
- **TL;DR**
- What does a Responsible & Compliant Data Infrastructure look like in HR and workforce analytics?
- Ready to See Responsible & Compliant Data Infrastructure in Action?
- What Data Infrastructure Means When You’re Working With Workforce and Job-Market Data
- The Building Blocks of a Responsible and Compliant Data Infrastructure
- Ready to See Responsible & Compliant Data Infrastructure in Action?
- How Compliant Data Infrastructure Fits into GDPR, CCPA, SOC 2, HIPAA, and the Wider Data-Security Landscape
- How JobsPikr Builds Responsible, Compliant Data infrastructure Into every Stage of its Product
- Why a Responsible Data Infrastructure Is the Foundation for Trustworthy AI in HR and Talent Intelligence
- The Business Value of Responsible Data Infrastructure: Why HR leaders Trust it and Why Enterprises Require It
- The Responsible Data Lifecycle: A Step-by-Step View of How the Pipeline Works
- The Questions HR and People-Analytics Teams Raise Once They Look Past the Dashboard
- Why Responsible Data Infrastructure Defines the Future of Workforce Intelligence
- Ready to See Responsible & Compliant Data Infrastructure in Action?
- FAQs:
**TL;DR**
When you buy any kind of workforce data or people analytics platform, you are not just buying insights. You are also buying the way that data was collected, stored, and governed. This article walks through what a responsible data infrastructure should look like today: clear, transparent data sourcing, consent-aware and compliant collection, strong governance, and security baked in from day one. You will see how JobsPikr handles data compliance across frameworks like GDPR and CCPA, how we think about anonymization and access control, and why that matters when you are building AI models or sensitive HR dashboards. By the end, you will have a practical checklist in your head for what “good” looks like, and a clearer view of how compliant data infrastructure reduces risk while still giving you the intelligence you need.
Key takeaways
- You are never just buying insights. You are also buying the sourcing rules, governance, and security behind the data that powers those insights.
- “Responsible data” means you can clearly answer where data came from, what you are allowed to do with it, and who inside your company can touch which fields.
- A compliant data infrastructure bakes in GDPR, CCPA, and other data compliance requirements from the start, instead of patching them on later.
- JobsPikr’s data infrastructure is designed for HR and people analytics teams that need external labor data, but cannot afford loose practices around privacy, consent, or access control.
What does a Responsible & Compliant Data Infrastructure look like in HR and workforce analytics?
If you work in HR tech, people analytics, or talent intelligence, you already live in dashboards, exports, and models. The part that rarely gets talked about in detail is everything underneath those views: how the data got there, what rules it passed through, and who decided what was “in bounds” or “out of bounds.”
That invisible layer is your data infrastructure. And when you are dealing with workforce and job market data, it is not just a technical setup. It is a mix of sourcing policies, legal guardrails, privacy choices, access rules, and security controls that decide what even enters your system in the first place.
In the past, teams could get away with “just get the data in and we will figure out the rest.” With regulations like GDPR and CCPA, and with AI systems reading data at scale, that approach is now risky and outdated. If you cannot explain where your data came from, what makes it compliant, and how it is protected, you will eventually run into a conversation with legal, security, or your board that you do not want to have.
This article takes that hidden layer and puts it on the table. We will talk about what responsible data infrastructure means in practice for HR and workforce analytics: how data is sourced, which compliance rules matter, what “good” governance feels like day to day, and how JobsPikr designs its own pipelines so clients can use external labor data with confidence. The goal is simple: give you a clear picture of what to expect from any vendor that claims to offer responsible, compliant data.
If you already know this is a gap in your current setup and want to see how JobsPikr handles it in production, you can always skip ahead in real life and ask our team for a short demo of the data infrastructure behind the product.
Ready to See Responsible & Compliant Data Infrastructure in Action?
Explore real labor-market datasets sourced, governed, and processed through JobsPikr’s compliance-first pipeline to understand the depth and quality behind every signal.
What Data Infrastructure Means When You’re Working With Workforce and Job-Market Data
If you work with HR systems, talent dashboards, or labor market tools, you already live in reports and exports all day. The part that usually stays invisible is everything underneath those views: how the data got there, what was filtered out, and who decided those rules in the first place. That hidden layer is your data infrastructure.
In the context of workforce and job market data, “data infrastructure” is not just a stack diagram or a list of tools. It is the set of choices that decides which signals you ingest, what you store, how long you keep it, and which people or systems are allowed to touch it. That is exactly where responsible data and compliant data either start or fail.
A simple explanation of data infrastructure in plain terms
When people say “data infrastructure,” they usually picture servers and pipelines. In practice, it is the messy middle that happens long before a chart shows up on your screen. It covers where the data was pulled from, what you decided to keep or drop, which quality checks it went through, and how it is locked down once it lands.
If that layer is weak, your dashboards may look polished, but the decisions behind them rest on shaky ground. For HR and people analytics teams, that can mean concluding job-market data that was sourced without clear terms, mixed with outdated fields, or stored in ways that would make your security team uncomfortable.
