
- **TL;DR**
- Why Data Bias Quietly Shapes Every AI Hiring Decision
- See how structured job data reduces bias at the source
- How Responsible AI Starts Before the Model
- Understanding Data Bias in Job Postings
- See how structured job data reduces bias at the source
- What 100 million Job Posts Taught us About Dataset Curation and Data Bias Reduction
- How to Design a Bias-Resistant Dataset using Structured Job Postings
- Real-World Patterns: Where We See the Strongest Bias in Job Data
- How Responsible AI Teams Use Dataset Signals to Reduce Bias Before Modeling
- Building Operational Quality Controls for Large-Scale Job Post Datasets
- Long-Term Bias Reduction Depends on the Dataset You Build, not the Model You Train
- See how structured job data reduces bias at the source
- FAQs
**TL;DR**
Most teams assume data bias shows up only at the model stage, but the truth is that it begins much earlier. Bias creeps in through the job postings you collect, how you clean them, how you normalize titles, which locations end up overrepresented, and which roles dominate your dataset. When you are working with millions of job posts, even small structural gaps can distort patterns that downstream AI systems rely on.
This article breaks down what we learned while structuring one hundred million job posts, why certain types of data bias consistently appear, and how responsible AI teams can reduce bias long before training a model. You will learn why duplicate postings mislead trend signals, how gender coded language slips into text data, why location skew can create false assumptions about talent availability, and how careful dataset curation is the only path to a bias-resistant dataset.
If you work in DEI, responsible AI, workforce analytics, or compliance, this will give you a practical playbook for turning messy job post data into a reliable foundation for fairness-focused AI systems.
Why Data Bias Quietly Shapes Every AI Hiring Decision
If you have ever worked with job data at scale, you already know that most problems do not start with the model. They start with the inputs. Job postings look simple at first glance. A title, a description, a location line, maybe a salary range. Once you stack millions of them together, you realise something important. The data is not neutral.
It carries the habits and blind spots of the people and organisations that wrote those postings. That includes how they describe roles, which locations they hire in, what they expect from candidates, and how inclusive their language really is.
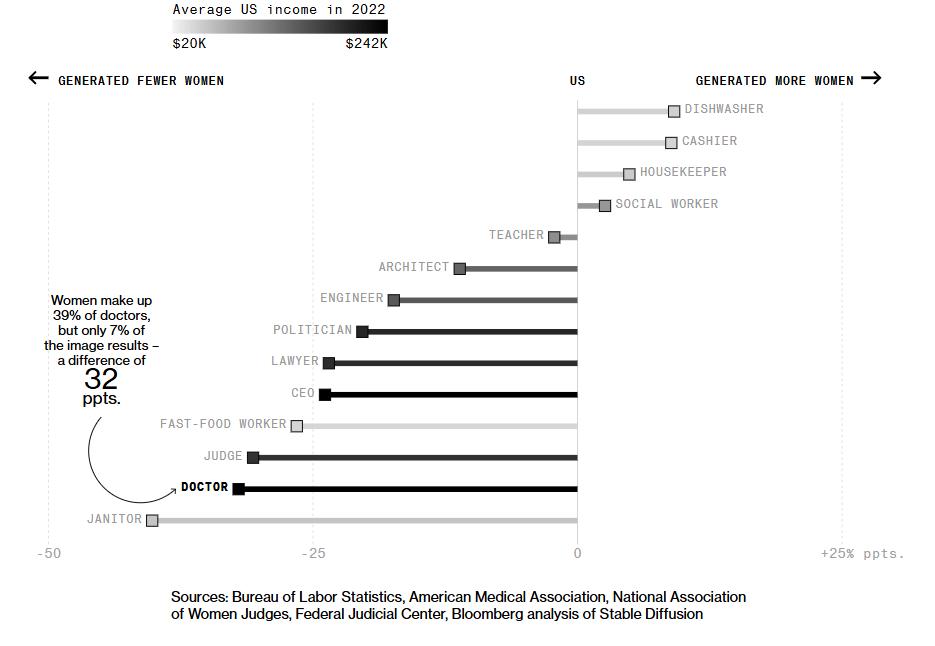
Image Source: Bloomberg
How job postings quietly introduce data bias
Job postings bring in data bias in more ways than people expect:
- Language patterns become statistical patterns.
