
- What is Data Redundancy?
- What is The Impact of Data Redundancy on Recruitment Databases?
- Types of Data Redundancy in Recruitment Databases
- What Causes Data Redundancy in Recruitment Databases?
- Consequences of Data Redundancy in Recruitment
- How to Prevent Data Redundancy in Recruitment Databases?
- Data Normalization Techniques
- Why Are Regular Backups Necessary?
- Future Trends: AI and Machine Learning in Data Management
- Conclusion
What is Data Redundancy?
Data redundancy refers to the occurrence of duplicate data within a database. This phenomenon arises when the same piece of information is stored in multiple locations, leading to inefficiencies and potential inconsistencies.
In recruitment databases, data redundancy can manifest in several ways, such as duplicate candidate records, identical job listings, or redundant employer details. This results in increased storage costs complicates data management, and poses challenges for accurate data retrieval and reporting. Moreover, inconsistent duplicate entries can undermine the integrity and reliability of the database, ultimately affecting decision-making processes.
What is The Impact of Data Redundancy on Recruitment Databases?
Data redundancy in recruitment databases leads to several detrimental effects. First, it increases storage costs as duplicate records use more disk space. Second, it complicates data management, making it harder to ensure data accuracy and consistency. Third, it slows down database performance, affecting retrieval times.
Fourth, it can lead to inconsistent applicant evaluations when the same candidate appears multiple times under different records. Finally, it poses compliance risks, as maintaining redundant data might violate data protection regulations. Therefore, minimizing redundancy is critical for efficient database management in recruitment.
Types of Data Redundancy in Recruitment Databases
Data redundancy can disrupt operations and lead to inefficiencies. It generally manifests in several forms:
- Direct Redundancy:
- Repeated storage of identical candidate records.
- Derived Redundancy:
- Information derived from other data repeatedly entered, such as the same qualification details in multiple fields.
- Inadvertent Redundancy:
- Unintended duplicates arising from data entry errors or batch imports.
- Cycle Redundancy:
- Data loops where information references itself needlessly, causing storage bloat.
What Causes Data Redundancy in Recruitment Databases?
Data redundancy in recruitment databases primarily arises from multiple factors including:
- Repeated Data Entry: When recruiters or HR personnel enter the same candidate information multiple times.
- Lack of Centralized Database: The absence of a unified system can lead to different departments maintaining separate records.
- Inconsistent Data Management: Differing practices and standards for data entry across teams.
- Duplicate Candidate Profiles: Multiple profiles for the same candidate due to varied sourcing channels.
- Integration Issues: Poor integration between recruitment software and other HR systems.
These factors contribute significantly to data redundancy, complicating database management and increasing storage costs.
Consequences of Data Redundancy in Recruitment
Data redundancy in recruitment can lead to several significant issues. Firstly, it incurs unnecessary storage costs due to duplicate data entries. Additionally, it hampers search efficiency, causing delays in retrieving relevant and accurate job data.
The redundancy can lead to inconsistencies in candidate profiles, making it difficult to maintain accurate records. Moreover, it complicates data maintenance and updates, leading to increased administrative workload.
The duplication also poses challenges to compliance with data protection regulations, as managing multiple copies of the same data increases the risk of breaches. Lastly, it impacts analytical accuracy, skewing reporting and decision-making processes.
Image Source: Unstop
How to Prevent Data Redundancy in Recruitment Databases?
Data redundancy can lead to duplicative efforts, increased storage costs, and inconsistent records. Ensuring data integrity is crucial for seamless operations.
- Normalize the Database: Structure the database into tables and relationships to avoid duplicate data entries.
- Implement a Unique Candidate ID: Assign unique identifiers to each candidate to prevent multiple entries of the same candidate.
- Regular Audits: Conduct routine audits to identify and merge duplicate records.
- Automate Data Entry: Utilize software tools to automate and streamline data entry processes.
- Update Policies: Enforce strict data entry protocols and guidelines for recruiters to follow.
Data Normalization Techniques
Data normalization is crucial in reducing redundancy and maintaining database efficiency. By organizing data into structured tables, normalization eliminates data anomalies and ensures consistency. Key techniques include:
- First Normal Form (1NF): Ensures each column contains atomic, indivisible data points.