This is why “what is data infrastructure?” is no longer a technical question only your engineers answer. It is a risk question, a compliance question, and for many HR tech leaders, a brand question.
Why older data infrastructure models don’t hold up anymore
A lot of organizations still run on habits from a different era: collect whatever you can, dump it into a warehouse, and figure out the rules later. That approach might have felt fast at the time, but it does not match today’s environment.
Regulations like GDPR and CCPA expect you to know exactly why you are collecting data, what you are allowed to do with it, and how long you intend to keep it. Security teams want a clear map of where sensitive data sits and who can access it. Procurement teams increasingly ask vendors detailed questions about data infrastructure and data compliance before signing anything.
Once you start feeding this data into models, any small issue gets multiplied. A field that was never meant to be stored, a source that did not have the right usage terms, a dataset that was never properly cleaned, all of that spreads quietly across reports and AI outputs. If you cannot tell a straight story about where the data came from and what checks it passed, it is very hard to look anyone in legal or compliance in the eye and say, “Yes, this is fine.”
Why responsible data infrastructure is now the baseline, not a nice-to-have
It does not matter whether you are using external job data to size a new market, track competitor hiring, or feed a skills benchmark into your comp model. If the underlying data was collected in a sloppy or opaque way, every downstream use inherits that risk.
A responsible data infrastructure puts some hard edges around what you will and will not do with data, so you are not constantly worrying about consent, over-collection, or who has access to fields that should have stayed locked down. It brings together three things:
- Clear sourcing rules and documentation so you know exactly where workforce data came from and on what basis you are allowed to use it.
- Governance and access control so only the right people, tools, and AI systems can see specific slices of data.
- Security and compliance practices that line up with frameworks like GDPR, CCPA, and broader data security compliance expectations.
For HR tech and people analytics teams, this is where trust is either earned or lost. When a vendor can explain their data infrastructure in concrete, responsible terms, it is much easier to bring them through security, legal, and procurement without friction.
The Building Blocks of a Responsible and Compliant Data Infrastructure
Responsible data infrastructure comes down to a simple question:
“If someone questioned this dataset tomorrow – legal, security, your CHRO – could you explain how it got here and why it’s okay to use?”
If the answer is yes, you probably have a solid foundation. If the answer is “we’d need a few weeks to dig into it,” there is work to do.
When you are dealing with workforce and job-market data, that foundation is made up of a few very practical blocks: how you source data, what you log, what you throw away, who can see what, and how easily you can retrace your steps. Let’s break those down in plain language.

Transparent data sourcing and clear documentation matter more than ever
Data infrastructure starts at the point where you first touch the data, not when it hits a warehouse.
With job and workforce data, that usually means job boards, career sites, public company pages, and structured feeds. A responsible setup does not just say “we pull from a lot of sources.” It can list those sources, describe how they are accessed, and show the terms under which that data is used.
In practice, this looks like a simple, boring thing: a maintained source registry. For each source, you know what type of data you collect, what the usage restrictions are, and when those terms were last checked. If someone internally asks, “Are we allowed to use this for modelling?”, you are not guessing. You are looking it up.
Consent, rights, and usage boundaries baked into the pipeline
For public job data, you are not dealing with consent in the same way you do for employee records. But you are still dealing with rights and boundaries: what is acceptable to store, enrich, and reuse, and under which laws.
In a compliant pipeline, these decisions are not made ad hoc. They are encoded.
For example, you might decide that you never store personal contact details if they appear, you exclude certain types of fields by default, and you respect “do not collect” signals where they exist. Those rules sit inside the pipeline itself, not in a slide deck. That way, even as new sources are added, the same guardrails apply without someone having to remember them manually.
The goal is simple: if you show the pipeline to a privacy or legal team, they can see where rights and limitations are respected, not just hear that “we take compliance seriously.”
Quality checks that remove noise, duplication, and stale data
Job-market data is messy by nature. The same role can appear three times with slightly different titles. Location fields jump between formats. Some postings never get updated; they just sit there.
If you are serious about responsible data, you do not treat this as “just a data science issue.” You treat it as part of your data infrastructure.
A good setup will, for example:
- Detect obvious duplicates so you are not counting the same vacancy multiple times when you show “demand by role” to an HR leader.
- Flag postings that look stale or out of date, so they do not quietly flow into trend charts or model training data.
You also keep a simple log of what gets dropped and why. That way, when someone questions a number in a dashboard, you can point back to the rules and say, “Yes, here is where we filtered that out.”
Governance and access that reflect how HR data is really used
Once data enters your environment, the next question is: who can actually see it?
In HR and people analytics, different teams need different levels of visibility. A data scientist building a model may need granular, field-level data. An executive browsing a dashboard probably does not. A responsible data infrastructure respects that difference.
Instead of giving everyone access to the same tables, you design views and roles:
- Analysts get richer, but still controlled, access so they can build models without digging into fields they do not need.
- Business users see aggregated or anonymized views that are enough for decisions, but not enough to create new risks.
It sounds simple, but most data incidents do not come from hackers. They come from someone who had access to more data than they should have, pulling a file they never needed in the first place.