If engineering roles in your dataset are full of words like “dominant”, “aggressive” and “rockstar”, a model starts to treat that tone as normal. Over time, gender coded language becomes part of the background noise in your data instead of a red flag that needs attention.
- Location skew narrows the perceived talent pool.
When most of your job posts come from a few large metro cities, your dataset tells the model that talent mostly lives there. That is often not true. It is simply where companies post the most roles. The model then mirrors this skew, which can influence any AI system that predicts hiring demand or talent availability.
- Industry and seniority bias shape “default” expectations.
Some industries write long, detailed job descriptions. Others post short, vague ones. If one industry dominates your dataset, its style and norms become the default. Models trained on that mix can overfit to those patterns, which is a subtle form of data bias that is easy to miss.
See how structured job data reduces bias at the source
Start improving fairness and data quality before you ever train a model.
How Responsible AI Starts Before the Model
This is why responsible AI teams spend so much time on data bias reduction and dataset curation, not just on algorithms. A model trained on biased inputs will scale that bias with a clean API and a nice dashboard. It may look impressive, but it quietly reinforces unfair patterns in hiring, compensation insights, or workforce planning.
A clean job dataset is important. A bias-resistant dataset is critical. The more we worked with job postings at the scale of tens of millions, the clearer this became. If you only start thinking about bias after the model is built, you are already late. The structure, coverage, and language of the dataset make most of the difference.
Why 100M job posts are such a useful reality check
Working with one hundred million job posts forces you to confront how often bias in job postings appears, and how easy it is to ignore it on a small scale. You see which roles are overrepresented, which locations barely show up, and which industries dominate the feed. You notice how often fields like salary, level, and employment type are missing or inconsistent.
If you are building pipelines for DEI dashboards, pay equity audits, hiring trend analysis, or bias detection in AI job postings, your real asset is the dataset. Everything else in your stack, including sophisticated models, sits on top of it. The more intentional you are about the structure and fairness of that dataset, the more trustworthy your AI outcomes become.
Understanding Data Bias in Job Postings
When people talk about bias in AI, they usually jump straight to the model. In reality, data bias often starts much earlier, inside the job postings that feed those models. The way roles are described, which companies publish the most, which locations are overrepresented, and who the language implicitly “invites in” all shape how an algorithm sees the labour market.
If the dataset is skewed, the model will be skewed. It is that simple.
Job postings are not just text fields. They are signals about who is wanted, where, and on what terms. That makes them powerful and risky at the same time.
How data bias shows up inside job postings

Image Source: RallyYou can think of data bias in job postings as a few recurring patterns that show up again and again.
Representation bias: Certain industries, regions, and company sizes post far more roles than others. Large tech hubs, for example, publish thousands of openings each week, while smaller cities or sectors remain relatively quiet. Your dataset then starts to act as if “real” hiring only happens in those noisy regions or high-posting industries.
Language bias: Research has shown that job ads can subtly discourage certain groups from applying through gender coded language. One well-cited study in the Journal of Personality and Social Psychology found that masculine-coded wording in job ads reduced women’s sense of belonging and interest in applying. That same wording did not have the same effect on men. When millions of postings carry that language forward, it turns into measurable bias in the text layer of your data, not just a one-off copywriting issue.
Structural bias: This shows up in missing salaries, unclear seniority levels, vague responsibilities, or over-inflated requirements for junior roles. If only some employers disclose pay ranges, or if some sectors consistently label mid-level roles as “senior,” your dataset starts misrepresenting what the market actually looks like.