- Second Normal Form (2NF): Removes partial dependencies by ensuring all non-key attributes are fully functional dependent on the primary key.
- Third Normal Form (3NF): Eliminates transitive dependencies, ensuring non-key attributes do not depend on other non-key attributes.
These techniques help optimize the integrity and consistency of recruitment databases, facilitating better data management.
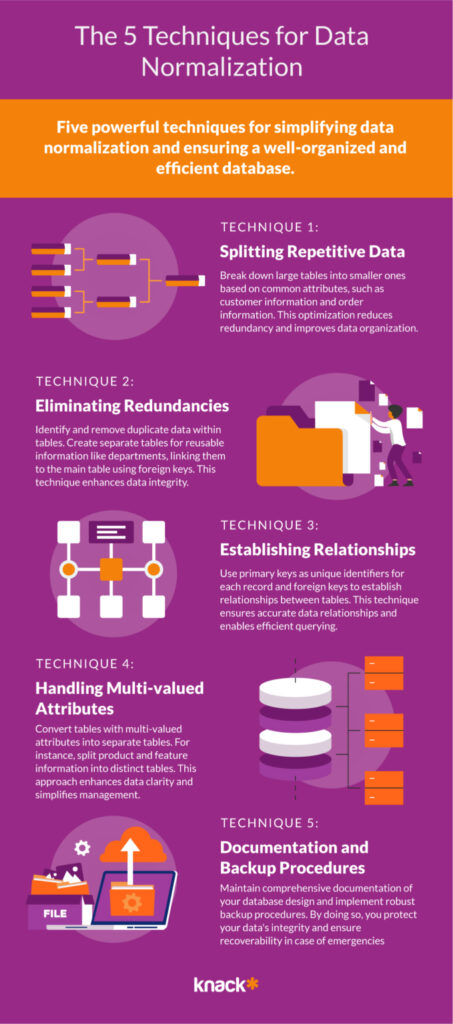
Image Source: Knack
Implementing Unique Identifiers
Implementing unique identifiers is essential in minimizing data redundancy within recruitment databases. By assigning a unique identifier, such as an applicant ID or a position code, to every entity, recruiters ensure easier data management and retrieval. This system allows for the accurate linking of candidates to job vacancies, records, and application statuses.
Unique identifiers prevent the creation of duplicate entries by cross-referencing new data entries against existing ones. Additionally, they facilitate effective data integrity checks, simplifying the detection and remediation of inconsistencies in the database. Such practices streamline operations and enhance data accuracy.
Utilizing Centralized Databases
Centralized databases consolidate data into a uniform, singular repository, simplifying data access and management. In the recruitment sector, a centralized database ensures uniformity in data entry, minimizing discrepancies. This structure reduces redundancy by eliminating the necessity for multiple data copies across disparate locations.
Centralized databases offer superior oversight capabilities, enhancing data integrity through consistent updates and standardized processes. They support advanced data analysis and reporting features, streamlined by centralized control mechanisms. A systematic approach to data integration and synchronization in a centralized database drastically mitigates redundancy risks.
Leveraging Data De-duplication Tools
Recruitment databases can benefit significantly from data de-duplication tools. These tools scan and identify duplicate records, automating the cleansing process to maintain data integrity. They minimize the risk of redundancy by adhering to predefined parameters, ensuring only unique data entries persist.
Advantages include streamlined databases, enhanced data accuracy, and improved system performance. By systematically removing duplicates, these tools save time and resources, allowing recruitment teams to focus on strategic initiatives rather than manual data management. Implementation of such tools is crucial for companies aiming to maintain efficient and effective recruitment databases.
Regular Database Audits and Clean-ups
Conducting regular database audits and clean-ups is essential for identifying and eliminating redundant data in recruitment databases. Periodic reviews enable the assessment of database entries for duplicates, inconsistencies, and outdated information. By implementing a systematic approach to audits, businesses can ensure data integrity and optimize storage efficiency. The process typically includes:
- Identifying duplicate entries
- Removing outdated or irrelevant records
- Verifying the accuracy of remaining data
- Updating records as needed
Database audits not only maintain the quality of data but also improve the overall performance and reliability of the recruitment database.