Anonymization and minimization: only keep what actually adds value
With workforce data, you almost never need to know who a specific individual is. You care about roles, skills, locations, volumes, and trends.
A responsible data infrastructure leans into that. It strips away anything that points to a person, and it actively questions whether a field is worth keeping at all. If a column does not help with analysis, and it adds risk, it goes.
This is data minimization in practice, not just as a policy sentence. Over time, this kind of discipline pays off. Your datasets become easier to explain, easier to govern, and much less scary to your compliance team.
Security that lives in everyday operations, not just in a policy document
Most vendors will tell you they use encryption and secure storage. The question is how that shows up day to day.
In a mature, compliant setup, security is not a single control. It is a bunch of small habits:
- Environments are separated, so a test system cannot quietly turn into a shadow warehouse.
- Access is reviewed regularly, so ex-employees or old contractors do not keep lingering permissions.
- Logs are monitored, so unusual queries or exports are noticed and discussed, not found six months later.
These things do not show up in marketing copy, but they are exactly what a CISO or security reviewer will ask about when you bring a new data vendor into the stack.
Auditability and traceability for when someone asks, “Where did this come from?”
Finally, there is the part everyone ignores until the first audit: can you retrace your steps?
If a regulator, internal audit team, or customer asks, “How did you generate this view of the job market?” you should be able to walk backwards:
- From the dashboard to the dataset.
- From the dataset to the pipeline steps.
- From the pipeline to the original, documented sources.
You do not need a perfect, academic data lineage graph for every field. But you do need enough traceability to show that this was not a random, one-off export that nobody remembers. That level of auditability is what turns “trust us” into “here is how it works.”
Ready to See Responsible & Compliant Data Infrastructure in Action?
Explore real labor-market datasets sourced, governed, and processed through JobsPikr’s compliance-first pipeline to understand the depth and quality behind every signal.
How Compliant Data Infrastructure Fits into GDPR, CCPA, SOC 2, HIPAA, and the Wider Data-Security Landscape
Most HR and people analytics teams don’t start their day thinking about regulation. They start with a question: “Can we trust this data enough to use it in a model, a dashboard, or a forecast?”
Compliance frameworks step in when someone needs to justify that trust. They don’t exist to slow you down. They exist to make sure the data you’re using was collected and handled in a way that won’t create trouble a year later.
Workforce and job-market data may seem harmless, but regulators treat any information tied to individuals, locations, or employment conditions with care. That means your data infrastructure has to line up with global rules, even if you’re not processing employee records directly.
Here’s how those frameworks actually show up inside a responsible data setup.
GDPR compliance in practice: lawful basis, boundaries, and the “should we keep this?” test
GDPR gets thrown around a lot, but most of its impact comes down to a few practical questions. For external workforce data, you need to know:
- Why are we allowed to collect this?
- Are we storing more than we need?
- Could any of these fields point back to a person?
A compliant infrastructure answers those questions inside the pipeline itself. For example, if your ingestion system sees personal contact details inside a job post (it happens more often than you’d think), those fields are automatically dropped. If a source changes its terms, the pipeline reflects that without waiting for someone in engineering to get around to it.
GDPR is mostly about discipline: only take what you need, don’t keep it forever, and be prepared to explain those choices.
CCPA compliance: transparency, opt-outs, and respecting what people do not want collected

Image Source: Techtarget
CCPA focuses heavily on giving individuals clear control over how their data is used. With job-market data, the biggest implication is respecting boundaries around:
- Fields that could identify a specific person
- Sources that require explicit opt-out handling
- Data that should be categorized as “do not sell”
A compliant data setup has this built into it. You are not manually scanning datasets for restricted fields — the pipeline filters them out. You honor opt-out rules at the point of collection, not after the fact. And if someone asks what categories of data you store, you can answer that clearly because the inventory is documented, not scattered across systems.
CCPA is essentially about clarity: can someone understand what you’re doing with their data, and could you prove that you respected their boundaries if asked?
SOC 2 and ISO 27001: what they actually signal for HR and talent-data buyers
SOC 2 and ISO 27001 are sometimes treated like stickers vendors slap on PDFs. In reality, they tell you something real: the vendor is operating their data environment with repeatable, monitored, audited controls.
In the HR and labor-data world, that matters because your procurement team is going to ask whether the vendor:
- Monitors access
- Reviews permissions
- Has a working incident-response plan
- Separates production and non-production data
- Logs changes to the pipeline
A responsible data infrastructure lines up naturally with SOC 2 and ISO standards. You don’t “add” these controls later. They match the way you already handle data.
HIPAA-aligned practices for skills, roles, and employment-related data (even when HIPAA doesn’t formally apply)
Most job-market data is not medical data, so HIPAA does not technically apply. But the spirit of HIPAA — strict boundaries, need-to-know access, and minimization — is still relevant when you are handling labor trends, skill clusters, or any dataset that touches job categories tied to healthcare roles.
