patterns exist.
If certain roles appear to be in high demand because one job board reposts aggressively, the AI will treat that as real demand. If one region dominates the dataset because it is easier to collect from, the AI will assume that region matters more. If older job postings linger in the data, the AI will quietly mix yesterday’s reality with today’s.
From the model’s point of view, everything looks valid. From a business point of view, the insight may already be off.
This is why responsible AI cannot rely on “smart models” alone. Without responsible data, AI systems confidently repeat distortions they do not understand.
The same model can produce fair AI or unfair AI depending on the data
This part is uncomfortable, but important. You can take the same algorithm and point it at two different datasets, and end up with completely different outcomes.
One dataset might be balanced across industries, regions, and company sizes. Another might lean heavily toward a few large employers or specific geographies. The model does not know the difference. It will optimize for whatever it sees most often.
That is how unfair AI often sneaks in. Not through malicious intent, but through uneven data coverage.
When people talk about fair AI practices, this is what they are really talking about. Making sure the data reflects reality broadly enough that the AI does not mistake convenience for truth.
The cost of getting data wrong is higher than model failure
A model that underperforms can usually be retrained. A dataset that people no longer trust is much harder to recover from.
Once leaders start questioning the data, every output becomes suspect. Teams begin double-checking results manually. Dashboards stop being used for decisions and start being used for reference only. Eventually, the system becomes shelfware.
That loss of confidence carries real costs.
Fixing problems after deployment is slow and expensive
If bad data reaches production, fixing it is not just a technical task. You have to identify the issue, correct the pipeline, reprocess historical data, and explain why past decisions might need rethinking. That work compounds quickly, especially when AI outputs are already embedded in workflows.
Trust, once lost, does not bounce back easily
Even after the data is fixed, skepticism lingers. Stakeholders remember the time the insight was wrong. They remember the awkward meeting where no one could explain a number. That memory shapes how much influence the AI system has going forward.
Data issues attract attention regulators and auditors care about
As AI use grows, so does scrutiny. When questions come in about fairness, explainability, or decision logic, weak data foundations are exposed fast. What looked like a small data shortcut early on turns into a governance issue later.
Why “we will fix bias later” rarely works in practice
There is a comforting idea that bias can be addressed once the model is live. Add a fairness check. Run a bias audit. Adjust weights. In reality, this approach almost always disappoints.
By the time bias is visible at the model level, it is usually baked into the dataset itself. Certain roles are underrepresented. Certain regions dominate. Certain patterns reflect outdated market behavior. You can smooth the edges, but you cannot fully undo the shape of the data.
This is why responsible AI starts with responsible data. Not because it sounds principled, but because it is the only stage where many risks can actually be prevented.
When data is collected carefully, structured consistently, and governed clearly, AI systems become easier to trust. And trust, more than raw performance, is what decides whether AI is used or quietly ignored.
Lesson 1: Data ethics starts with how you collect data, not how you use it later

Image Source: AIHR
Most responsible AI conversations jump straight to usage. How is the data being analyzed. Who can see the output. What decisions are made from it. Those questions matter, but they miss the first and most important step.
How the data is collected sets the ceiling for everything that follows.
If data collection is careless, opaque, or ethically fuzzy, no amount of downstream governance will fully fix it. Responsible data starts much earlier than most teams are comfortable admitting.
Public data is not the same as ethical data
There is a common shortcut in AI projects. If data is publicly available, it is treated as automatically safe to use.
That assumption causes problems.
Public does not always mean intended for large-scale aggregation. It does not mean the context of the data is preserved. It does not mean usage aligns with how the data was originally shared. When these nuances are ignored, data ethics quietly erodes even if no rules are technically broken.
Responsible AI requires a more careful lens. Teams need to ask not just “Can we collect this?” but “Should we collect this, and under what conditions?”
Responsible AI starts by being honest about data provenance
One of the fastest ways to lose trust in AI systems is when no one can clearly explain where the data came from.
Provenance matters because it sets expectations. Leaders interpret insights differently when they know whether the data reflects direct employer postings, reposted listings, aggregated feeds, or historical archives. Without that clarity, AI outputs feel like black boxes even when the model itself is explainable.