Why biased job data leads to biased AI hiring systems
Once this biased data feeds into downstream systems, the problems multiply.
Imagine you are building an AI model to forecast hiring demand or to recommend candidate profiles to recruiters. If your dataset overrepresents a handful of metros, the model may suggest that those are the only sane places to hire. If gender bias in job postings is baked into the language, a model that is trained on that text may learn to associate certain words, skills, or titles with a particular gender, even if you never give it demographic labels.
The risk is not only that AI systems repeat harmful patterns. It is that they do it with confidence, speed, and scale. A human recruiter with biased instincts might review a few dozen CVs in a week. A biased model can influence thousands of recommendations and screening decisions in the same time.
For responsible AI teams and DEI leaders, this changes the task. It is not enough to monitor outcomes or tweak model thresholds. You need a dataset curation strategy that identifies and reduces data bias at the source, particularly in job posts.
Why job posts are such a sensitive input for DEI and compliance
Job postings sit at the intersection of brand, compliance, and DEI. They shape who feels welcome to apply, who sees a role as “for people like me,” and who decides to pass. From a data perspective, they also form a big slice of the training and benchmarking material for:
- Inclusive language detection
- Compensation benchmarking and pay equity analytics
- Workforce planning and role mapping
- Skills-based hiring and mobility models
If that foundation is biased, every insight on top of it becomes less trustworthy.
This is why responsible AI leaders and DEI teams are now treating data bias reduction in job postings as a core part of their data infrastructure work, not just a one-time cleanup exercise. Instead of asking “Is the model fair?”, the better question is “Is the dataset we are feeding into the model structurally fair, representative, and well curated?”
In the next section, we will shift from the theory to the practice and look at what structuring 100 million job posts actually taught us about data bias, dataset curation, and what needs to change upstream before you ever train a model.
See how structured job data reduces bias at the source
Start improving fairness and data quality before you ever train a model.
What 100 million Job Posts Taught us About Dataset Curation and Data Bias Reduction
Working with a few thousand job postings can hide a lot of structural bias. Working with one hundred million removes the illusion. At that scale, patterns become painfully clear. You start to see the same issues repeat across industries, continents, job boards, and company sizes. And more importantly, you see how those issues distort any AI system trained on top of them.
This section walks through the biggest lessons we learned while structuring job post datasets at a massive scale. These are not abstract principles. They are the real problems that show up when millions of postings flow into a pipeline every week.
Lesson 1: Large volume does not cancel out bias unless the structure is intentional
There is a common assumption that big datasets are automatically more balanced. After processing job posts from thousands of companies, it became clear that this is not true. Volume often magnifies the loudest patterns.
For example, large enterprises publish far more roles than mid-sized or small companies. Certain sectors like technology, financial services, and healthcare dominate posting volume because they have higher turnover and more continuous hiring cycles. When their postings flood in, they drown out smaller industries, even if those smaller industries employ millions of workers.
If you do not structure your dataset around coverage rules and proportional sampling, your model will treat the loudest sectors as the most important ones. That is a form of data bias that creeps in quietly unless caught early.
Lesson 2: Duplicate and stale postings distort role demand and trend signals
At the scale of one hundred million posts, duplicates are unavoidable. The problem is not the existence of duplicates. The problem is what duplicates do to your dataset if left unchecked.
Companies often repost the same role across platforms, refresh it weekly, or publish multiple variations of the same listing. If those duplicates flow into your training data unfiltered, the model starts assuming inflated demand for certain roles. A senior data analyst position that appears twenty times because it was refreshed every week looks like twenty different opportunities. That heavily distorts trend analysis and demand forecasting models.
Stale postings have a similar effect. A listing that stays live long after the job is filled creates the illusion of ongoing demand. Without freshness checks, the dataset begins to drift away from reality. In our experience, the job boards with the highest posting volume also had the highest stale rate, so cleaning them became a full-time data quality requirement.