A responsible pipeline applies the same idea: if a field is not needed, it doesn’t stay; if access is not necessary, it isn’t granted. Even when HIPAA isn’t a legal requirement, HIPAA-aligned practices lower risk and make procurement conversations with enterprise healthcare clients simpler.
Why compliance only works when it’s built into the data infrastructure, not written in policy slides
Every vendor claims to be compliant. The difference is whether those rules live at the source, in code, and in the pipeline — or if they live in a PDF nobody reads.
In a responsible data infrastructure:
- Compliance is enforced at ingestion, not retrofitted.
- Data that shouldn’t exist in the environment never enters the environment.
- Usage rules are encoded, not negotiated case-by-case.
- If regulations change, the controls change along with them.
That’s the part that reduces risk for HR and people analytics teams. You’re not relying on one person to make the right call every time. The system itself keeps you aligned.
How JobsPikr Builds Responsible, Compliant Data infrastructure Into every Stage of its Product
Most vendors talk about compliance once the data is already inside their platform. JobsPikr approaches it differently. We designed our entire workflow around the idea that the way data enters the system matters just as much as the insight it eventually produces.
If you use JobsPikr for labor-market analytics, you’re not working with an improvised pipeline held together with scripts. You’re working with a data environment built to stand up to procurement reviews, security audits, and the kinds of questions HR leaders and compliance teams ask today:
- Where did this data come from?
- Are we allowed to use it?
- Who can see what?
- What happens when something changes?
Below is a straightforward look at how the pieces fit together.
Transparent sourcing: no mystery feeds, no grey zones, no guesswork
JobsPikr sources workforce and job-market data from clearly defined, publicly accessible locations — company career sites, standardized feeds, and structured job boards.
There are no backdoor sources, no scraping of personal profiles, no aggregations built from unclear origins.
For each source, we document:
- what data is collected
- under what terms
- when those terms were last reviewed
- how changes get flagged
This means if your security team asks for a source inventory, you get an actual list — not “we’ll get back to you.”
Transparency is the foundation of responsible data. If you can’t point to the origin of a dataset, you can’t defend its use later.
Ingestion rules that filter out fields with compliance or privacy risk
Most job posts contain clean, structured fields. But occasionally, a company will include an email address, a recruiter’s personal number, or details that should not be stored.
In a fragile pipeline, all of that slips through.
In our pipeline, it doesn’t.
JobsPikr’s ingestion layer automatically removes fields that fall outside acceptable use, flags anything unusual, and blocks data categories that aren’t relevant to workforce analytics. These rules are encoded directly into the system, so we’re not depending on manual checks or “someone should monitor that.”
This keeps your downstream environment clean — not because someone cleaned it later, but because it never entered in the first place.
Normalization and deduplication make external labor data usable without distortion
Job-market data is inconsistent by nature. One company writes “Sr. SWE,” another writes “Senior Software Engineer,” another writes “Backend Engineer (Level 3).”
JobsPikr standardizes titles, formats locations, reconciles company names, and removes duplicates to avoid inflating demand signals.
This matters because your analytics depend on it. If three duplicate job posts slip through, your “engineering demand in Mumbai” chart goes from accurate to misleading. If inconsistent titles aren’t mapped, your skills model pulls the wrong signals.
Normalization isn’t a cosmetic step. It’s what makes your insights real.
Governance designed around how HR and analytics teams actually work
JobsPikr doesn’t treat access control as a checkbox. We design governance around real workflows.
For example:
- Analysts may need granular fields for modelling, but they don’t need every raw artifact.
- Business users only see cleaned datasets and aggregated trends.
- Export permissions are logged and tied to specific roles.
- No environment has more access than it needs — production is isolated from development and staging.
These controls mean you’re not relying on “trust.” You’re relying on structure.
Anonymization and minimization for a smaller, safer data footprint
JobsPikr intentionally stores less than many vendors. We don’t need personal identifiers to understand workforce trends, and neither do you.
So we don’t keep them.
Data that could point back to a specific person is removed before storage. Unnecessary fields are dropped at the pipeline level. Retention rules ensure data doesn’t linger indefinitely. This gives clients peace of mind and gives procurement teams a reason to approve us faster.
Minimization reduces your exposure without reducing insight. That’s the trade-off everyone should be making.
Security woven into everyday operations, not layered on top
You’ll see encryption, secure storage, and industry-standard controls at JobsPikr, but the part that matters most is how they operate day-to-day.
In practical terms, that means:
- Monitoring for unusual queries or access patterns
- Periodic reviews of user permissions
- Controlled environments for testing vs. production
- Logged ingestion events and transformations
- System alerts when sources or formats change unexpectedly
These are the things that catch issues before they become problems — not six months after someone notices a strange number in a dashboard.
Compliance that updates as regulations evolve, not once a year
GDPR, CCPA, and regional rules shift constantly. Instead of relying on yearly policy reviews, JobsPikr’s compliance guardrails live inside the pipeline. If a source changes its terms, the pipeline reacts. If regulations tighten in a region, the affected fields are filtered or restricted.
It’s not about chasing rules.
It’s about building a system that adapts without chaos.