This is a core principle of data ethics AI. Transparency about sourcing is not a legal detail. It is what allows users to judge fitness for use.
JobsPikr’s approach to responsible data sourcing in labor market intelligence
JobsPikr’s approach to responsible data starts with restraint. The goal is not to collect everything possible, but to collect data in ways that can be explained, defended, and sustained over time.
That means respecting platform boundaries, focusing on legitimate job posting sources, and being clear about what the data represents and what it does not. It also means building systems that track source context instead of stripping it away for convenience.
This approach supports responsible AI by ensuring that downstream insights are grounded in data with known origins and limitations.
Why transparency in collection builds long-term trust
Transparency may feel like friction at first. It forces teams to document sources, clarify assumptions, and sometimes say no to questionable data.
Over time, it pays off.
When questions arise about fairness, bias, or unexpected trends, transparent data collection makes investigation possible. Stakeholders can trace insights back to source behavior instead of guessing. That confidence carries through to AI adoption.
Responsible data collection is not about being cautious for its own sake. It is about making sure AI systems are built on foundations people are willing to stand behind when decisions matter.
If data ethics is ignored at the collection stage, responsible AI becomes reactive. When it is built in from the start, responsible AI becomes much easier to practice.
Lesson 2: responsible AI needs standardized data because messy data creates unfair outcomes
Data rarely arrives in a neat, comparable form. Especially in labor market intelligence, the same role can be described ten different ways, locations can be vague or inconsistent, and company names can blur across brands, subsidiaries, and abbreviations. None of this looks dangerous on its own. Together, it creates a quiet problem.
When data is not standardized, AI systems start comparing things that are not actually comparable. That is where unfair outcomes creep in, even when intentions are good.
Unstructured job data introduces bias through inconsistency
Consider something as simple as a job title. “Software Engineer,” “Backend Developer,” “Full Stack Engineer,” and “SDE II” might all refer to similar roles. If these are treated as separate categories, AI systems will split demand, skills, and salary signals across multiple buckets.
The result is distorted insight. One role looks scarce when it is not. Another looks overrepresented because of naming habits, not market reality. AI does not know that these labels overlap. It assumes they describe different worlds.
This is how messy data quietly produces unfair AI behavior. Certain roles, regions, or employers appear stronger or weaker simply because their data happens to be cleaner or more consistent.
Normalization turns raw listings into comparable, auditable records
Standardization is the work of turning variation into structure without erasing meaning. It is not about flattening reality. It is about making comparison possible.
When job titles are normalized, AI can see true demand patterns instead of naming quirks. When locations are standardized to consistent geographic levels, regional insights stop swinging wildly based on formatting differences. When companies are resolved correctly, hiring activity reflects real organizations instead of fragmented aliases.
This is one of the most practical ways responsible data supports responsible AI. It reduces accidental bias caused by inconsistency and allows AI systems to reason over data more fairly.
Why standardization supports fair AI practices in people analytics
People analytics relies on comparison. Trends over time. Differences across regions. Shifts between industries. None of that works if the underlying data changes shape every time it is collected.
Without standardization, AI systems may produce precise-looking outputs that are fundamentally misleading. Leaders see numbers with decimal points and confidence intervals, but the foundation underneath is unstable.
Standardized data creates a shared frame of reference. It ensures that when AI surfaces a difference, that difference reflects the market, not the formatting of the data.
How responsible data design prevents false precision in AI outputs
One of the most dangerous things AI can produce is false precision. Outputs that look mathematically solid but are based on loosely defined inputs.
Responsible data design reduces this risk. It forces clarity around what is being compared and why. It makes assumptions explicit instead of hiding them inside transformations.
JobsPikr’s approach treats standardization as a responsibility, not a preprocessing step to rush through. By investing in structured, consistent labor market data, AI systems downstream become easier to explain, easier to audit, and less likely to reinforce accidental bias.
Fair AI practices depend on this kind of groundwork. Without it, even well-meaning AI systems can end up amplifying noise instead of insight.
Build responsible AI on data you can stand behind
Let’s talk about building AI-ready, responsible labor market data you can rely on.