Lesson 3: Location and industry skew create misleading patterns about talent availability
Data bias becomes visible quickly when you map postings geographically. Some countries and regions publish large amounts of job posts because their labour markets have strong digital adoption. Others hire just as actively but post far fewer roles online. The result is a dataset that makes some regions appear talent-rich and others talent-poor, even when that is not the case.
Industry skew behaves the same way. Technology and finance generate more job postings per employer than education, manufacturing, agriculture, or public services. Not because they hire more people overall, but because their hiring processes are more digitised. Left uncorrected, this overrepresentation influences any AI system trained on role frequency, skills trends, or competitive demand.
When building a bias-resistant dataset, you cannot rely on posting volume alone. You need controls that ensure your dataset represents the market as it is, not the market as job boards make it appear.
Lesson 4: Missing fields and inconsistent formats weaken fairness and reduce model quality
The more job posts you ingest, the clearer it becomes that job postings are not standardised. One posting lists a salary range. Another leaves it blank. One includes detailed responsibilities. Another gives a three-line description that tells you nothing. One company uses clear titles; another calls a junior role a “Lead” or “Ninja.”
This inconsistency introduces structural bias. If certain industries consistently hide salary information, then pay equity models trained on the dataset will favour industries that disclose more. If seniority levels are written in unstructured ways, AI systems that rely on structured fields end up associating the wrong skill sets with the wrong levels.
Metadata gaps undermine fairness because the missing information is not random. It follows patterns. Some sectors hide pay more often. Some regions use informal titles more often. Some companies overstate requirements more often. These patterns, when captured at scale, turn into bias signals that models can absorb unless addressed through strong curation and enrichment.
Why these lessons matter for anyone building hiring or DEI-focused AI
Once you see these patterns at scale, it becomes clear that dataset curation is not just housekeeping. It is part of your fairness strategy. Responsible AI teams cannot rely on post-modeling corrections. You need a dataset architecture that handles bias upstream, long before the model ever learns from the data.
This is where structured job post datasets become essential. A well-curated dataset protects your downstream systems from absorbing structural and language-based bias that was never intended to shape your model in the first place.
How to Design a Bias-Resistant Dataset using Structured Job Postings
Bias detection sounds like a single task, but it is really a layered workflow. Job postings contain many different kinds of signals. Some are obvious, like gender coded words. Others are subtle, like a pattern of inflated requirements for junior roles or a habit of posting certain jobs only in specific cities. When you are working with millions of postings, you need methods that are accurate, scalable, and grounded in real research rather than guesswork.
Below are the three approaches that consistently work in large job post datasets.
Lexicon-based gender bias detection for job descriptions
Lexicon-based detection is one of the most reliable first steps because it uses established linguistic research. Academic studies have documented which words tend to signal masculine-coded and feminine-coded tones. These word lists were originally tested in controlled experiments where job seekers’ reactions were measured. One commonly cited study (Gaucher, Friesen, and Kay, 2011) found that masculine-coded wording reduced women’s interest in applying, even when the job itself was identical.
In practice, this method scans each posting for patterns of gender coded terms and calculates a score that reflects the level of language bias. If a posting contains terms like “assertive,” “dominate,” or “driven,” the score shifts toward masculine-coded language. Words like “supportive,” “interpersonal,” or “understand” shift it toward feminine-coded language.
The value of this approach is its transparency. When a posting is flagged, you know exactly which words triggered the alert. That makes it easier for DEI teams to rewrite the posting or guide hiring managers toward neutral language that does not unintentionally deter qualified candidates.
Machine learning classifiers for subtle bias in AI job postings
Lexicons are powerful, but they do not catch everything. Some industries use jargon that overlaps with bias-coded language. Others use phrasing that is not classically gendered, yet still contributes to exclusion. To detect these patterns, machine learning classifiers are used alongside lexicons.