Why a Responsible Data Infrastructure Is the Foundation for Trustworthy AI in HR and Talent Intelligence
If you’re building models on top of workforce or job-market data, the quality of those models has almost nothing to do with the algorithm you pick. It comes down to the data you feed them.
People often talk about “garbage in, garbage out.” It’s worse than that. If your data pipeline has blind spots — messy sourcing, inconsistent formats, fields you shouldn’t be storing — you don’t just get bad predictions. You get predictions you can’t defend.
That’s why a responsible and compliant data infrastructure matters so much in AI. Here’s how it shows up in the real world.
Stronger data foundations mean models learn from the right signals, not noise
Most job-market datasets contain noise: outdated roles, duplicate postings, inconsistent skill labels, and job descriptions that look structured but aren’t. If these issues slip into your training data, your model doesn’t “average out” the errors. It absorbs them.
A responsible data infrastructure reduces this risk by cleaning the data before it ever hits your model:
- Titles are standardized, so a model doesn’t think “SDET” and “QA Engineer” are unrelated roles.
- Duplicates are removed, so hiring spikes aren’t exaggerated.
- Locations are normalized, so “NYC,” “New York,” and “Manhattan” don’t get treated as separate job markets.
The result is simple: you train on reality, not chaos.
Compliance guardrails stop AI from learning patterns you were never allowed to store
AI systems will happily learn from anything you give them. “Allowed to use” and “available to use” are not the same thing.
If your pipeline allows personal data, contact information, or other high-risk fields to enter your environment, your models absorb them. Even if those fields aren’t in your final table, the model has already seen them. That’s a regulatory problem waiting to happen.
JobsPikr avoids this by blocking restricted fields at ingestion. If the pipeline never sees those fields, your model never does either. This is the safest way to keep AI aligned with GDPR, CCPA, and data-security expectations.
Better lineage makes debugging AI issues easier and faster
When a model behaves strangely, you usually don’t start by looking at the model. You start by asking: “What changed upstream?”
Most teams can’t answer that cleanly. They don’t know:
- when a source changed its formatting
- when a new location pattern appeared
- when a field suddenly vanished
- when duplicates spiked
A responsible data infrastructure logs these changes and makes them visible.
These turns debugging into a conversation with evidence, not guesswork.
If something looks off — a spike, a drop, a shift in patterns — you can go straight to the pipeline and see what changed.
Fairness and bias checks only work when the underlying data is consistent
HR-related models (attrition, time-to-hire, job matching, skills gap mapping) get judged not just on accuracy, but fairness.
If job-market data is messy, incomplete, or unevenly represented, your model will reflect those distortions. It doesn’t matter how careful you are in the modelling notebook — if the pipeline is uneven, the outputs will be too.
A responsible data infrastructure minimizes this by:
- standardizing role families
- mapping skills consistently
- cleaning outdated or irregular postings
- enforcing the same rules across all sources
Fairness starts with data consistency, not model code.
AI teams move faster when the data infrastructure removes uncertainty
One of the biggest slowdowns in HR analytics and AI is not the modelling process — it’s the “do we trust this dataset?” conversation.
If every experiment requires checking whether a dataset is compliant, clean, and permitted, your team spends more time validating inputs than building outputs.
A responsible data infrastructure removes that friction.
Your team knows:
- what the data is
- where it came from
- what rules it passed
- what it contains and what it doesn’t
This lets AI teams ship in weeks, not quarters, because they’re not re-auditing every dataset from scratch.
The Business Value of Responsible Data Infrastructure: Why HR leaders Trust it and Why Enterprises Require It
When people talk about data infrastructure, the conversation often drifts into technical details. But the real impact shows up somewhere else: in how smoothly your org can use the data, how confidently leadership signs off on it, and how much friction disappears from your analytics workflow.
For HR and people analytics teams, responsible data infrastructure does three things: it lowers risk, improves decision quality, and speeds up adoption. And each of those has a very real business impact.
It reduces compliance risk before it lands on legal or security’s desk
The biggest value is also the simplest: you avoid the late-stage “we can’t use this” moment.
Every HR leader has experienced the scramble — the model is done, the dashboard is ready, the business case is strong, and then someone in legal or security asks a basic question the data pipeline can’t answer:
“Where did this data come from?”
“Do we have the right to store it?”
“Why do we have these fields?”
“Who has access to this table?”
A responsible infrastructure avoids those setbacks entirely because the answers already exist. You’re not retrofitting documentation or scrambling to justify decisions made months ago. You’re walking into the meeting with the groundwork done.
This is why procurement teams approve vendors like us faster — the risk is smaller and easier to understand.
It gives HR teams cleaner, more reliable labor-market signals
When your job-market data is stable, structured, and consistent across sources, you stop wasting cycles trying to figure out whether the insight is real or an artifact of messy data.
This matters for everyday decisions like:
- Where to open a new role
- Whether competitors are ramping up hiring in a region
- Which skills are rising in demand
- Which markets show saturation or decline
Instead of asking, “Is this signal accurate?” your team can ask, “What do we want to do about it?”
The difference is night and day.
