
- What Recruiters Need to Know About Using Recruiting Data to Hire Faster
- Why Time-to-Hire Is Costing You More Than You Think
- Faster Hiring Starts With Better Recruiting Data
- Where Most Hiring Processes Actually Break Down
- What Recruiting Data Actually Looks Like in Practice
- How JobsPikr's Job Market Data Fixes Each Hiring Bottleneck
- How One Recruiter Cut a 60-Day Search Down to 40 Days
- How Recruiting Data Speeds Up Every Stage of the Hiring Funnel
- Reactive vs. Proactive Recruiting: What Separates the Best Hiring Teams
- Cut Your Time-to-Hire With the Right Recruiting Data
- Frequently Asked Questions About Recruiting Data and Time-to-Hire
What Recruiters Need to Know About Using Recruiting Data to Hire Faster
Hiring the right person has always been part art, part science. But in today’s market, the teams that consistently close roles faster aren’t just better at recruiting; they’re better informed. Slow hiring is one of those problems that feels like a process issue on the surface, but when you dig in, it almost always comes down to a lack of the right recruiting data at the right time. This article breaks down how recruiters are using job market intelligence to make sharper decisions at every stage of the hiring funnel, and what a 30% reduction in time-to-hire actually looks like in practice.
- Unfilled roles can cost up to 1.5 to 2x the annual salary of the position in lost productivity and spending.
- Top candidates are typically off the market within 10 days of starting their search.
- Most hiring delays trace back to four fixable problems: wrong sourcing geography, misaligned comp, vague job descriptions, and missing market context.
- Real-time recruiting data on talent availability, salary benchmarks, and role demand can directly fix each of these bottlenecks.
- A composite case in this article shows how one recruiter cut a 60-day search to 40 days using workforce intelligence.
The bottom line: faster hiring isn’t about rushing the process. It’s about removing the guesswork from it.
Why Time-to-Hire Is Costing You More Than You Think

Most recruiting teams treat time-to-hire as a reporting metric. Something to track, benchmark, and bring up in quarterly reviews. But slow hiring shows up as a real business cost in three very concrete ways: lost productivity, higher acquisition spend, and, more often than not, a weaker hire.
Let’s start with the numbers. According to SHRM, the average cost-per-hire in the US sits at around $4,700. But that figure doesn’t capture what an open role actually costs the business while it sits vacant. When you factor in lost output, manager time spent interviewing, and the drag on team productivity, the total cost of a vacancy can reach 1.5 to 2 times the annual salary of the position. For a $100,000 role, that’s a significant amount of money bleeding out every week the seat stays empty.
Then there’s the talent quality problem. The strongest candidates are typically off the market within 10 days of starting their search, according to LinkedIn Talent Solutions. A hiring process that runs 45 or 60 days isn’t competing for the same pool of people it started with. By the time an offer goes out, the best candidates have already accepted something else.
Industry benchmarks put average time-to-hire somewhere between 30 and 45 days, with technical and senior roles often running well beyond that. Most hiring managers will tell you the same thing regardless of industry: it takes longer than it should.
The more useful question is not how long it takes. It’s where the time is actually going.
Faster Hiring Starts With Better Recruiting Data
Every day a role sits open costs your business more than you think. The teams closing roles faster are not working harder; they are working with better information.
Where Most Hiring Processes Actually Break Down
Here’s something worth sitting with: most recruiting delays are not random. They follow a pattern. And once you see that pattern, it becomes a lot easier to understand why some teams consistently hire faster than others without cutting corners on quality.
The time loss almost always concentrates in four specific places.