Instead of relying on predefined word lists, these models learn from large corpora of job descriptions and human labelling. They identify signals like tone, sentence structure, and implied expectations that would be difficult to capture with simple lists. For example, an ML model may flag patterns such as:
- Inflated requirements for junior roles
- Overuse of hypercompetitive language
- Implicit bias in phrases like “must have perfect communication”.
- Patterns of urgency that correlate with specific industries or genders
These models help uncover the deeper layers of data bias in AI job postings that surface only when you look at millions of descriptions together. When combined with lexicon scoring, they create a more complete view of how language may unconsciously filter out certain groups.
Why human-in-the-loop review strengthens algorithmic checks
The most sophisticated bias detection still has gaps. Language is contextual. A term that signals bias in one industry may be neutral in another. A phrase that sounds exclusionary to one reader may be standard in a specific technical field. Because of this, human reviewers are essential.
Human in the loop review is not about manually reading thousands of job descriptions. It is about reviewing the edge cases – postings that were flagged with moderate or ambiguous scores. These cases often contain the most subtle forms of bias, such as:
- Requirements that are not aligned with the job level
- Salary ranges that contradict market data
- Descriptions that unintentionally exclude non-traditional career paths
- Tone that feels unwelcoming, even when the wording looks neutral
When humans and algorithms work together, bias detection becomes more reliable. Algorithms catch patterns humans cannot scale to. Humans catch nuance that algorithms cannot interpret accurately. This hybrid approach is what most responsible AI teams now rely on.
Why these methods matter for dataset curation and data bias reduction
Bias detection is not simply a fairness exercise. It is a data quality step. A dataset that contains unchecked bias creates unstable training signals for any AI system that uses it. Models trained on biased language interpret that bias as truth. They begin to internalise patterns from the text rather than patterns from the labour market.
By applying lexicon scoring, machine learning classifiers, and human review together, you create a cleaner, more stable representation of the job market. You remove distortions that would otherwise influence role clustering, skills analysis, salary predictions, and hiring insights.
Real-World Patterns: Where We See the Strongest Bias in Job Data
Once you analyse job postings at the scale of tens of millions, certain bias patterns become impossible to ignore. They show up across industries, continents, and job boards. These are not one-off anomalies. They are structural habits in how organisations write, publish, and maintain their postings.
Below are the three bias patterns that appear the most often and have the highest downstream impact on AI models and DEI analytics.
Gender coded language in tech, finance, and sales roles

Image Source: Careerplug
Gender bias in job postings is not evenly distributed. Some industries consistently use more masculine-coded language than others. In large-scale datasets, tech, finance, and sales roles often show the highest concentration of masculine-coded terms. Words like “aggressive,” “dominant,” “competitive,” and “rockstar” come up far more often in these sectors.
This matters because research shows that gender coded wording can influence who feels welcome to apply. A study published in the Journal of Personality and Social Psychology found that ads with masculine-coded language reduced women’s sense of belonging and interest in applying. When those patterns appear across thousands of postings, they quietly shape the dataset that AI systems learn from.
If a training dataset absorbs that tone, the model will treat masculine language as the norm for those job families. This can distort everything from skills clustering to candidate recommendation models, especially when the dataset is used to build AI tools for screening or matching.
Geographic bias caused by urban-centric hiring patterns
Another pattern that appears at a massive scale is location skew. Some regions publish an enormous number of job postings, not because they have more jobs but because they use digital hiring tools more heavily. Major metro areas in North America and Western Europe dominate most public job data feeds, even though large parts of the workforce sit outside those hubs.
This creates two problems. First, the dataset starts to make it look like most hiring happens in those cities. Second, the model begins to treat those locations as the default environments for certain job families. For example, engineering roles may appear overly concentrated in a few tech hubs simply because those companies post more often.