It creates confidence inside the organization, especially with leaders who treat people’s data cautiously
HR data carries a different weight than sales or marketing data. It touches hiring, pay, promotion, and workforce planning. Leaders approach it with more scrutiny, not less.
A responsible data infrastructure changes the tone of those conversations. When you can show:
- where the data comes from
- why it’s allowed to be used
- how it’s been cleaned
- what the governance looks like
you move discussions away from fear and towards strategy. Leadership becomes more comfortable using external labor data because the foundations are clear and defensible.
This is often the turning point where organizations finally start using people analytics to guide long-term planning instead of relying on gut instinct.
It opens the door for predictive models and deeper workforce intelligence
Most HR teams want to build stronger forecasting capabilities — hiring forecasts, skill-gap models, role maturity curves, supply–demand maps. But the main reason these projects stall is not modelling. It’s data uncertainty.
When the infrastructure is solid, predictive work becomes possible:
- Talent supply models stop overreacting to duplicated postings
- Time-to-hire predictions stop learning from stale data
- Attrition-risk models stop reflecting noisy job-market spikes
- Skill taxonomies update smoothly instead of breaking workflows
You’re no longer fighting your pipeline. You’re working with it.
This lets data science teams build useful models instead of guarding against inconsistent inputs.
It makes scaling easier because you aren’t rebuilding your process every time you expand
The moment you add new geographies, new role families, or new data sources, a weak infrastructure starts to crack. You get more noise, more outliers, more inconsistencies.
A responsible foundation handles growth naturally. You can add new countries, industries, or regions without rewriting half your logic. The same rules apply everywhere — sourcing, cleaning, mapping, governance, and quality checks.
This saves months of engineering and re-work as your people analytics footprint expands.
It strengthens trust with customers, investors, and employees
Every organization is now judged on how it handles data. Boards ask. Candidates ask. Investors ask. If a vendor or internal team cannot explain their data practices, it becomes a reputational risk.
A responsible data infrastructure signals something important: this team takes accuracy, legality, and safety seriously. It shows up in audits, RFP responses, and stakeholder conversations.
It’s not a selling point. It’s a trust point.
The Responsible Data Lifecycle: A Step-by-Step View of How the Pipeline Works
Most teams only see the final dataset — the clean tables, the standardized fields, the dashboards that sit on top. The real work happens long before that. A responsible and compliant data infrastructure isn’t one big switch you turn on. It’s a sequence of stages, each one designed to prevent issues before they spread downstream.
Here’s how that lifecycle works inside JobsPikr, from the moment a job posting appears online to the moment it becomes a usable, compliance-safe insight.
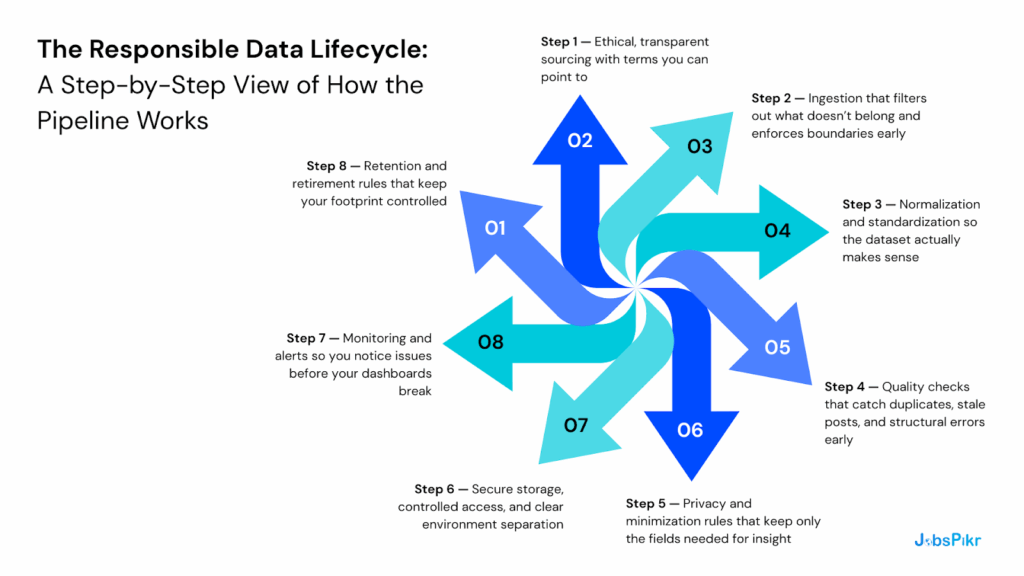
Step 1 — Ethical, transparent sourcing with terms you can point to
Everything starts with sourcing. JobsPikr only collects from locations that clearly allow access: company career sites, public job boards, and structured feeds that are designed to share job-market information.
For every source, we keep:
- the access method,
- the terms of use,
- the data categories we extract, and
- notes on what we do not collect from that location.
This isn’t paperwork for auditors. It’s what lets you answer a simple question with confidence: “Where does this data actually come from?” When your leadership team asks — and they will — you have clarity, not assumptions.