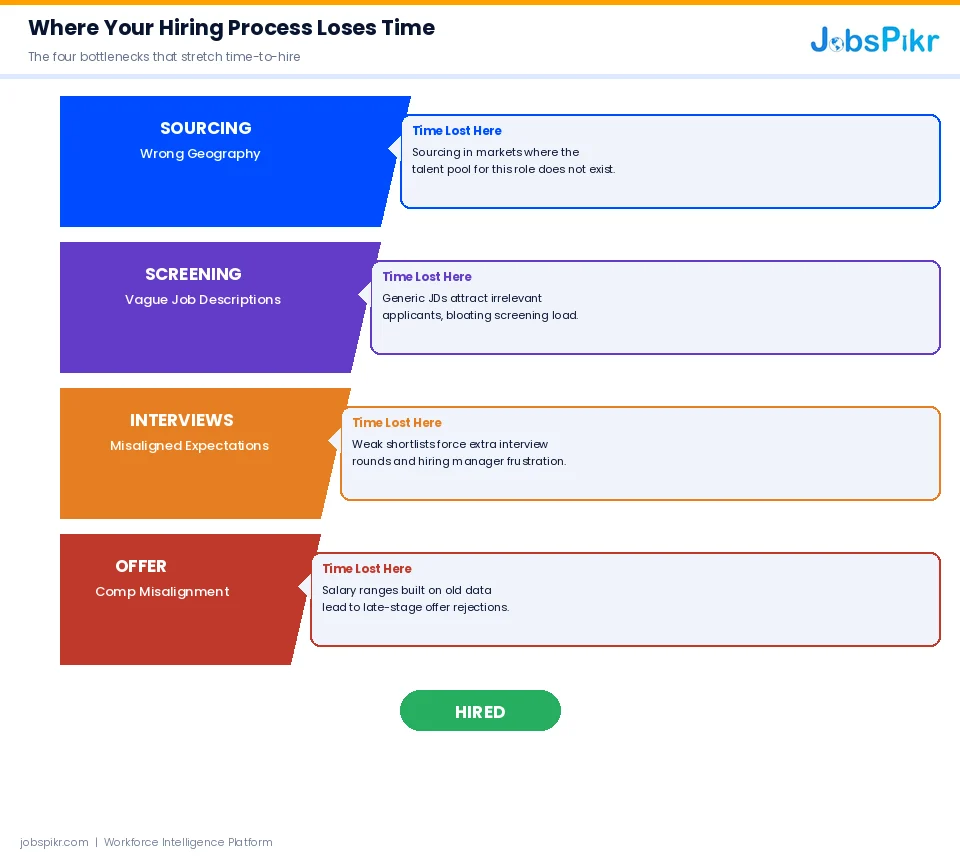
Sourcing in the Wrong Geography
A recruiter posts a role, waits two weeks for applications, and gets a thin or unqualified pipeline. The instinct is to blame the job description or the compensation. But often, the real problem is simpler: the talent pool for that role is not where the search is focused. Without job market data on where qualified candidates for a specific role are actually concentrated, sourcing becomes a guessing game. And guessing is slow.
Misaligned Compensation Expectations
This one kills offers more than any other factor. A candidate makes it through the full process, the hiring manager is excited, and then the offer lands 15% below what the candidate was expecting based on what the market is actually paying. The offer gets rejected, the search restarts, and four weeks of work evaporate. According to LinkedIn, compensation misalignment is one of the leading reasons candidates drop out late in the hiring process, which is the most expensive stage to lose someone.
Vague or Poorly Targeted Job Descriptions
A job description that is too generic attracts too many unqualified applicants. One that is too narrow misses good candidates who might have used different terminology for the same skills. Either way, the screening stage bloats, and time-to-hire stretches. Most JD problems come from writing descriptions based on internal assumptions rather than what the actual talent market looks like for that role right now.
Missing Market Context
This is the overarching problem that connects the other three. When recruiters do not have access to real-time job market intelligence, every decision in the hiring funnel is made with incomplete information. Sourcing decisions, comp decisions, and JD decisions: all of them default to gut feel or outdated benchmarks. That is where the time goes.
The good news is that all four of these problems are addressable. And recruiting data is what addresses them.