Lesson 3: Fair AI practices start with coverage and representation at the data layer
Bias in AI is often described as a model problem. In reality, it is usually a visibility problem. What the system sees, and just as importantly what it does not see, shapes every output that follows.
If large parts of the market are missing or underrepresented in the data, AI systems will confidently generalize from an incomplete picture. That is how unfair AI behavior emerges without anyone explicitly building it in.
Most bias problems are coverage problems disguised as model problems
When teams discover bias in AI outputs, the first instinct is to look at the algorithm. But many of these issues trace back to uneven data coverage.
If certain industries post jobs more frequently online, they dominate the dataset. If certain regions rely on informal hiring channels, they barely show up. If smaller companies post inconsistently, their signals get drowned out by large employers with automated posting systems.
The AI is not biased in intent. It is responding to what it sees most often. That distinction matters, because it changes where fixes should happen.
Responsible data means thinking about who is missing, not only who is included
Responsible data is not just about volume. It is about balance.
Teams often ask, “Do we have enough data?” A more useful question is, “Whose data do we have, and whose are we missing?” Gaps in representation can quietly skew insights, especially in people analytics where decisions affect real careers and livelihoods.
JobsPikr’s approach emphasizes breadth across roles, regions, and employer types so that AI systems do not confuse posting frequency with importance. This kind of representation work is unglamorous, but it is foundational to fair AI practices.
How JobsPikr reduces bias exposure through breadth, validation, and monitoring
Reducing bias at the data layer is not a one-time exercise. It requires continuous attention.
JobsPikr focuses on broad source coverage, regular validation checks, and ongoing monitoring to catch imbalances as they emerge. Labor markets shift, platforms change behavior, and posting patterns evolve. Responsible data practices have to move with them.
This ongoing work helps ensure that AI systems built on top of the data are learning from the market as it is today, not a distorted snapshot from months ago.
Why “more data” can increase risk when quality controls are weak
There is a temptation to believe that scale alone solves bias. Collect enough data and the problem will average out.
In practice, the opposite often happens.
Duplicates and reposting inflate demand signals
When the same job is reposted across platforms or refreshed repeatedly, demand can appear stronger than it really is. Without careful de-duplication, AI systems learn exaggerated patterns.
Source imbalance skews what AI treats as normal
If a few high-volume sources dominate the dataset, their behavior sets the baseline. Smaller or less visible markets fade into the background, even if they matter strategically.
Stale records create misleading trends
Old postings that linger in the data blur current signals. AI systems struggle to distinguish active demand from historical noise unless freshness is actively managed.
Responsible data practices recognize that coverage and representation are ongoing responsibilities. Fair AI does not emerge automatically from scale. It emerges from deliberate choices about what the data should represent and how closely it reflects reality.
When representation is handled thoughtfully at the data layer, AI systems become less likely to reinforce blind spots and more capable of supporting decisions people can defend.
Lesson 4: Responsible AI requires secure data access because misuse is part of the threat model
Security is one of those topics everyone agrees with in theory, and then ignores in practice until something breaks.
Not always in a dramatic way, either. Most of the time, nothing gets “hacked.” Instead, the AI system slowly loses credibility because the data gets copied, sliced, merged, and re-used in ways nobody can track properly.
And once that happens, responsible AI becomes very hard to defend. Because you are not just defending a model. You are defending the chain of decisions behind the data.
Data security is not just compliance, it is what keeps AI outputs consistent
Here is a pattern you have probably seen.
Team A pulls the dataset and builds a dashboard. Team B exports the same dataset for a quick analysis. Team C grabs a slightly older dump because it was easier to access. Someone changes a few filters, drops a few columns, renames fields, and saves it as “final_v3.”
Three weeks later, leadership asks a basic question: “Why does this metric not match what we saw last month?”
Nobody is trying to mislead anyone. The problem is simpler and worse. There is no single, controlled path for how data is accessed and reused. The AI output might be “accurate” for the version someone used, but that is not the same as being reliable for the business.
Responsible data access solves this. Not because it is strict, but because it prevents accidental version chaos, which is one of the fastest ways to kill trust.