When an AI system relies on that data for talent analytics or hiring forecasts, it may unintentionally mirror the same urban bias. It can also influence DEI work. If your dataset underrepresents rural or emerging markets, your analysis of opportunity access will be incomplete before you even begin.
Seniority bias when junior roles use inflated requirements
A more subtle but equally common pattern is seniority inflation. Companies often add heavy requirements to junior roles or title them in ways that do not match actual expectations. You may see a “Junior Analyst” role with requirements that belong to a mid-level data scientist, or a “Coordinator” role that demands senior-level decision-making.
This bias shows up clearly in large datasets. You can see clusters of postings where the title suggests one thing, but the description implies something else entirely. When these mismatches appear at scale, models trained on the data begin to associate advanced skills with roles that should not require them.
For DEI teams, this matters because inflated requirements disproportionately deter underrepresented candidates who already face structural barriers in recruitment. For AI teams, it matters because the dataset begins to misrepresent the progression of true job levels across the market.
Why recognising these patterns is critical for responsible AI work
These three patterns are not the only forms of bias in job postings, but they are among the most influential. Once they enter your dataset, they affect everything downstream. Skills inference models, salary predictions, role clustering, workforce forecasting, DEI analytics, and sourcing recommendations all absorb the same skew.
The key is not to eliminate every trace of bias. That is not realistic. The goal is to identify the patterns, quantify them, and correct for them in your dataset architecture. Once you do that, your AI models have a clearer and more balanced foundation to learn from.
How Responsible AI Teams Use Dataset Signals to Reduce Bias Before Modeling
When AI systems fail fairness checks, people often blame the algorithm. In reality, most fairness issues trace back to the dataset. Responsible AI teams know this, which is why they focus on upstream controls rather than downstream patches. The most effective way to reduce bias in an AI hiring system is to fix the bias inside the job postings long before anything is fed into a model.
Here is how leading responsible AI, DEI, and workforce analytics teams use dataset-level signals to reduce data bias early in the pipeline.
Rewrite strategies that shift job postings toward neutral and inclusive language
One of the simplest and most effective ways to reduce data bias is to rewrite job descriptions using neutral language. After gender coded and exclusionary terms are flagged, DEI teams work with talent acquisition to replace biased wording with alternatives that communicate the same expectations without signalling who “belongs” in the role.
This is not about watering down job ads. It is about removing unnecessary barriers. For example, replacing “strong leader who can dominate fast-paced environments” with “experienced professional who can guide teams through complex work” makes the posting clearer while reducing masculine-coded tone.
When organisations start rewriting postings at scale, the dataset begins to shift. Over time, you can actually measure improvements in the overall inclusivity score of your job feed. This cleaner dataset becomes a stronger foundation for any AI model that relies on text patterns.
Employer and Industry Benchmarking Using Market-Wide Job Post Signals
Bias is often invisible until you compare your own postings against the wider market. Responsible AI teams regularly benchmark their inclusivity scores, posting locations, skill requirements, and seniority structures against aggregated job market signals.
For example, if your engineering job descriptions contain far more masculine-coded language than your industry peers, you have a clear signal that something is off. If your entry-level roles list skill requirements that resemble mid-level roles in competitor postings, that is a sign of seniority inflation. If you hire mostly in three metro areas while similar companies post across twelve, you have a geographic diversity problem.
Market-wide benchmarking helps organisations correct their datasets by adjusting their posting practices. Once postings become more aligned with healthy market norms, the dataset itself becomes more stable and less biased.
Using structured job posts to build fairer training data
When job posts are properly standardised, enriched, and cleaned, responsible AI teams use that structured dataset to train models that behave more predictably and more fairly.
A structured dataset allows you to:
- Group similar roles accurately
- Compare skills across companies without noisy text differences
- Identify distorted patterns caused by duplicates or stale postings
- Ensure that each posting has clear seniority, location, salary, and skill context
- Remove or downweight postings with heavy language bias
This prevents the model from learning accidental patterns created by messy data, such as associating certain skills with certain genders or assuming that talent only comes from a handful of cities.