What Recruiting Data Actually Looks Like in Practice
There is a version of “data-driven recruiting” that most teams are already doing. They have an ATS that tracks application volume, they pull time-to-fill reports at the end of the quarter, and they occasionally benchmark salaries using a survey their HR team ran 18 months ago. That is reporting. It is useful, but it is not the same thing as working with real-time job market data.
The distinction matters because reporting tells you what already happened. Job market intelligence tells you what is happening right now, and more importantly, what to do next.
The Difference Between Lagging and Leading Data

Lagging data confirms outcomes after the fact. Your time-to-hire was 52 days last quarter. Your offer acceptance rate dropped to 68%. You lost three candidates at the offer stage. These are all useful things to know, but by the time you are reading them, the damage is already done.
Leading data, on the other hand, gives you signals before decisions are made. Which cities have the highest concentration of candidates with the specific skill set you are hiring for right now? What are similar companies actually paying for this role in this market, not what they were paying a year ago? Is demand for this role rising or falling across the industry, and how is that affecting candidate expectations? This is what talent intelligence looks like when it is actually working.
Why Spreadsheets and Salary Surveys Are Not Enough
Most recruiters are resourceful. They cobble together data from wherever they can find it: salary surveys, job board aggregates, internal comp bands, and anecdotal feedback from candidates. The problem is not effort; it is freshness and specificity. A salary survey published in January reflects data collected months before that. A job board aggregate tells you what other companies are posting, not what candidates are actually accepting. And internal comp bands are built around what a company has historically paid, not what the market currently demands.
Real-time recruiting data closes that gap. When you can see live signals on talent availability, active salary ranges, and role demand trends, you stop making decisions based on assumptions and start making them based on what is actually true in the market today. That shift alone is what separates reactive recruiting teams from proactive ones.
How JobsPikr’s Job Market Data Fixes Each Hiring Bottleneck
Understanding where hiring processes break down is one thing. Having the tools to actually fix those breakdowns in real time is another. This is where workforce intelligence from JobsPikr comes in. Rather than replacing the recruiter’s judgment, it sharpens it by giving every decision in the hiring funnel a data foundation it would not otherwise have.
Here is how that plays out across each of the four bottlenecks covered earlier.
Talent Availability Signals for Smarter Sourcing Geography
JobsPikr aggregates job market data across geographies, industries, and role types at scale. For a recruiter trying to fill a niche technical role, this means being able to see where the actual supply of qualified candidates is concentrated before committing to a sourcing strategy.
Instead of defaulting to the same cities or platforms used for the last hire, a recruiter can look at talent availability signals and ask: where are the most candidates with this specific skill set actively present in the market right now? That question, answered with real data rather than intuition, changes where sourcing effort gets directed. And redirecting sourcing effort to higher-density talent pools is one of the fastest ways to shrink the time between posting a role and building a qualified pipeline.
Real-Time Salary Benchmarks for Faster, Cleaner Offers
JobsPikr’s salary data is pulled from live job postings across the market, which means it reflects what companies are actively offering right now, not what they offered during a survey period six months ago. For recruiters, this has a direct impact on one of the most time-sensitive moments in the hiring process: the offer stage.
When comp benchmarking is built on current market data, there are fewer surprises on both sides of the table. Hiring managers can set realistic salary ranges before the search begins, candidates move through the process with expectations that are already roughly aligned with what is coming, and offer acceptance rates improve. Fewer rejected offers means fewer restarts, and fewer restarts means a shorter overall time-to-hire.
Role Demand Trends for Sharper Job Description Targeting
One of the less obvious ways job market intelligence speeds up hiring is through job description optimization. JobsPikr’s data on role demand trends shows which skills, titles, and qualifications are appearing most frequently in active job postings for a given role. This gives recruiters a live read on how the market is describing and defining a position, which is something internal assumptions simply cannot replicate.
A job description written with this kind of market context attracts a more relevant applicant pool from the start. That means less time spent screening out unqualified applications, a shorter path to a shortlist, and a faster move to interviews. It is a small change in how a JD gets written, but the downstream effect on recruiting efficiency is significant.