Uncontrolled access creates AI risk even when everyone has good intentions
When people hear “misuse,” they imagine bad actors. In reality, most misuse comes from speed.
Someone needs an answer today, so they export a file. Someone merges it with another dataset without fully understanding how the fields differ. Someone trains a model on a filtered slice and forgets to document the filter. Someone shares the data with a partner without the right context and assumptions.
None of these steps look like a breach. But they can lead to the same outcome: AI outputs that are hard to explain, hard to reproduce, and easy to misinterpret.
That is not a theoretical risk. It is exactly how teams end up with AI systems that look impressive but cannot be trusted in decision meetings.
Governance is how you move fast without breaking trust
Governance gets a bad reputation because people imagine long review cycles and locked doors. Good governance is the opposite. It makes work faster because it reduces confusion.
When access is role-based, when definitions are clear, when sources are traceable, teams spend less time arguing about which number is correct. They stop rebuilding the same analysis from scratch. They stop treating data like a personal stash.
This is where responsible AI becomes practical. Not because governance feels “ethical”, but because it makes outputs repeatable. Repeatability is what leaders trust.
Responsible data handling protects the people using the AI, not just the data itself
One more thing that gets missed: secure access is not only about protecting data. It protects the people using it.
If a leader makes a workforce decision based on an AI insight, they need to know that insight came from a governed pipeline, not a random export that has been passed around a few times. If an analyst presents an AI-driven trend, they need confidence they can defend it if questioned.
Responsible AI is not only about what the system produces. It is about whether the people relying on it can stand behind it without crossing their fingers.
That is why JobsPikr’s approach treats secure, controlled access as part of responsible data, and responsible data as the foundation for responsible AI. You cannot build trust on top of a dataset that anyone can reshape without anyone noticing.
Lesson 5: Transparency is not a feature; it is the backbone of responsible AI

Image Source: zendesk
Transparency in AI often gets treated like a nice-to-have. Something you add once the system is working. A tooltip here, an explanation panel there. That approach misses the point.
If people do not understand where an insight comes from, they do not trust it. And if they do not trust it, they stop using it, no matter how advanced the AI looks on paper.
Transparency is not about making AI look good. It is about making AI usable.
Explainable AI breaks down quickly without explainable data
A lot of explainability efforts focus on the model. Feature importance charts. Confidence scores. Model cards. Those tools help, but they only go so far.
At some point, someone asks a more basic question. “What data is this based on?” If the answer is vague or overly technical, confidence drops immediately.
You cannot explain an AI output if you cannot explain the data behind it. Where it came from. How recent it is. What was included. What was filtered out. Without that context, explanations feel incomplete, even if they are technically accurate.
Responsible AI depends on explainable data first. Model explainability only works when the data story is clear.
What data lineage actually means when you are not an engineer
Data lineage sounds like an intimidating term, but the idea is simple. It is the ability to trace an insight back to its source.
When someone looks at a workforce trend, lineage answers questions like: Which job postings contributed to this signal? What time period does it cover? Which sources were included? Has anything changed since the last time we ran this analysis?
Without lineage, AI outputs feel like magic. With lineage, they feel grounded.
This matters even more in people analytics and labor market intelligence, where insights influence hiring plans, compensation strategies, and long-term workforce decisions. Leaders do not just want an answer. They want to understand its footing.
Why traceability changes how leaders trust AI
Trust does not come from knowing that an AI model is “state of the art.” It comes from being able to defend a decision when someone asks why.
When leaders can trace an insight back through the data, they are more comfortable acting on it. They can explain it to their teams. They can justify it to stakeholders. They can spot when a result looks off and investigate without starting from scratch.
This is where transparency becomes a real advantage. It turns AI from a black box into a decision support system people are willing to rely on.
How JobsPikr aligns transparency with intelligence and trust
JobsPikr’s approach to responsible data emphasizes context, not just output. Labor market insights are tied to source behavior, timeframes, and structured metadata so users can understand what they are seeing and why.
This transparency does not slow analysis down. It speeds up adoption. When users trust the foundation, they stop second-guessing every result.