Step 2 — Ingestion that filters out what doesn’t belong and enforces boundaries early
Once a posting is collected, the first pass is not about structuring the data — it’s about filtering out anything that shouldn’t exist in your environment in the first place.
This includes:
- personal contact details that occasionally appear in job ads,
- fields that could point back to a named individual,
- categories the source terms allow you to view but not store,
- and any irregular or unexpected data that does not align with the allowed schema.
Because this happens at ingestion, not later, you never end up with restricted data hiding inside a table by accident. The safest field is the field that never enters your system.
Step 3 — Normalization and standardization so the dataset actually makes sense
The next stage is the part most people underestimate: standardizing messy job data so it behaves like a structured dataset instead of a patchwork of formats.
This covers things like:
- converting “Sr. SWE” / “Senior Software Eng.” / “Backend Engineer L3” into a consistent title,
- mapping locations cleanly across cities, metros, regions, and countries,
- reconciling company names that appear in multiple forms,
- and aligning job families and skill categories so you can make apples-to-apples comparisons.
Without this step, job-market analysis becomes guesswork. With it, trends become dependable — and your org can act on them.
Step 4 — Quality checks that catch duplicates, stale posts, and structural errors early
Workforce data has quirks: companies sometimes post the same job multiple times, update it without changing the date, or leave outdated vacancies online.
JobsPikr’s pipeline flags:
- duplicates (even if they’re not exact text matches),
- stale or expired postings,
- malformed or structurally inconsistent job ads,
- and sudden source anomalies (for example, a career site switching formats overnight).
These checks are logged, so if someone asks, “Why does our hiring-demand chart look different this month?” you can point to real events in the data, not guess at them.
Step 5 — Privacy and minimization rules that keep only the fields needed for insight
A responsible infrastructure doesn’t keep everything “just in case.” It keeps only what adds value and aligns with compliant use.
We remove:
- personal identifiers,
- recruiter details,
- unnecessary metadata,
- anything that increases risk without improving analysis.
This creates a smaller, cleaner, safer dataset. It also makes procurement conversations easier, because you’re not bringing sensitive data into the organization at all.
Step 6 — Secure storage, controlled access, and clear environment separation
Once the data is cleaned and minimized, it enters the storage layer — but with strict structure.
- Production, staging, and development are separated.
- Access is permission-based, not “everyone can see everything.”
- Sensitive fields are isolated and masked.
- Exports and queries are logged.
The idea is simple: if someone ever asks, “Who accessed this data and when?” you have a real answer.
Step 7 — Monitoring and alerts so you notice issues before your dashboards break
The pipeline watches itself.
Examples of what gets flagged:
- source formats changing unexpectedly,
- unusual spikes in volume (which could be a source issue, not a market shift),
- Repeated ingestion failures,
- or an abnormal increase in duplicates or malformed data.
This is what prevents surprises: you’re not discovering issues weeks later when a report looks “off.” You’re seeing them as they happen
Step 8 — Retention and retirement rules that keep your footprint controlled
Finally, data doesn’t stay forever. JobsPikr retires older batches based on retention windows, regulatory expectations, and usage patterns.
If a dataset no longer serves a purpose, it’s removed — securely and intentionally.
It keeps your environment light, compliant, and easier to manage.
The Questions HR and People-Analytics Teams Raise Once They Look Past the Dashboard
At some point in every evaluation, the conversation shifts. It’s no longer “What does the dashboard show?” but “What sits underneath it?” These are the questions that actually matter when you’re bringing workforce data into an enterprise environment — especially one with legal, security, and compliance teams watching closely.
Here’s how those questions typically surface, and what they reveal about the strength of your data foundation.
What actually separates responsible data infrastructure from a pipeline that’s merely ‘secure’?
Security is about protection. Responsibility is about intention.
A secure pipeline keeps intruders out. A responsible pipeline makes sure you’re not storing things you shouldn’t have in the first place.
When HR leaders ask this, what they’re really looking for is whether the vendor can explain:
- why the data is collected,
- what decisions led to keeping or discarding certain fields,
- and whether those choices align with regulations and internal risk expectations.
It’s not a technical distinction — it’s an operational one. You can encrypt a dataset and still have no business storing half the fields inside it. A responsible setup prevents that long before encryption becomes relevant.
How do we know the dataset we’re using actually aligns with GDPR, CCPA, or regional rules?
This question doesn’t mean teams want a wall of legal text. They want to know if compliance is a continuous part of the pipeline or something the vendor checks once and hopes doesn’t change.
A dataset is compliant when:
- fields that shouldn’t be collected never reach storage,
- source terms are monitored and enforced automatically,
- Retention rules remove older data without human intervention,
- and changes in the regulatory landscape trigger updates in the ingestion logic.
When people ask this question, they’re testing whether the infrastructure adapts — because job-market data sources change constantly, and compliance has to keep up.
Will all this governance and control slow us down when we want to move fast?
This fear is common and understandable — governance has a reputation for slowing things down. But in practice, the opposite is true.
Teams with weak data foundations spend more time fixing issues than analyzing trends. They lose cycles debating whether a dataset is trustworthy or whether a spike came from the market or from duplication.