And here is a look at JobsPikr’s talent intelligence platform in action:
See how workforce intelligence translates into faster, smarter hiring decisions across the full recruiting funnel.
How One Recruiter Cut a 60-Day Search Down to 40 Days
To make this concrete, consider a composite scenario based on the kind of workflow shifts that workforce intelligence enables in practice. This is not a single customer story, but it reflects the pattern of changes that recruiting teams make when they move from gut-feel hiring to data-driven recruiting.

The Situation Before
A senior recruiter at a mid-sized technology company was tasked with filling a data engineering role. The hiring manager needed someone with a specific combination of skills: experience with cloud-based data pipelines, familiarity with a particular set of tooling, and enough seniority to work with minimal oversight.
The recruiter did what most experienced recruiters do. They posted the role on the usual platforms, targeted the same metro areas the company had hired from before, set a salary range based on internal comp bands, and waited. Two weeks in, the pipeline was thin. The applications that did come in were mostly off the mark, either too junior or missing key technical requirements. The hiring manager was already getting impatient.
By the time the recruiter had sourced enough qualified candidates to build a real shortlist, four weeks had gone by. Interviews ran across weeks five and six. An offer went out in week seven, and it came back rejected. The candidate had received a competing offer with a base salary that was notably higher than what the company had budgeted. The search restarted. The final hire came in at day 62.
What Changed With Recruiting Data
Now run the same search with job market intelligence behind it.
Before posting the role, the recruiter pulls talent availability data from JobsPikr. The signal is clear: the highest concentration of candidates with the exact skill profile needed is not in the city the company defaulted to. There is a significantly deeper talent pool in two other markets, one of which also happens to have a lower average salary expectation for the role. Sourcing effort shifts accordingly.
The job description gets written using role demand trend data. The recruiter can see which specific skills and qualifications are appearing most frequently in similar active postings across the market, and which terms candidates in this space are actually responding to. The JD gets sharper and more precisely targeted as a result.
Compensation benchmarking happens before the role is even opened, using live salary data from JobsPikr rather than internal bands built on historical hires. The hiring manager agrees to a range that is competitive with what the market is actually offering right now. That range gets communicated early in the process, so candidates self-select based on real expectations rather than finding out the number for the first time at the offer stage.
The pipeline builds faster because sourcing is focused on the right geography. Screening moves more quickly because the JD attracted a more relevant applicant pool. The offer goes out in week five, it lands within the candidate’s expectations, and it gets accepted. Total time-to-hire: 40 days.
What Actually Drove the Reduction
The recruiter did not work faster. They did not skip steps or rush decisions. What changed was the quality of information behind each decision. Smarter sourcing geography meant a stronger pipeline sooner. A sharper job description meant less time screening out noise. Current salary benchmarks meant no offer surprises. Each of those improvements, individually, might save a few days. Together, they compound into a meaningful reduction in overall time-to-hire.
This is what data-driven recruiting looks like when it is working. Not a dramatic overhaul of the hiring process, but a series of better-informed decisions at the moments that matter most.
How Recruiting Data Speeds Up Every Stage of the Hiring Funnel
One of the most useful ways to think about recruiting data is to map it to the specific stages where hiring decisions happen. Job market intelligence is not a single input that goes into one part of the process. It touches every stage of the funnel, and the compounding effect of better decisions across all of them is what produces a meaningful reduction in time-to-hire.
Here is how it breaks down in practice.
Sourcing: Finding the Right Talent Pool Faster
The sourcing stage is where most time-to-hire problems are created, even though they often do not show up until later in the process. A weak or mismatched pipeline at the top of the funnel means every stage downstream takes longer: more screening, more second-round interviews to compensate for thin shortlists, more time before a qualified candidate is even in the room.
JobsPikr’s talent availability data gives recruiters a live read on where candidates with specific skills and experience levels are actually concentrated in the market. This makes it possible to make sourcing geography decisions based on evidence rather than habit, and to identify talent pools that internal teams may not have considered before. The result is a stronger pipeline built in less time, which is the single most effective way to compress overall recruiting timelines.