Responsible AI is not about revealing every technical detail. It is about giving people enough clarity to use insights responsibly and with confidence. Transparency at the data level makes that possible.
Without it, even well-built AI systems struggle to earn trust. With it, AI becomes something people can explain, defend, and actually use.
Build responsible AI on data you can stand behind
Let’s talk about building AI-ready, responsible labor market data you can rely on.
Where responsible AI shows up in people analytics and workforce decisions
Responsible AI can feel abstract until it starts touching decisions that affect real people. That is exactly where people analytics and workforce intelligence sit. Hiring plans, skills strategy, compensation benchmarks, location decisions. These are not hypothetical use cases. They shape careers and budgets in very visible ways.
That is why this space feels the impact of irresponsible data faster than most others.
Why people analytics teams feel AI risk before anyone else
People analytics teams live in the uncomfortable middle. They sit between messy real-world data and leaders who want clear answers.
When AI-driven insights are wrong, unclear, or hard to explain, these teams are the first to feel the pressure. A head of HR asks why a role suddenly looks scarce. A finance leader questions a compensation signal that does not align with last quarter. A recruiter wonders why demand appears high in a region they are not seeing activity in.
In these moments, the problem is rarely the math. It is whether the data foundation is strong enough to support the conclusion. Responsible data gives people analytics teams something solid to stand on when those questions come up.
How responsible data reduces harm in hiring and workforce planning
Small data issues can create outsized consequences in workforce decisions.
If AI overstates demand for certain roles, organizations may overhire in one area and underinvest in others. If regional data is skewed, leaders may open offices in the wrong markets or miss emerging talent hubs. If historical bias is baked into the dataset, AI recommendations can quietly reinforce outdated hiring patterns.
Responsible data helps reduce these risks by making sure AI systems reflect the labor market as it actually is, not as it happens to appear in a narrow slice of data. This is what fair AI use looks like in practice. Not perfection, but fewer blind spots and fewer confident mistakes.
What fair AI practices look like when decisions need to be explained
Fair AI is not just about avoiding bias in outputs. It is about being able to explain how a conclusion was reached.
In workforce settings, explanations matter. Leaders want to know why a role is flagged as critical. Why a skill is trending. Why a market looks competitive. They want to understand whether the insight reflects real demand or a data artifact.
Responsible data makes these conversations possible. When the data is transparent, standardized, and well-governed, AI outputs come with context. That context is what allows teams to use insights responsibly instead of treating them as unquestionable truths.
How responsible data prevents confident but wrong recommendations
One of the most dangerous failure modes of AI is confidence without grounding. Outputs that look precise, come with charts and percentages, and feel authoritative, but are based on shaky inputs.
Responsible data acts as a brake on that behavior. It forces clarity around what the AI actually knows and what it does not. It limits overreach. It makes uncertainty visible instead of hiding it behind numbers.
JobsPikr’s approach to responsible data is designed with this reality in mind. The goal is not to replace human judgment, but to support it with intelligence that leaders can trust, question, and defend.
In people analytics and workforce decisions, that trust is not optional. It is what separates AI that informs decisions from AI that quietly gets ignored.
A practical way to sanity-check your responsible AI and responsible data posture
Most teams do not need another framework to tell them whether they are doing responsible AI “right.” What they need is a way to pause and check whether the foundations they are building on are actually solid.
This is less about scoring yourself and more about noticing friction. Responsible data problems usually show up as hesitation, workarounds, or quiet doubt long before they turn into visible failures.
The questions leaders should be able to answer without scrambling
A simple test is how easily your team can answer basic questions about the data behind your AI outputs.
If someone asks where a signal came from, how current it is, or what was excluded, do you get a clear answer or a chain of guesses. If two teams look at the same metric, do they trust they are seeing the same thing. If an output looks off, can someone trace it back and explain why.
When these answers require a long Slack thread or a meeting to “align,” it is usually a sign that responsible data practices are still immature.
Signals that your data ethics approach is weaker than your AI ambitions
There are a few patterns that show up again and again when teams move too fast on AI without strengthening their data layer.