For example, one AI sourcing team we worked with discovered that their recommendation engine over-prioritized candidates from tech hubs simply because their training data was dominated by postings from those cities. After restructuring the dataset using location balancing and proportional sampling, the model began identifying strong candidates in regions that were previously ignored.
Why upstream work is now central to fairness and compliance
Regulators and internal compliance teams are paying more attention to the inputs that feed workforce-related AI systems. Many organisations can no longer rely on black box models or datasets with unclear lineage. They want to know exactly how the dataset was curated, how bias was measured, and how problematic signals were handled before the model learned from them.
This shifts fairness work from reactive to proactive. Instead of waiting for biased outcomes, responsible AI teams now track data quality, language tone, seniority patterns, and geographic coverage at the ingestion stage. They fix the data first, then train their models. The result is stronger fairness guarantees and fewer surprises during audits.
Building Operational Quality Controls for Large-Scale Job Post Datasets
Once job postings start flowing in at the scale of hundreds of thousands per day, manual cleanup is no longer realistic. Bias-resistant datasets depend on strong operational controls that run continuously, not occasionally. These controls help ensure that the data downstream teams rely on stays fresh, consistent, and representative.

Freshness checks, deduplication, and anomaly detection
One of the biggest sources of data bias in job posts comes from outdated or duplicated listings. A role that stays live for ninety days can make it look like demand is higher than it is. A posting that appears across ten job boards can be mistaken for ten different opportunities. This skews forecasting models, DEI analyses, and competitive insights.
Freshness checks solve this by marking or removing postings that remain unchanged beyond a certain age. De-duplication removes near-identical posts using fuzzy matching rather than simple text comparison. Anomaly detection adds another layer by flagging posts that differ sharply from the employer’s normal patterns, such as an unrealistic skills list or an inexplicable salary drop.
These three controls ensure that what enters your dataset reflects the actual labour market, not the noise created by poor posting hygiene.
Schema validation and consistent coverage rules
Job postings look simple, but they vary wildly in structure. Some have clear seniority levels; others bury them in paragraphs. Some include salary ranges, others leave them out entirely. Missing or inconsistent fields introduce subtle forms of data bias because the gaps are not random. Certain industries consistently hide pay. Certain regions use vague titles. Certain company sizes skip descriptions altogether.
Schema validation enforces a minimum set of required fields so that every posting entering the dataset has a predictable structure. Coverage rules ensure proportional representation across industries, regions, and company sizes. Together, they prevent your model from learning patterns driven by missing data instead of real market behaviour.
Why automation matters more than manual cleanup
After structuring one hundred million job posts, one lesson became obvious. No team, no matter how large, can manually correct bias in job posting data. Patterns change too quickly. Markets shift. Companies rewrite their ads. Job boards refresh their feeds daily. Only automated monitoring can maintain the consistency and fairness required for responsible AI systems.
A bias-resistant dataset is a living system. It needs quality gates, enrichment pipelines, timestamped snapshots, and automated alerts that run every day. Without these, even a well-structured dataset will drift toward bias the moment new postings start flowing in.
Long-Term Bias Reduction Depends on the Dataset You Build, not the Model You Train
After working with job data at the scale of one hundred million postings, one truth stands out. You cannot build fair or trustworthy hiring-related AI if the dataset beneath it is biased, inconsistent, or structurally uneven. Most of the bias does not come from the algorithm. It comes from the postings themselves. The language companies use, the cities they hire in, the industries that post the most, and the fields they choose to include or omit all shape the signals that an AI model learns from.
This is why responsible AI teams are shifting their focus upstream. They are investing in dataset curation, data bias reduction, standardization, enrichment, and strong operational controls. They are not waiting for fairness failures at the model stage. They are preventing them by ensuring the dataset is balanced and defensible before a single line of model code runs.