Screening: Cutting Through the Noise Faster
A bloated screening stage is almost always a job description problem in disguise. When a JD is too vague or too generic, it pulls in a wide range of applicants, most of whom are not a strong fit. Recruiters then spend days or weeks working through that volume to find the handful of candidates worth moving forward.
Role demand trend data from JobsPikr helps recruiters write job descriptions that are calibrated to what the actual talent market looks like for a given role right now. When the language, required skills, and qualifications in a JD reflect current market reality, the applicant pool that comes in is more relevant from the start. Screening moves faster not because the process is rushed, but because there is less noise to work through.
Interviews: Getting to the Right Shortlist Without Wasted Rounds
Interview stages slow down when the shortlist is not strong enough to begin with, or when hiring managers and recruiters are misaligned on what they are looking for. Both of these problems have a data dimension.
When sourcing and screening have been guided by real job market data, the candidates who reach the interview stage are more likely to be genuinely qualified. That means fewer interview rounds needed to find someone worth moving forward with, and less back-and-forth between recruiters and hiring managers on whether a candidate meets the bar. It is a quieter benefit of data-driven recruiting, but it shows up consistently in teams that have made the shift.
The Offer Stage: Closing Without Surprises
The offer stage is where slow hiring gets expensive in the most visible way. A rejected offer at this point means restarting a search that may already have taken four to six weeks, and doing it with a hiring manager who is now frustrated and a team that has been short-staffed even longer.
Real-time salary benchmarking from JobsPikr addresses this directly. When compensation ranges are set using live market data before the search begins, candidates move through the process with expectations that are already roughly in line with what is coming. Offer conversations are shorter, acceptance rates improve, and the kind of late-stage dropout that resets the entire timeline becomes far less common.
According to SHRM, organizations that use data to inform their hiring decisions report measurably better outcomes across cost-per-hire, time-to-fill, and quality of hire metrics. The offer stage is often where those improvements are most visible.
Reactive vs. Proactive Recruiting: What Separates the Best Hiring Teams
There is a version of recruiting that most teams are stuck in without realizing it. A role opens, the search begins. A pipeline comes in thin, so the sourcing effort increases. An offer gets rejected, so the search restarts. Every decision is a response to something that has already gone wrong. This is reactive recruiting, and it is the default mode for teams that do not have access to real-time job market intelligence.
Proactive recruiting looks different. Decisions are made ahead of the problem rather than in response to it. Sourcing geography is chosen based on where talent actually exists, not where the company has always looked. Compensation ranges are set before the search begins, not negotiated awkwardly at the offer stage. Job descriptions are written to reflect what the market looks like today, not what the role looked like the last time it was hired for. The process still requires skill and judgment, but those things are now backed by data rather than running on intuition alone.
The table below shows how that difference plays out across the key moments in a hiring process.
| Hiring Stage | Reactive Recruiting | Proactive Recruiting with Job Market Data |
| Sourcing Geography | Default to familiar cities and platforms | Use talent availability signals to find highest-density candidate pools |
| Compensation Benchmarking | Set ranges based on internal bands or old surveys | Use real-time salary data to align ranges with current market before search begins |
| Job Description Writing | Based on internal assumptions and past JDs | Informed by live role demand trends and market skill data |
| Pipeline Quality | High volume, low relevance, heavy screening needed | Targeted applicant pool, faster path to shortlist |
| Offer Stage | Frequent misalignment, higher rejection rates | Expectations aligned early, cleaner closes |
| Overall Time-to-Hire | 45 to 60+ days, with restarts common | 30 to 40 days, with fewer late-stage dropouts |
The 30% reduction in time-to-hire that recruiting data makes possible is not the result of one big change. It is the result of better decisions compounding across every row in that table. Each individual improvement saves days. Together, they save weeks.
