
- Natural Language Processing and its role in CV Parsing
- Machine Learning Algorithms and Libraries
- Cloud-Based Resume Parsing Solutions: Ensuring Security and Efficiency in Managing Candidate Data
- Benefits of using Intelligent CV parsing software
- From Unstructured to Structured: How Resume Parsers Feed Your ATS
- Popular Intelligent Resume Parsers
- Conclusion
CV or resume parsers have seen growing usage and acceptance in recent times thanks to the benefits they add to traditional resume sorting processes. Machine Learning and NLP-based tools have also improved the accuracy of resume parsers– thus increasing the usage of these tools by new companies or hiring agencies.
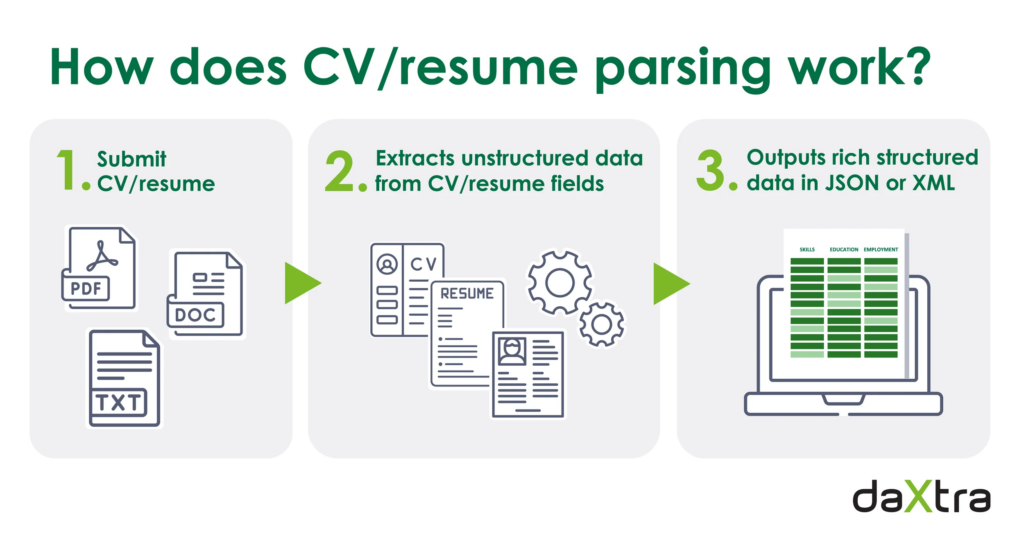
Image Source: https://info.daxtra.com/
In simple terms, resume parsers just convert unstructured data to structured data and store it in Applicant Tracking Systems, to be used by recruiters. It reduces manual effort as well as chances of error. Data is updated and stored in real-time, and since no human intervention is required, the system can run 24×7. Whenever a new applicant sends his or her resume, it can be parsed, and the data extracted can be stored in an appropriate database. Resume parsers not only format the data but also help paint a picture of each candidate by automatically generating a small summary for every individual.
Resume parsers also help us easily identify metadata– information about data. For example, if an individual is well versed in Python– that is data. How long has the applicant been using Python, in how many companies has he or she used the language– these are metadata that are often extracted using intelligent CV parsing tools.
Natural Language Processing and its role in CV Parsing
Natural language like speech or text does not always follow strict rules of grammar. Hence, the parsing of this text also cannot be solely dependent on some rigid rules and configurations. This is because the spoken language changes from place to place due to cultural changes and lingual shifts.
For instance, even though English is spoken in both the USA and the UK, the format and structure are different in both places. If you used data only from US text to train a model and then run it on text from the UK, the results will contain a large amount of error.
Different types of text follow different formats. For example, menu cards at restaurants, or marriage invitations, or professional emails follow specific formats that are unique to them. CVs or Resumes also follow a unique format– the formats may vary based on sector, type of job, region, and more, but a general outline with certain subheadings and data points is still followed.
Natural Language Processing deals not just with words in a text, but with the context of the text, by comparing which words are used together, negative or positive words, special characters, and more. Since resumes are a lot more structured than emails or just a blob of text, and it is known beforehand which data points we are expecting to find, using NLP to process CVs, is much easier and produces pretty accurate results.
Machine Learning Algorithms and Libraries
Due to the availability of multiple 3rd party libraries in Python, it is the preferred language for Developers to create Intelligent tools for text parsing. The top libraries that are commonly used are:
- NLTK: Easily the most popular library for NLP-based development. This library provides easy to use functions to
- Tokenize text by sentences or words
- Create a parsed tree from a text
- Text-classification
- Find the frequency distribution of words
- Remove stopwords from text
- Tagging words with parts of speech, and more.
- TextBlob: It is a simple library that can be used for tasks such as noun-phrase extraction, sentiment analysis, classification of text, translation, and other common NLP-based functionalities. It even offers a “correct()” method that can be used to correct mistakes in the text.
| >>> b = TextBlob(“I havv goood speling!”) >>> print(b.correct()) I have good spelling! |
- spaCy: With support for more than 64 languages, it offers pre-trained transformers like BERT. It is an industrial-grade NLP library that specifically provides you with the power to develop production-ready systems. You can also create custom models in Tensorflow, Pycharm, or other frameworks using spaCy.