A bias-resistant dataset is not built by accident. It is built through structure, coverage, transparency, and continuous monitoring. When job postings are cleaned, normalized, enriched, deduplicated, and scored for bias, the entire downstream AI ecosystem becomes more stable. DEI analytics become more credible. Hiring forecasts become more realistic. Salary and skills insights become more representative. And compliance teams gain far more confidence in every model that sits on top of the data.
If your organisation is exploring AI for hiring, compensation intelligence, DEI reporting, or labour market analytics, start with the dataset. Clean data is helpful. Bias-resistant data is transformative.
See how structured job data reduces bias at the source
Start improving fairness and data quality before you ever train a model.
FAQs
1. What is data bias in job postings?
Data bias in job postings is what happens when the job data you collect does not reflect the real labour market, but the habits and blind spots of the employers who wrote those ads.
Maybe most of your job posts come from a handful of big cities. Maybe one industry dominates your feed. Maybe nearly all the “leadership” roles in your dataset are written in a very masculine tone. When that kind of skew shows up across thousands of job posts, it stops being noise. It becomes a pattern.
Any AI model trained on that data will learn from those patterns. That is how data bias in job postings quietly turns into bias in AI job postings, recommendation engines, or hiring analytics unless you fix it at the dataset stage.
2. How does dataset curation help reduce data bias?
Dataset curation is the slow, unglamorous work that makes data bias reduction possible. It means you are not just dumping every job post into a database and calling it “big data.” You are making decisions.
In practice, that includes steps like standardising titles, cleaning messy text, removing near duplicates, marking stale posts, and making sure you have reasonable coverage across industries, regions, and company sizes. It also means checking whether some fields, like salary or seniority, are missing more often in certain sectors.
When you do this consistently, the dataset becomes more honest. It still reflects the market, but it is less warped by posting habits. That is what gives your downstream AI systems a fairer starting point.
3. What causes gender bias in job postings?
Gender bias in job postings usually starts with language and expectations. Most of it is unintentional. Hiring managers reach for familiar phrases like “aggressive,” “dominant,” or “rockstar” in tech and sales roles, or they load junior job posts with long lists of “must have” skills.
Studies have shown that this kind of wording can reduce women’s sense of belonging and interest in a role, even when the actual job content is the same. When those patterns are repeated across thousands of job posts, gender bias is no longer an isolated copywriting issue. It becomes a structural feature of your data.
So when you talk about gender bias in job postings, you are not only talking about a few bad sentences. You are talking about a consistent signal that an AI model can easily pick up and normalise if you do not catch it.
4. Which bias detection methods work best for job post datasets?
No single method is enough on its own, especially at scale. In practice, the teams that take this seriously use a mix of three things.
First, lexicon-based checks that scan for known gender coded or exclusionary terms. These are simple to explain and easy to operationalise. Second, machine learning models that look for subtler patterns, like inflated requirements for junior roles or unusually harsh tone in some job families. Third, a human review loop for the grey areas where context matters.
The aim is not to label every job posting as “good” or “bad.” The aim is to spot where bias in job postings is strongest, so you can rewrite, reweight, or remove those posts before they become training data.
5. How do companies use structured job posts to build bias-resistant AI?
Structured job posts turn a messy stream of ads into something you can trust as a training set. Titles are standardised. Locations are mapped to clear geographies. Seniority and skills are normalised. Language bias is scored. Duplicates are removed. Old posts are flagged.
Once that work is in place, companies have options. They can downweight heavily biased segments. They can balance the dataset across regions or industries. They can track whether gender bias in job postings is going up or down over time. They can give compliance teams a clear story about how data bias was handled before a model was trained.
The result is not a perfect dataset. There is no such thing. What you get instead is a bias-resistant dataset that has been curated with intention, which is exactly what responsible AI leaders, DEI officers, and auditors now look for.