This is ultimately what workforce intelligence is for. Not to automate recruiting or remove the human judgment that good hiring requires, but to make sure that judgment is working with the best possible information at every stage of the process. The recruiters and talent acquisition teams that figure this out are not just hiring faster. They are hiring better, spending less, and building a function that the rest of the business can actually rely on.
If your team is still making sourcing, compensation, and JD decisions without real-time recruiting data behind them, the gap between where you are and where you could be is probably larger than you think.
Cut Your Time-to-Hire With the Right Recruiting Data
See how JobsPikr’s talent intelligence maps to your specific roles, markets, and hiring bottlenecks.
Frequently Asked Questions About Recruiting Data and Time-to-Hire
1. What is recruiting data and how is it different from regular HR reporting?
Recruiting data, in the context of talent intelligence, refers to real-time signals pulled from the live job market: where candidates are concentrated, what roles are in demand, what companies are actively paying for specific skills, and how hiring trends are shifting across industries and geographies. This is fundamentally different from standard HR reporting, which typically looks backward at what already happened inside your own hiring process. Time-to-fill last quarter, offer acceptance rates year to date, cost-per-hire by department: these are all useful metrics, but they tell you about outcomes, not about the market conditions that shaped them. Real-time recruiting data gives you the forward-looking intelligence to make better decisions before problems show up in your reporting.
2. How does job market data actually reduce time-to-hire?
The reduction happens across multiple stages of the hiring funnel, not at a single point. Better talent availability data means sourcing effort goes to the right geography from day one, which builds a stronger pipeline faster. Real-time salary benchmarks mean compensation ranges are set accurately before the search begins, which reduces offer rejections and eliminates the time lost to restarting a search. Role demand trend data means job descriptions attract a more relevant applicant pool, which cuts screening time significantly. Each of these improvements saves days individually. When they compound across a full hiring process, the cumulative reduction in time-to-hire can reach 30% or more, which is consistent with what SHRM research shows for organizations that adopt structured, data-informed hiring practices.
3. What is time-to-hire and why does it matter for business performance?
Time-to-hire measures the number of days between when a role is opened and when a candidate accepts an offer. It matters for business performance for a straightforward reason: every day a role sits vacant is a day of lost productivity, and that lost productivity has a real cost. As noted earlier in this article, SHRM estimates the total cost of a vacancy can reach 1.5 to 2 times the annual salary of the position when you factor in lost output and recruiting spend. Beyond the financial cost, slow hiring also affects talent quality, since the strongest candidates are typically off the market within 10 days of starting their search. A hiring process that consistently runs long is not just expensive, it is structurally disadvantaged in the competition for top talent.
4. Can small or mid-sized recruiting teams realistically use workforce intelligence tools?
Yes, and in many ways smaller teams stand to benefit more from job market intelligence than large enterprise teams with dedicated sourcing functions and extensive internal data. A smaller recruiting team typically does not have the bandwidth to manually research talent availability across geographies, run salary benchmarking studies, or analyze job posting trends for every role they hire. Workforce intelligence platforms like JobsPikr do that work automatically, which means a lean team of two or three recruiters can make decisions with the same quality of market context that a much larger team would need dedicated analysts to produce. The key is finding a platform that surfaces the right signals clearly, without requiring significant technical overhead to use day to day.
5. How do I know if my team’s time-to-hire problem is a data problem?
A useful starting point is to look at where time is actually being lost in your process. If your pipeline consistently comes in thin or unqualified, that is likely a sourcing geography or job description problem, both of which are addressable with better market data. If candidates are dropping out at the offer stage, that points to a compensation benchmarking problem, which real-time salary data directly solves. If your screening stage is taking weeks because of high application volume with low relevance, that is a job description targeting problem that role demand trend data can help fix. If the answer to most of these questions is “we are not sure where the time is going,” that itself is a strong signal that your team is operating without enough market visibility. The first step is usually not buying a new tool. It is getting honest about which decisions in your hiring funnel are currently being made without the data to back them up.