One is overconfidence in volume. “We have a lot of data” becomes a substitute for understanding coverage and representation. Another is reliance on manual fixes. Analysts quietly correcting outputs they do not trust, instead of addressing why the system produced them in the first place.
A third signal is avoidance. Teams stop asking hard questions about fairness, freshness, or provenance because the answers are uncomfortable or time-consuming to uncover. That is usually where risk is already building.
What “good” looks like when you want responsible AI without slowing teams
Responsible AI does not mean locking everything down or adding weeks of review. In fact, strong data foundations tend to make teams faster.
When data sources are clear, definitions are shared, and access is intentional, people spend less time debating numbers and more time using them. When lineage exists, investigations are quicker. When governance is built into the pipeline, not layered on top, responsibility becomes part of normal work instead of a separate process.
This is the balance JobsPikr aims for. Responsible data that supports intelligent, confident use of AI, not data ethics that lives in a document no one opens.
If your AI systems feel impressive but fragile, this kind of sanity-check is often the fastest way to see why.
Building responsible AI that people actually trust over time
Responsible AI does not fail because teams do not care enough. It fails because the hard work happens in places that are easy to overlook. Data collection choices. Normalization decisions. Coverage gaps. Access controls. Lineage. None of these feel exciting compared to training a model or launching a new dashboard. But they are what decide whether AI systems hold up when real decisions are on the line.
JobsPikr’s approach is grounded in that reality. Responsible AI starts with responsible data, not as a principle, but as a practical necessity. When data is collected ethically, structured consistently, governed clearly, and explained transparently, AI becomes something people can rely on instead of something they cautiously double-check.
For AI, people analytics, and innovation leaders, this is where trust is built. Not after deployment. Not during audits. But long before, in the quiet decisions that shape the data itself. When those decisions are made deliberately, responsible AI stops being a promise and starts becoming a habit.
Build responsible AI on data you can stand behind
Let’s talk about building AI-ready, responsible labor market data you can rely on.
FAQs:
What is responsible AI in simple terms?
Responsible AI is about whether you feel comfortable using an AI system for real decisions. Not demos. Not experiments. Real calls that affect people, money, or strategy.
If an AI system gives you an answer and your first reaction is “I hope this is right,” something is missing. Responsible AI is when you understand where the answer came from, what it’s based on, and where it might be wrong. That confidence usually has less to do with the model and more to do with the data behind it.
What is responsible data and how is it different from data quality?
Data quality is about whether the data is accurate and up to date. Responsible data asks a wider set of questions.
Where did this data come from? Why was it collected this way? What does it represent well, and what does it not represent at all? Who can access it, and what are they allowed to do with it?
You can have clean, accurate data that still causes problems if those questions are never answered. Responsible data makes sure people understand the limits of what the data can safely be used for, especially when AI is involved.
How do data ethics and data ethics AI affect real AI outcomes?
Data ethics sounds abstract until you see its impact. It shows up when an AI system keeps recommending the same roles, regions, or companies because that’s what dominates the data. It shows up when trends look convincing but don’t match what teams are seeing on the ground.
Those outcomes are not usually caused by bad intent. They come from data that was collected, filtered, or reused without enough thought. Data ethics AI is really about slowing down just enough at the data stage so AI doesn’t confidently learn the wrong lessons.
What do fair AI practices look like in people analytics and workforce intelligence?
In this space, fair AI is less about perfect neutrality and more about avoiding blind spots.
It means making sure one region is not treated as “the market” just because it posts more jobs online. It means not letting messy job titles distort demand signals. It means being able to explain why a skill looks important instead of just pointing at a chart.
Fair AI practices give leaders insights they can question and still use, instead of outputs that look impressive but feel risky.
How can organizations move toward responsible AI without slowing innovation?
Most teams slow themselves down by fixing problems late.
When data foundations are weak, people spend time rechecking numbers, rebuilding analyses, and explaining inconsistencies. That is what really kills momentum. Responsible data practices do the opposite. They reduce rework.
Clear sourcing, basic governance, and simple lineage make AI systems easier to reuse and easier to trust. When teams stop second-guessing the data, they move faster, not slower.