Cloud-Based Resume Parsing Solutions: Ensuring Security and Efficiency in Managing Candidate Data
Modern recruitment relies heavily on handling vast amounts of candidate data securely and efficiently. That’s where cloud-based resume parsers excel. They provide numerous benefits, such as increased scalability, cost savings, and simplified setup.
More importantly, cloud-based parsing solutions emphasize data protection by incorporating robust security measures, complying with various regulations, and offering seamless integration with leading applicant tracking systems (ATS). Organizations leveraging these services can rest assured that candidate data remains confidential while improving recruitment pipelines.
Benefits of using Intelligent CV parsing software
The benefits of using intelligent resume parsers are manifold. You would be able to parse thousands of resumes automatically and extract the major data points from them. Most resume parsers also allow you to save this extracted information in a proper format such as CSV or save it to a database, which would be accessible via an API.
Once the parsing is complete, you would have other tools at your disposal to rank the candidates based on multiple factors– depending on what you deem most important. If work experience matters most for a position, that can have the highest score; if coding experience in a certain language is a must for a job, that can be used as a filter– all of this can be done on the parsed data to help the recruiter narrow down the options at hand.
Both time and complexity are reduced with the help of CV parsing software when hiring candidates for roles with specific requirements and good-to-haves. Most resume parsers have integration with ATS (Applicant Tracking Software) tools as well, to ensure a seamless process of evaluating job applicants.
From Unstructured to Structured: How Resume Parsers Feed Your ATS
Transforming unstructured candidate data into structured formats lies at the heart of effective recruitment processes. Thanks to innovations in NLP and ML technologies, automated resume parsers achieve precisely that, turning raw text into valuable insights. Mapped data points include contact info, education, skills, employment dates, and more – providing hiring managers with comprehensive and searchable profiles.
Combining these capabilities with Applicant Tracking System platforms yields powerful search functionality, productivity improvements, and streamlined interview scheduling. Ultimately, synergistic interactions between the resume parser and Applicant Tracking System result in superior recruitment outcomes.
Popular Intelligent Resume Parsers

Sovren: This one is a cloud-based SaaS provider that parses your resumes on the go. It doesn’t store any data and ensures end-to-end security. It claims to parse most resumes under half a second while producing 10 times fewer errors than other Resume Parsing Software. An interesting feature that it advertises is that it sends an anonymized copy of every resume to you where all identity details are removed so that filtering and shortlisting of candidates can be done without any unintended bias. This would help the hiring be majorly fact and merit-based.
Affinda: An enterprise-grade resume parsing API, it can parse resumes in 56 different languages like English, Italian, Russian, Hindi, and German. It can be used to a) populate candidate profiles, b) screen profiles, and c) search an applicant database. It uses proprietary technology to extract more than 100 fields per resume. These include:
- Personal Details
- Work Details
- Education
- Certifications
- Skills
- Summary
- Language
- References and Publications
Zappyhire: Zappyhire is a resume parsing tool that allows you to configure specific filters, that would help match candidates to job posts better. It looks beyond keywords and uses contextual information from resumes to judge them or rank them. It generates a summary from each resume so that consumption by the HR recruiter is easier. Deep Learning is used in this tool that is empowered by Named Entity Recognition (NER) for up to 93% accurate information extraction.
Skillate: Based on the results of parsing thousands of resumes, Skillate promises accuracy of 90% on even the most complicated resumes. It breaks the problem statement into two stages:
- Text Extraction, and
- Information Extraction.
Every resume is parsed differently by Skillate, and no fixed template is followed. This helps the tool to extract vital data points no matter what the format of the data.
SmartRecruiters: This is a smart recruiting tool that enables companies to move from manual recruiting workflows to intelligent recruiting. Using their Smart-Assistant, you can scan hundreds of resumes together. You can also automatically match profiles in your existing database with new job posts that open up. An in-depth and digestible review of applicants is provided along with highlights and a profile score.
CV or resume parsers make the lives of recruiters easier and help ensure better efficiency in the hiring department. It also gives companies a better hand to filter through thousands of applicants and find the ones that would be the best cultural and technical fit. With the advent of new algorithms, NLP libraries, and faster GPUs, this technology will be adopted by more and more companies in order to tide over “The Great Resignation”, as well as to fill up vacant positions later on.
Conclusion
In conclusion, resume parsers powered by machine learning have transformed the hiring process by making it faster, more efficient, and data-driven. These tools not only save time for recruiters but also enhance candidate matching by accurately analyzing resumes and extracting relevant skills and qualifications. As the job market becomes increasingly competitive, businesses adopting machine learning-based resume parsers will be better equipped to identify top talent and streamline their recruitment efforts. Embracing this technology is key to staying ahead in a dynamic, talent-driven economy. Sign-up with JobsPikr now.