Employee Training and Awareness
Employee training and awareness play a crucial role in preventing data redundancy in recruitment. Organizations must conduct regular training sessions to educate employees about the importance of proper data entry and updating practices. These sessions should cover:
- Data management best practices.
- Techniques for accurate data entry.
- The significance of adhering to database protocols.
Additionally, employees should be made aware of the potential repercussions of data redundancy, such as inefficiencies and errors in the recruitment process. By fostering a culture of meticulous data handling, companies can significantly reduce the risk of redundant, outdated, or duplicate information in their databases.
Automating Data Quality Checks
Automating data quality checks can significantly mitigate data redundancy in recruitment databases. By employing automated systems, organizations can establish rules and algorithms that identify and rectify duplicate entries efficiently. Steps in these automated processes include:
- Data Cleaning: Automatically removing or merging duplicate records.
- Validation Rules: Ensuring new data adheres to predefined accuracy and consistency standards.
- Regular Audits: Scheduling frequent scans to detect and address potential redundancies.
Utilizing automation for these tasks not only reduces manual efforts but also enhances data integrity, thereby improving the reliability and performance of recruitment databases.
Leveraging Cloud-Based Solutions
By leveraging cloud-based solutions, recruitment professionals can effectively manage data redundancy. Cloud platforms offer scalable storage options that ensure real-time sync across multiple devices, providing a unified data source. These systems incorporate advanced backup and recovery features, minimizing the risk of data duplication.
Additionally, cloud providers employ robust security measures, safeguarding data integrity and preventing unauthorized access. The centralized nature of cloud storage simplifies data retrieval and updates, reducing redundant data entries. These solutions also facilitate collaboration among team members by providing a shared, up-to-date database, streamlining the recruitment process and enhancing efficiency.
Integrating Applicant Tracking Systems with CRM
Integrating Applicant Tracking Systems (ATS) with Customer Relationship Management (CRM) tools can substantially mitigate data redundancy in recruitment databases. By establishing seamless data synchronization between ATS and CRM, recruiters can ensure that candidate information is consistently updated across platforms.
This integration avoids duplicate entries and reduces manual data entry errors by automatically updating candidate statuses, notes, and communication histories. Furthermore, an integrated system provides a unified view of all candidate interactions, enhancing recruitment efficiency and accuracy. Companies leveraging this integration benefit from streamlined workflows, increased data accuracy, and improved candidate experience.
Why Are Regular Backups Necessary?
Regular backups play a crucial role in maintaining data integrity within recruitment databases. Backups ensure that all essential information is safe from potential threats such as system failures, cyberattacks, or accidental data loss. By implementing a routine backup schedule, organizations can:
- Minimize data loss
- Quickly restore functionality after disruptions
- Preserve historical data for audits
Such practices not only safeguard the integrity of the data but also provide peace of mind and continuity for businesses. Adopting automated backup solutions can further streamline this process, ensuring that data is consistently preserved without requiring excessive manual intervention.

Image Source: FasterCapital
Future Trends: AI and Machine Learning in Data Management
Artificial intelligence (AI) and machine learning (ML) are revolutionizing data management in recruitment databases. Automating data cleaning processes reduces redundancies and enhances data accuracy. AI algorithms identify duplicate entries, ensuring streamlined databases. Machine learning models predict potential data conflicts and offer real-time suggestions for data consolidation.
These technologies also bolster predictive analytics, aiding recruiters in forecasting trends and making data-driven decisions. With natural language processing (NLP), AI can organize unstructured data efficiently, further preventing data redundancy. In essence, AI and ML significantly enhance database integrity and operational efficiency in recruitment management systems.
Conclusion
To mitigate data redundancy in recruitment databases, leveraging an advanced data solutions tool like JobsPikr is critical. JobsPikr offers automated job data collection from numerous sources, ensuring updated and non-redundant records.
For organizations aiming to optimize their recruitment database, JobsPikr stands out as a robust solution. Explore JobsPikr’s capabilities to maintain a seamless, efficient recruitment process devoid of redundancy. Sign up today!