A responsible infrastructure solves all of that upstream.
So when someone asks this question, what they really want to know is whether the vendor has built a system that reduces rework. The fastest teams aren’t the ones skipping governance — they’re the ones who never have to redo the basics.
Can a responsible data infrastructure still support large-scale AI and modelling without restricting us?
The people asking this are really asking whether “responsible” means “constraining.”
What they discover is that models built on sloppy pipelines cause the real constraints:
unexpected shifts, unexplained anomalies, data drifts, duplicated inputs, and retrieval inconsistencies.
Responsible infrastructure removes those constraints by giving models a stable, predictable foundation. It doesn’t slow AI down — it stabilizes it.
Anyone who has debugged a broken model knows the difference instantly.
Why is anonymization treated as a core design choice, not an optional filter?
This question tends to come from people close to risk and compliance. They know that the safest data is the data you never collected in the first place.
In workforce analytics, you don’t need personal identities to understand hiring behavior, skills trends, or job-market movement. So anonymization becomes a structural choice: strip away anything that adds risk without adding insight.
When leaders ask this, they’re checking whether the vendor treats minimization seriously — or treats it like a post-processing step tacked on at the end.
Why Responsible Data Infrastructure Defines the Future of Workforce Intelligence
If there’s one thing the last few years have made clear, it’s that you cannot separate “insight quality” from “data responsibility.” The days of collecting everything, storing everything, and worrying about governance later are gone — especially in HR and workforce analytics, where the stakes are higher and the data environment is more heavily scrutinized.
A responsible data infrastructure does something simple but powerful: it lets teams use external labor data without feeling like they’re stepping into a grey zone. You know where the data came from. You know what rules it passed. You know why it’s safe to use. And when someone asks for the story behind an insight, you can actually tell it — not scramble to reconstruct it.
That clarity changes how people analytics teams work. It removes hesitation. It lowers risk. It makes leadership more confident in the dashboards and models they’re signing off on. And as organizations lean more heavily on AI to guide decisions about hiring, skills, talent supply, and workforce planning, that foundation becomes non-negotiable.
JobsPikr’s approach is built around that idea: the infrastructure matters as much as the insight. When the pipeline is responsible by design — from sourcing to storage to governance — you end up with intelligence that’s not only accurate, but defensible. And in a world where every model, chart, and dataset will eventually be questioned, defensible insights are the ones that survive.
If you want to see how this works in practice — not in theory — we can walk you through the actual pipeline, the controls behind it, and how enterprises use JobsPikr to get clean, compliant labor-market intelligence without the operational drag.
Ready to See Responsible & Compliant Data Infrastructure in Action?
Explore real labor-market datasets sourced, governed, and processed through JobsPikr’s compliance-first pipeline to understand the depth and quality behind every signal.
FAQs:
1. What is data infrastructure in the context of HR and workforce analytics?
When people talk about “data infrastructure” in HR, they’re referring to everything that happens before you ever build a dashboard: how the data is sourced, what’s filtered out, how it’s stored, and who can touch which fields inside your systems. With workforce and job-market data, good infrastructure ensures the signals you’re using — hiring trends, skills demand, labor supply — come from compliant, well-governed, and transparent sources. Without that layer, even the best analytics platform can only give you shaky conclusions.
2. What makes data infrastructure responsible rather than just technically secure?
Technical security focuses on protection — encryption, access control, and secure storage. Responsible data goes further. It asks whether you should be collecting and keeping certain fields at all. It enforces minimization, removes unnecessary identifiers, respects source terms, and makes sure the pipeline only carries data that’s legal to store and appropriate to analyze. A system can be secure and still non-compliant. A responsible data infrastructure prevents that problem before it starts
3. How does a compliant data infrastructure reduce risk for enterprises using job-market data?
A compliant infrastructure limits risk by enforcing rules at the point of collection: dropping fields that violate GDPR or CCPA expectations, filtering out anything that points back to individuals, and applying retention policies automatically. This means you’re not relying on hopeful assumptions or manual reviews. It also makes procurement and legal teams far more comfortable approving a new vendor, because they can see the guardrails instead of taking them on faith.
4. Does a responsible data infrastructure slow down analytics, modelling, or AI work?
No. In fact, the opposite is true. Teams that don’t have a responsible data setup end up fighting upstream problems — duplicates, inconsistencies, unclear sources, questionable fields, and constantly shifting formats. That slows down modelling, slows down forecasts, and slows down reporting. A responsible pipeline removes that friction so AI teams and analysts can work faster because the messy, risky parts of the process are already handled
5. What is the advantage of anonymization and minimization in compliant data workflows?
Anonymization and minimization keep your data footprint clean and your risk footprint small. For workforce analytics, you rarely need personal identifiers — trends in hiring, demand, skills, locations, and roles don’t depend on who a specific individual is. When the pipeline strips away personal details before storage, you reduce compliance complexity, avoid unnecessary exposure, and make your datasets easier to defend inside the organization. It’s a structural win, not a cosmetic one.




